 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExTra: Transfer-guided Exploration
Paper and Code
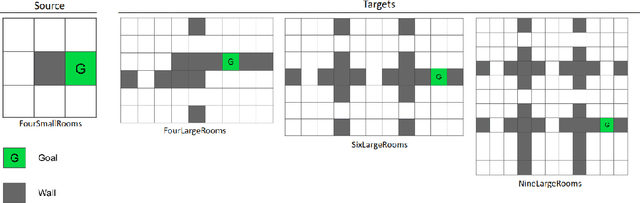
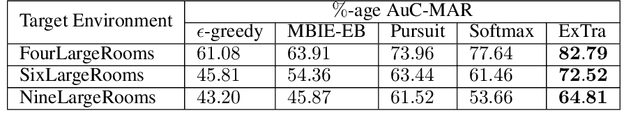
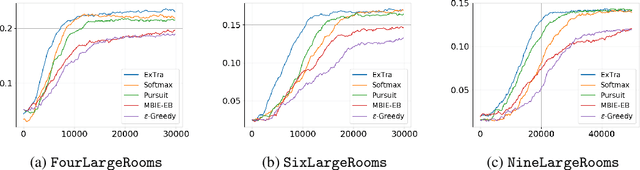

In this work we present a novel approach for transfer-guided exploration in reinforcement learning that is inspired by the human tendency to leverage experiences from similar encounters in the past while navigating a new task. Given an optimal policy in a related task-environment, we show that its bisimulation distance from the current task-environment gives a lower bound on the optimal advantage of state-action pairs in the current task-environment. Transfer-guided Exploration (ExTra) samples actions from a Softmax distribution over these lower bounds. In this way, actions with potentially higher optimum advantage are sampled more frequently. In our experiments on gridworld environments, we demonstrate that given access to an optimal policy in a related task-environment, ExTra can outperform popular domain-specific exploration strategies viz. epsilon greedy, Model-Based Interval Estimation - Exploration Based (MBIE-EB), Pursuit and Boltzmann in terms of sample complexity and rate of convergence. We further show that ExTra is robust to choices of source task and shows a graceful degradation of performance as the dissimilarity of the source task increases. We also demonstrate that ExTra, when used alongside traditional exploration algorithms, improves their rate of convergence. Thus it is capable of complimenting the efficacy of traditional exploration algorithms.