 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Pixels for Reinforcement Learning via Implicit Attention
Paper and Code
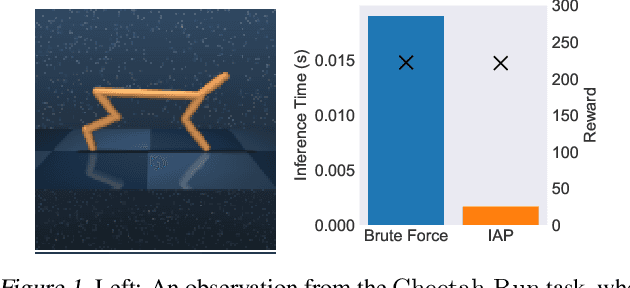
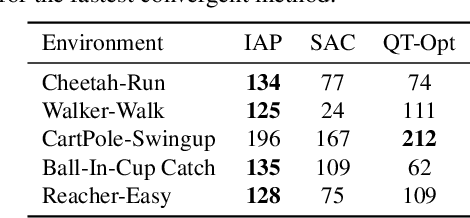
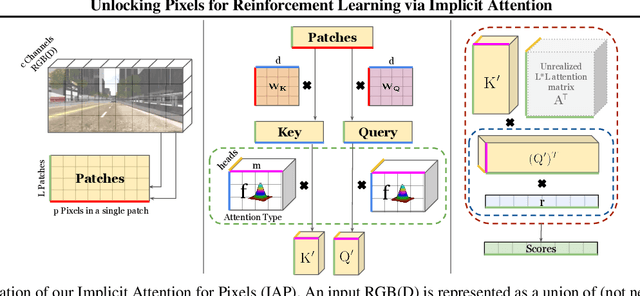

There has recently been significant interest in training reinforcement learning (RL) agents in vision-based environments. This poses many challenges, such as high dimensionality and potential for observational overfitting through spurious correlations. A promising approach to solve both of these problems is a self-attention bottleneck, which provides a simple and effective framework for learning high performing policies, even in the presence of distractions. However, due to poor scalability of attention architectures, these methods do not scale beyond low resolution visual inputs, using large patches (thus small attention matrices). In this paper we make use of new efficient attention algorithms, recently shown to be highly effective for Transformers, and demonstrate that these new techniques can be applied in the RL setting. This allows our attention-based controllers to scale to larger visual inputs, and facilitate the use of smaller patches, even individual pixels, improving generalization. In addition, we propose a new efficient algorithm approximating softmax attention with what we call hybrid random features, leveraging the theory of angular kernels. We show theoretically and empirically that hybrid random features is a promising approach when using attention for vision-based RL.