 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAN-MPC: Training Model Predictive Controllers with Parameterized Cost Functions using Demonstrations from Non-identical Experts
Jun 07, 2023



Model predictive control (MPC) is a popular approach for trajectory optimization in practical robotics applications. MPC policies can optimize trajectory parameters under kinodynamic and safety constraints and provide guarantees on safety, optimality, generalizability, interpretability, and explainability. However, some behaviors are complex and it is difficult to hand-craft an MPC objective function. A special class of MPC policies called Learnable-MPC addresses this difficulty using imitation learning from expert demonstrations. However, they require the demonstrator and the imitator agents to be identical which is hard to satisfy in many real world applications of robotics. In this paper, we address the practical problem of training Learnable-MPC policies when the demonstrator and the imitator do not share the same dynamics and their state spaces may have a partial overlap. We propose a novel approach that uses a generative adversarial network (GAN) to minimize the Jensen-Shannon divergence between the state-trajectory distributions of the demonstrator and the imitator. We evaluate our approach on a variety of simulated robotics tasks of DeepMind Control suite and demonstrate the efficacy of our approach at learning the demonstrator's behavior without having to copy their actions.
A Contextual Bandit Approach for Learning to Plan in Environments with Probabilistic Goal Configurations
Nov 29, 2022



Object-goal navigation (Object-nav) entails searching, recognizing and navigating to a target object. Object-nav has been extensively studied by the Embodied-AI community, but most solutions are often restricted to considering static objects (e.g., television, fridge, etc.). We propose a modular framework for object-nav that is able to efficiently search indoor environments for not just static objects but also movable objects (e.g. fruits, glasses, phones, etc.) that frequently change their positions due to human intervention. Our contextual-bandit agent efficiently explores the environment by showing optimism in the face of uncertainty and learns a model of the likelihood of spotting different objects from each navigable location. The likelihoods are used as rewards in a weighted minimum latency solver to deduce a trajectory for the robot. We evaluate our algorithms in two simulated environments and a real-world setting, to demonstrate high sample efficiency and reliability.
On Learning to Rank Long Sequences with Contextual Bandits
Jun 07, 2021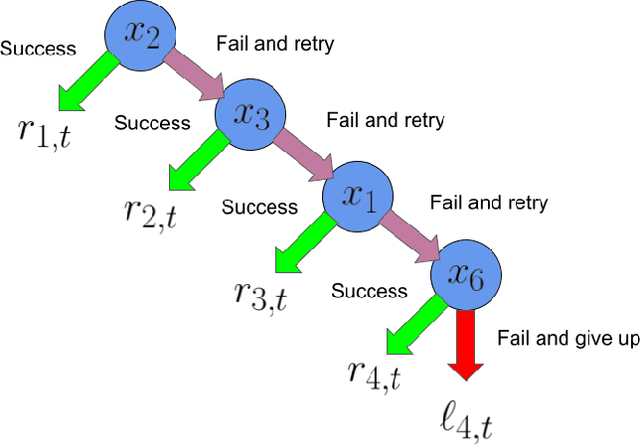
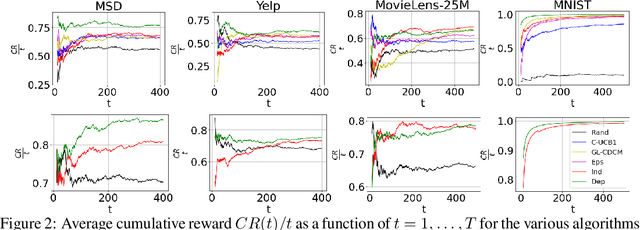
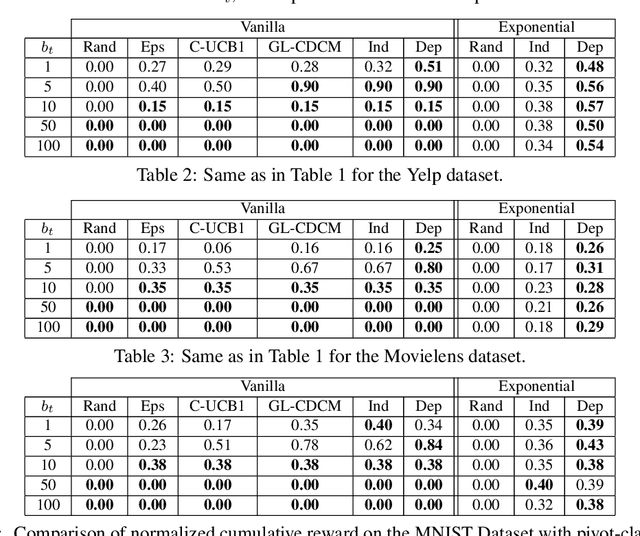
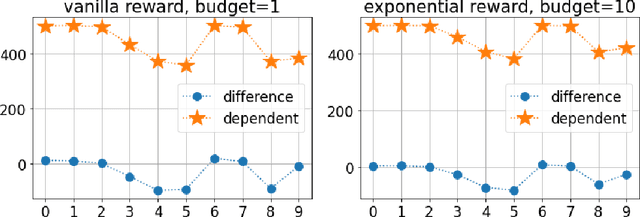
Motivated by problems of learning to rank long item sequences, we introduce a variant of the cascading bandit model that considers flexible length sequences with varying rewards and losses. We formulate two generative models for this problem within the generalized linear setting, and design and analyze upper confidence algorithms for it. Our analysis delivers tight regret bounds which, when specialized to vanilla cascading bandits, results in sharper guarantees than previously available in the literature. We evaluate our algorithms on a number of real-world datasets, and show significantly improved empirical performance as compared to known cascading bandit baselines.
Unlocking Pixels for Reinforcement Learning via Implicit Attention
Mar 04, 2021
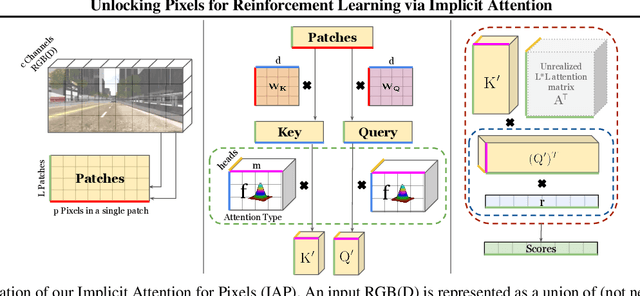

There has recently been significant interest in training reinforcement learning (RL) agents in vision-based environments. This poses many challenges, such as high dimensionality and potential for observational overfitting through spurious correlations. A promising approach to solve both of these problems is a self-attention bottleneck, which provides a simple and effective framework for learning high performing policies, even in the presence of distractions. However, due to poor scalability of attention architectures, these methods do not scale beyond low resolution visual inputs, using large patches (thus small attention matrices). In this paper we make use of new efficient attention algorithms, recently shown to be highly effective for Transformers, and demonstrate that these new techniques can be applied in the RL setting. This allows our attention-based controllers to scale to larger visual inputs, and facilitate the use of smaller patches, even individual pixels, improving generalization. In addition, we propose a new efficient algorithm approximating softmax attention with what we call hybrid random features, leveraging the theory of angular kernels. We show theoretically and empirically that hybrid random features is a promising approach when using attention for vision-based RL.
MADRaS : Multi Agent Driving Simulator
Oct 02, 2020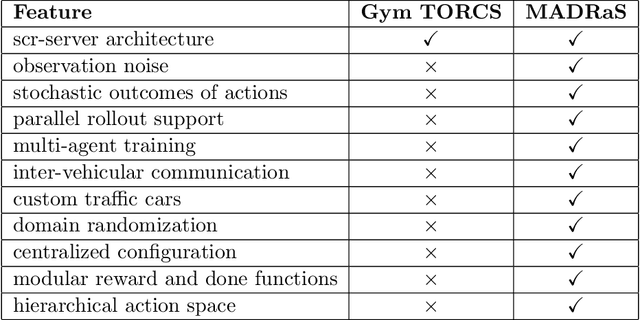
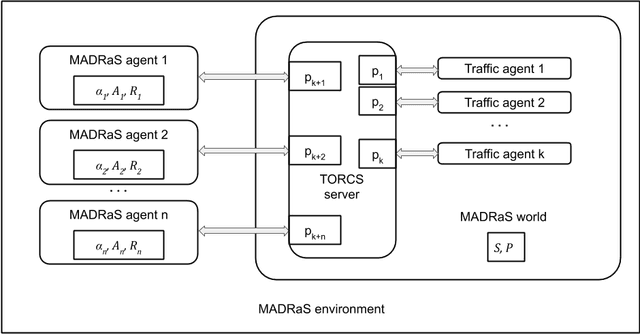

In this work, we present MADRaS, an open-source multi-agent driving simulator for use in the design and evaluation of motion planning algorithms for autonomous driving. MADRaS provides a platform for constructing a wide variety of highway and track driving scenarios where multiple driving agents can train for motion planning tasks using reinforcement learning and other machine learning algorithms. MADRaS is built on TORCS, an open-source car-racing simulator. TORCS offers a variety of cars with different dynamic properties and driving tracks with different geometries and surface properties. MADRaS inherits these functionalities from TORCS and introduces support for multi-agent training, inter-vehicular communication, noisy observations, stochastic actions, and custom traffic cars whose behaviours can be programmed to simulate challenging traffic conditions encountered in the real world. MADRaS can be used to create driving tasks whose complexities can be tuned along eight axes in well-defined steps. This makes it particularly suited for curriculum and continual learning. MADRaS is lightweight and it provides a convenient OpenAI Gym interface for independent control of each car. Apart from the primitive steering-acceleration-brake control mode of TORCS, MADRaS offers a hierarchical track-position -- speed control that can potentially be used to achieve better generalization. MADRaS uses multiprocessing to run each agent as a parallel process for efficiency and integrates well with popular reinforcement learning libraries like RLLib.
ExTra: Transfer-guided Exploration
Jun 27, 2019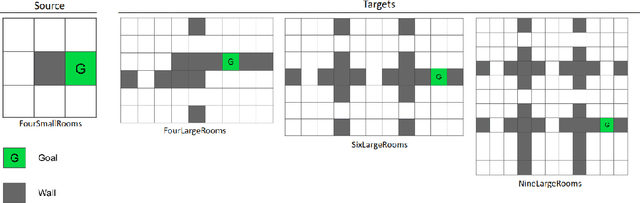
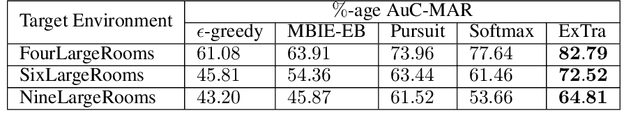
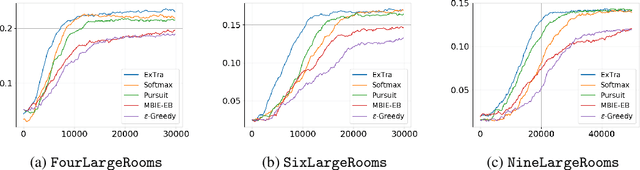

In this work we present a novel approach for transfer-guided exploration in reinforcement learning that is inspired by the human tendency to leverage experiences from similar encounters in the past while navigating a new task. Given an optimal policy in a related task-environment, we show that its bisimulation distance from the current task-environment gives a lower bound on the optimal advantage of state-action pairs in the current task-environment. Transfer-guided Exploration (ExTra) samples actions from a Softmax distribution over these lower bounds. In this way, actions with potentially higher optimum advantage are sampled more frequently. In our experiments on gridworld environments, we demonstrate that given access to an optimal policy in a related task-environment, ExTra can outperform popular domain-specific exploration strategies viz. epsilon greedy, Model-Based Interval Estimation - Exploration Based (MBIE-EB), Pursuit and Boltzmann in terms of sample complexity and rate of convergence. We further show that ExTra is robust to choices of source task and shows a graceful degradation of performance as the dissimilarity of the source task increases. We also demonstrate that ExTra, when used alongside traditional exploration algorithms, improves their rate of convergence. Thus it is capable of complimenting the efficacy of traditional exploration algorithms.
PUNCH: Positive UNlabelled Classification based information retrieval in Hyperspectral images
Apr 09, 2019
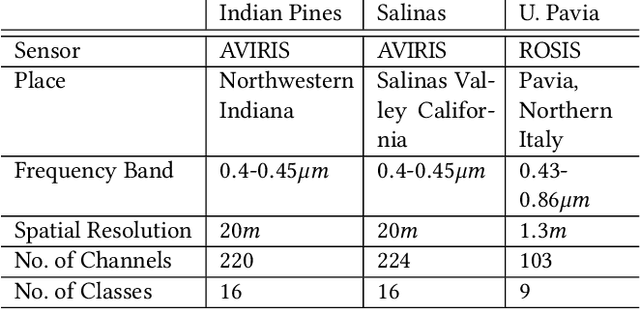

Hyperspectral images of land-cover captured by airborne or satellite-mounted sensors provide a rich source of information about the chemical composition of the materials present in a given place. This makes hyperspectral imaging an important tool for earth sciences, land-cover studies, and military and strategic applications. However, the scarcity of labeled training examples and spatial variability of spectral signature are two of the biggest challenges faced by hyperspectral image classification. In order to address these issues, we aim to develop a framework for material-agnostic information retrieval in hyperspectral images based on Positive-Unlabelled (PU) classification. Given a hyperspectral scene, the user labels some positive samples of a material he/she is looking for and our goal is to retrieve all the remaining instances of the query material in the scene. Additionally, we require the system to work equally well for any material in any scene without the user having to disclose the identity of the query material. This material-agnostic nature of the framework provides it with superior generalization abilities. We explore two alternative approaches to solve the hyperspectral image classification problem within this framework. The first approach is an adaptation of non-negative risk estimation based PU learning for hyperspectral data. The second approach is based on one-versus-all positive-negative classification where the negative class is approximately sampled using a novel spectral-spatial retrieval model. We propose two annotator models - uniform and blob - that represent the labelling patterns of a human annotator. We compare the performances of the proposed algorithms for each annotator model on three benchmark hyperspectral image datasets - Indian Pines, Pavia University and Salinas.
RAIL: Risk-Averse Imitation Learning
Nov 29, 2017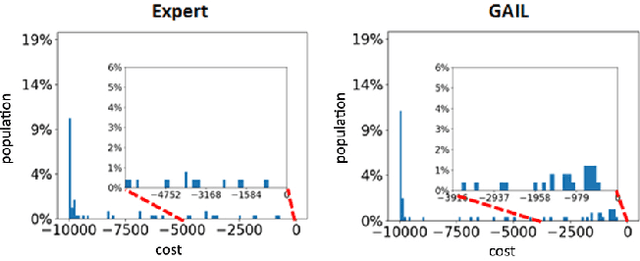
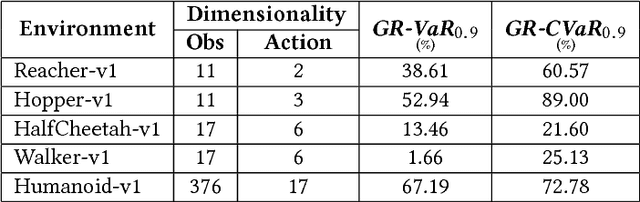
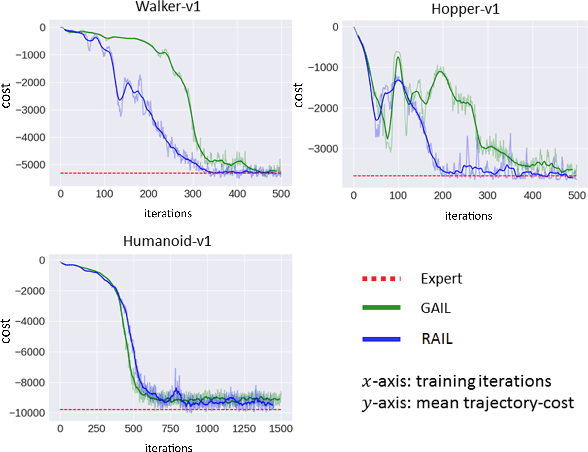
Imitation learning algorithms learn viable policies by imitating an expert's behavior when reward signals are not available. Generative Adversarial Imitation Learning (GAIL) is a state-of-the-art algorithm for learning policies when the expert's behavior is available as a fixed set of trajectories. We evaluate in terms of the expert's cost function and observe that the distribution of trajectory-costs is often more heavy-tailed for GAIL-agents than the expert at a number of benchmark continuous-control tasks. Thus, high-cost trajectories, corresponding to tail-end events of catastrophic failure, are more likely to be encountered by the GAIL-agents than the expert. This makes the reliability of GAIL-agents questionable when it comes to deployment in risk-sensitive applications like robotic surgery and autonomous driving. In this work, we aim to minimize the occurrence of tail-end events by minimizing tail risk within the GAIL framework. We quantify tail risk by the Conditional-Value-at-Risk (CVaR) of trajectories and develop the Risk-Averse Imitation Learning (RAIL) algorithm. We observe that the policies learned with RAIL show lower tail-end risk than those of vanilla GAIL. Thus the proposed RAIL algorithm appears as a potent alternative to GAIL for improved reliability in risk-sensitive applications.
Visualization Regularizers for Neural Network based Image Recognition
Jan 03, 2017

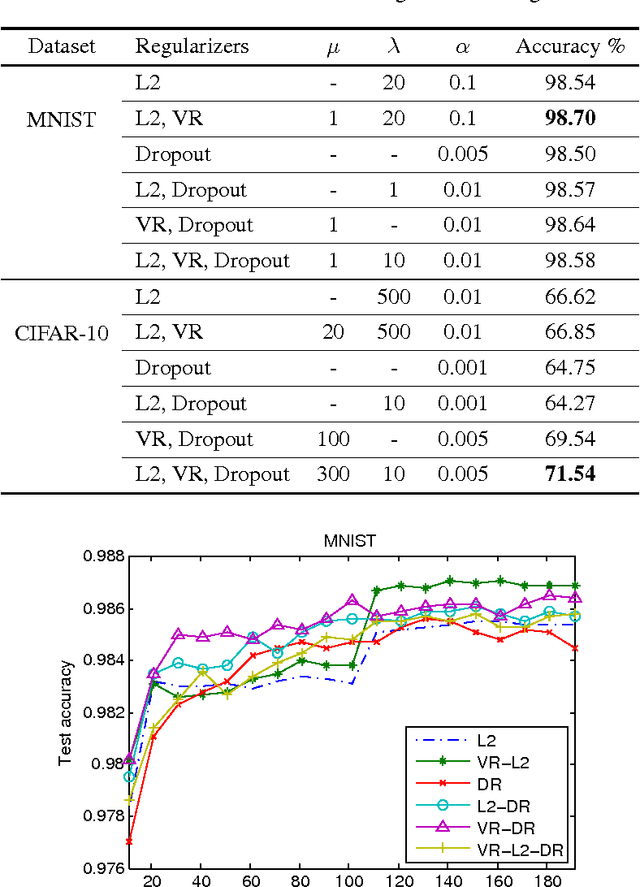
The success of deep neural networks is mostly due their ability to learn meaningful features from the data. Features learned in the hidden layers of deep neural networks trained in computer vision tasks have been shown to be similar to mid-level vision features. We leverage this fact in this work and propose the visualization regularizer for image tasks. The proposed regularization technique enforces smoothness of the features learned by hidden nodes and turns out to be a special case of Tikhonov regularization. We achieve higher classification accuracy as compared to existing regularizers such as the L2 norm regularizer and dropout, on benchmark datasets without changing the training computational complexity.
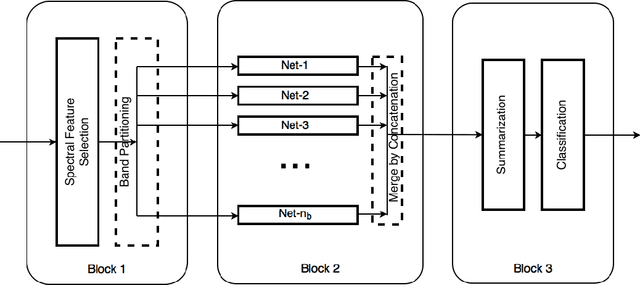
BASS Net: Band-Adaptive Spectral-Spatial Feature Learning Neural Network for Hyperspectral Image Classification
Dec 02, 2016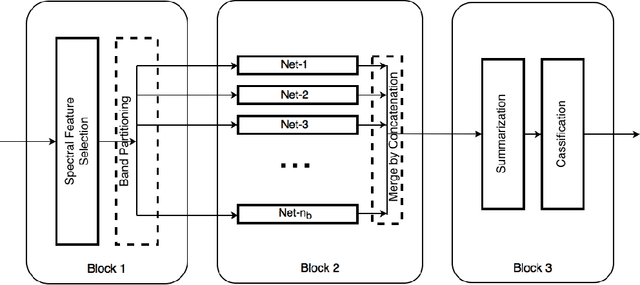
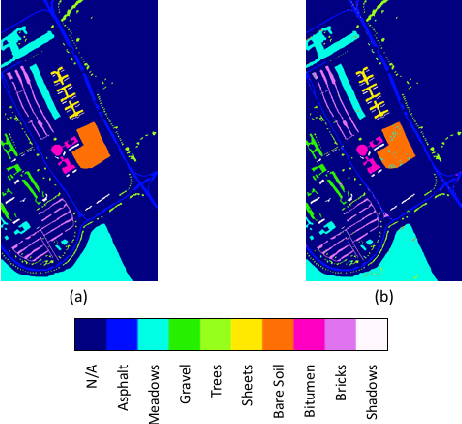
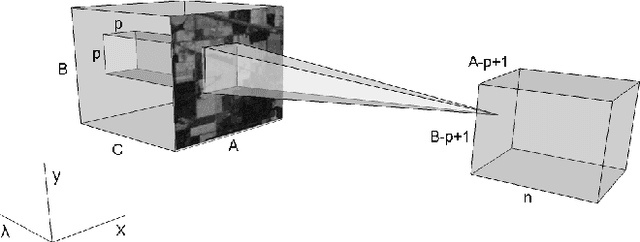
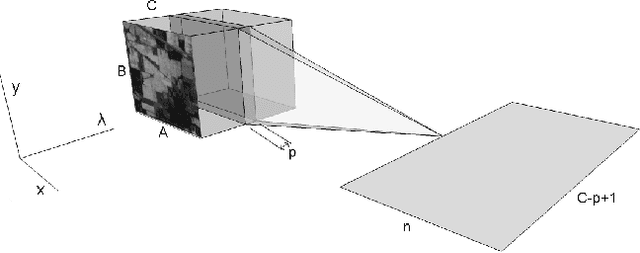
Deep learning based landcover classification algorithms have recently been proposed in literature. In hyperspectral images (HSI) they face the challenges of large dimensionality, spatial variability of spectral signatures and scarcity of labeled data. In this article we propose an end-to-end deep learning architecture that extracts band specific spectral-spatial features and performs landcover classification. The architecture has fewer independent connection weights and thus requires lesser number of training data. The method is found to outperform the highest reported accuracies on popular hyperspectral image data sets.