 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Generative Communication between Embodied Agents Good for Zero-Shot ObjectNav?
Paper and Code
Aug 03, 2024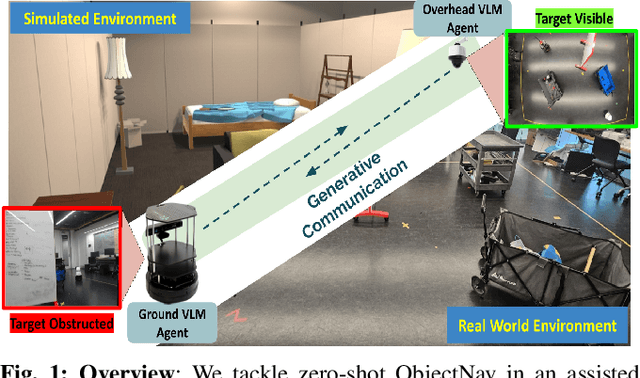


In Zero-Shot ObjectNav, an embodied ground agent is expected to navigate to a target object specified by a natural language label without any environment-specific fine-tuning. This is challenging, given the limited view of a ground agent and its independent exploratory behavior. To address these issues, we consider an assistive overhead agent with a bounded global view alongside the ground agent and present two coordinated navigation schemes for judicious exploration. We establish the influence of the Generative Communication (GC) between the embodied agents equipped with Vision-Language Models (VLMs) in improving zero-shot ObjectNav, achieving a 10% improvement in the ground agent's ability to find the target object in comparison with an unassisted setup in simulation. We further analyze the GC for unique traits quantifying the presence of hallucination and cooperation. In particular, we identify a unique trait of "preemptive hallucination" specific to our embodied setting, where the overhead agent assumes that the ground agent has executed an action in the dialogue when it is yet to move. Finally, we conduct real-world inferences with GC and showcase qualitative examples where countering pre-emptive hallucination via prompt finetuning improves real-world ObjectNav performance.