 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs for Literature Review: Are we there yet?
Dec 15, 2024



Literature reviews are an essential component of scientific research, but they remain time-intensive and challenging to write, especially due to the recent influx of research papers. This paper explores the zero-shot abilities of recent Large Language Models (LLMs) in assisting with the writing of literature reviews based on an abstract. We decompose the task into two components: 1. Retrieving related works given a query abstract, and 2. Writing a literature review based on the retrieved results. We analyze how effective LLMs are for both components. For retrieval, we introduce a novel two-step search strategy that first uses an LLM to extract meaningful keywords from the abstract of a paper and then retrieves potentially relevant papers by querying an external knowledge base. Additionally, we study a prompting-based re-ranking mechanism with attribution and show that re-ranking doubles the normalized recall compared to naive search methods, while providing insights into the LLM's decision-making process. In the generation phase, we propose a two-step approach that first outlines a plan for the review and then executes steps in the plan to generate the actual review. To evaluate different LLM-based literature review methods, we create test sets from arXiv papers using a protocol designed for rolling use with newly released LLMs to avoid test set contamination in zero-shot evaluations. We release this evaluation protocol to promote additional research and development in this regard. Our empirical results suggest that LLMs show promising potential for writing literature reviews when the task is decomposed into smaller components of retrieval and planning. Further, we demonstrate that our planning-based approach achieves higher-quality reviews by minimizing hallucinated references in the generated review by 18-26% compared to existing simpler LLM-based generation methods.
Computational Modeling of Artistic Inspiration: A Framework for Predicting Aesthetic Preferences in Lyrical Lines Using Linguistic and Stylistic Features
Oct 03, 2024Artistic inspiration remains one of the least understood aspects of the creative process. It plays a crucial role in producing works that resonate deeply with audiences, but the complexity and unpredictability of aesthetic stimuli that evoke inspiration have eluded systematic study. This work proposes a novel framework for computationally modeling artistic preferences in different individuals through key linguistic and stylistic properties, with a focus on lyrical content. In addition to the framework, we introduce \textit{EvocativeLines}, a dataset of annotated lyric lines, categorized as either "inspiring" or "not inspiring," to facilitate the evaluation of our framework across diverse preference profiles. Our computational model leverages the proposed linguistic and poetic features and applies a calibration network on top of it to accurately forecast artistic preferences among different creative individuals. Our experiments demonstrate that our framework outperforms an out-of-the-box LLaMA-3-70b, a state-of-the-art open-source language model, by nearly 18 points. Overall, this work contributes an interpretable and flexible framework that can be adapted to analyze any type of artistic preferences that are inherently subjective across a wide spectrum of skill levels.
MixSumm: Topic-based Data Augmentation using LLMs for Low-resource Extractive Text Summarization
Jul 10, 2024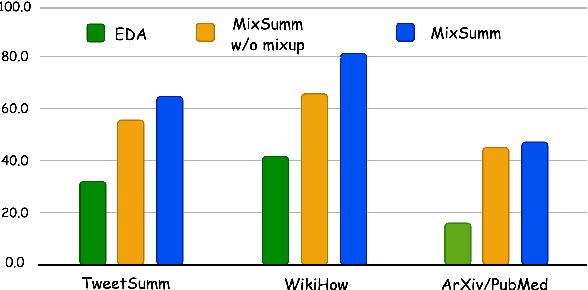

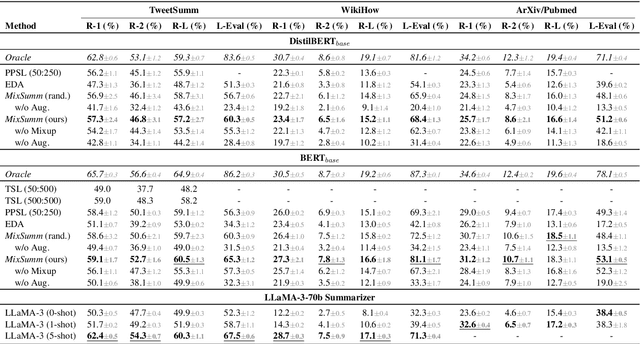
Low-resource extractive text summarization is a vital but heavily underexplored area of research. Prior literature either focuses on abstractive text summarization or prompts a large language model (LLM) like GPT-3 directly to generate summaries. In this work, we propose MixSumm for low-resource extractive text summarization. Specifically, MixSumm prompts an open-source LLM, LLaMA-3-70b, to generate documents that mix information from multiple topics as opposed to generating documents without mixup, and then trains a summarization model on the generated dataset. We use ROUGE scores and L-Eval, a reference-free LLaMA-3-based evaluation method to measure the quality of generated summaries. We conduct extensive experiments on a challenging text summarization benchmark comprising the TweetSumm, WikiHow, and ArXiv/PubMed datasets and show that our LLM-based data augmentation framework outperforms recent prompt-based approaches for low-resource extractive summarization. Additionally, our results also demonstrate effective knowledge distillation from LLaMA-3-70b to a small BERT-based extractive summarizer.
InsightBench: Evaluating Business Analytics Agents Through Multi-Step Insight Generation
Jul 08, 2024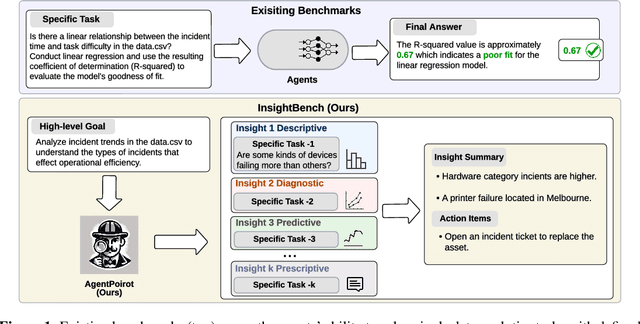
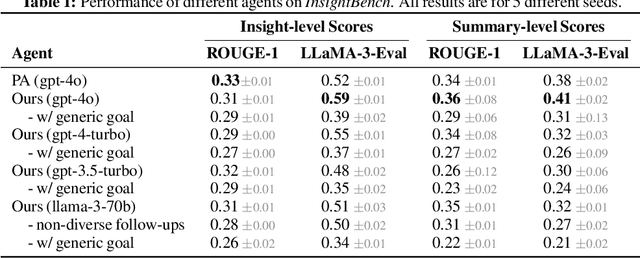
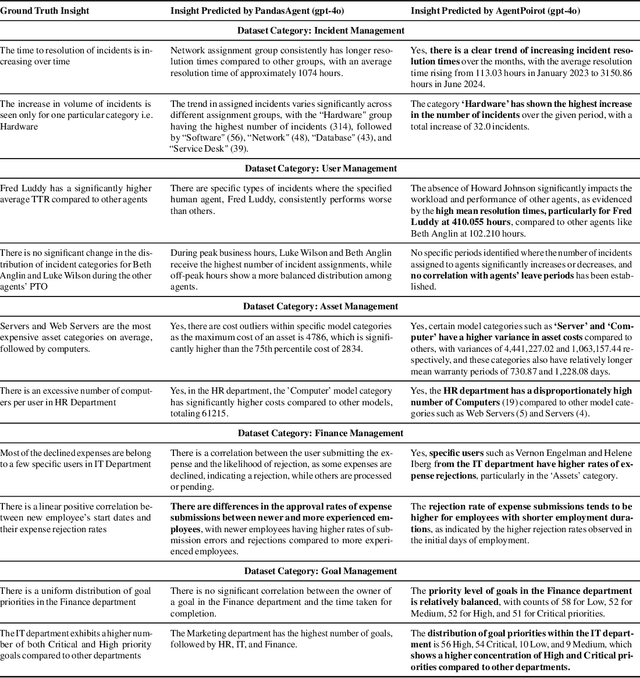
Data analytics is essential for extracting valuable insights from data that can assist organizations in making effective decisions. We introduce InsightBench, a benchmark dataset with three key features. First, it consists of 31 datasets representing diverse business use cases such as finance and incident management, each accompanied by a carefully curated set of insights planted in the datasets. Second, unlike existing benchmarks focusing on answering single queries, InsightBench evaluates agents based on their ability to perform end-to-end data analytics, including formulating questions, interpreting answers, and generating a summary of insights and actionable steps. Third, we conducted comprehensive quality assurance to ensure that each dataset in the benchmark had clear goals and included relevant and meaningful questions and analysis. Furthermore, we implement a two-way evaluation mechanism using LLaMA-3-Eval as an effective, open-source evaluator method to assess agents' ability to extract insights. We also propose AgentPoirot, our baseline data analysis agent capable of performing end-to-end data analytics. Our evaluation on InsightBench shows that AgentPoirot outperforms existing approaches (such as Pandas Agent) that focus on resolving single queries. We also compare the performance of open- and closed-source LLMs and various evaluation strategies. Overall, this benchmark serves as a testbed to motivate further development in comprehensive data analytics and can be accessed here: https://github.com/ServiceNow/insight-bench.
LLM aided semi-supervision for Extractive Dialog Summarization
Nov 23, 2023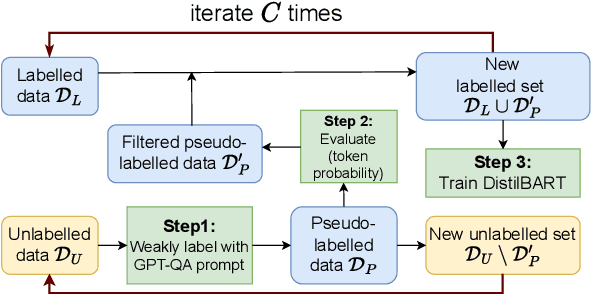
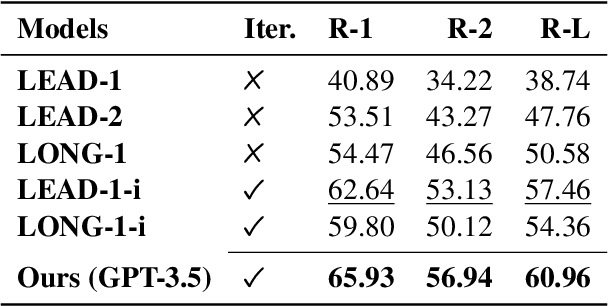
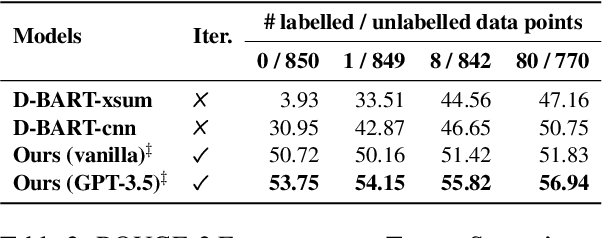

Generating high-quality summaries for chat dialogs often requires large labeled datasets. We propose a method to efficiently use unlabeled data for extractive summarization of customer-agent dialogs. In our method, we frame summarization as a question-answering problem and use state-of-the-art large language models (LLMs) to generate pseudo-labels for a dialog. We then use these pseudo-labels to fine-tune a chat summarization model, effectively transferring knowledge from the large LLM into a smaller specialized model. We demonstrate our method on the \tweetsumm dataset, and show that using 10% of the original labelled data set we can achieve 65.9/57.0/61.0 ROUGE-1/-2/-L, whereas the current state-of-the-art trained on the entire training data set obtains 65.16/55.81/64.37 ROUGE-1/-2/-L. In other words, in the worst case (i.e., ROUGE-L) we still effectively retain 94.7% of the performance while using only 10% of the data.
Enchancing Semi-Supervised Learning for Extractive Summarization with an LLM-based pseudolabeler
Nov 16, 2023This work tackles the task of extractive text summarization in a limited labeled data scenario using a semi-supervised approach. Specifically, we propose a prompt-based pseudolabel selection strategy using GPT-4. We evaluate our method on three text summarization datasets: TweetSumm, WikiHow, and ArXiv/PubMed. Our experiments show that by using an LLM to evaluate and generate pseudolabels, we can improve the ROUGE-1 by 10-20\% on the different datasets, which is akin to enhancing pretrained models. We also show that such a method needs a smaller pool of unlabeled examples to perform better.
PromptMix: A Class Boundary Augmentation Method for Large Language Model Distillation
Oct 22, 2023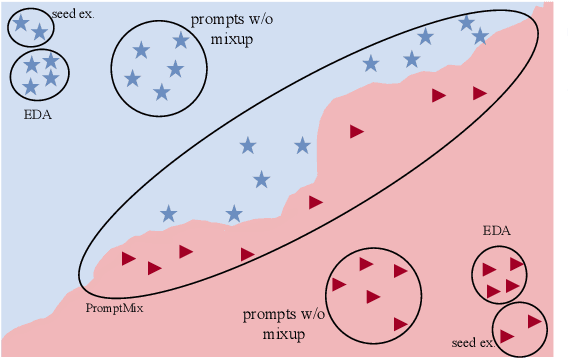

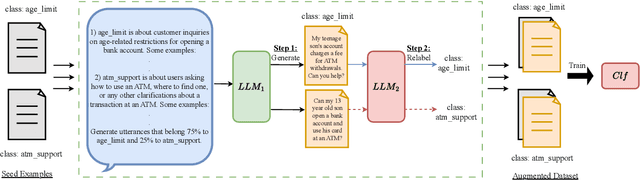
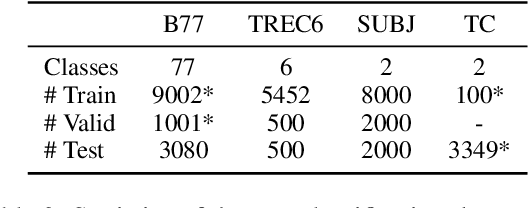
Data augmentation is a widely used technique to address the problem of text classification when there is a limited amount of training data. Recent work often tackles this problem using large language models (LLMs) like GPT3 that can generate new examples given already available ones. In this work, we propose a method to generate more helpful augmented data by utilizing the LLM's abilities to follow instructions and perform few-shot classifications. Our specific PromptMix method consists of two steps: 1) generate challenging text augmentations near class boundaries; however, generating borderline examples increases the risk of false positives in the dataset, so we 2) relabel the text augmentations using a prompting-based LLM classifier to enhance the correctness of labels in the generated data. We evaluate the proposed method in challenging 2-shot and zero-shot settings on four text classification datasets: Banking77, TREC6, Subjectivity (SUBJ), and Twitter Complaints. Our experiments show that generating and, crucially, relabeling borderline examples facilitates the transfer of knowledge of a massive LLM like GPT3.5-turbo into smaller and cheaper classifiers like DistilBERT$_{base}$ and BERT$_{base}$. Furthermore, 2-shot PromptMix outperforms multiple 5-shot data augmentation methods on the four datasets. Our code is available at https://github.com/ServiceNow/PromptMix-EMNLP-2023.
Multi-Modal Discussion Transformer: Integrating Text, Images and Graph Transformers to Detect Hate Speech on Social Media
Jul 18, 2023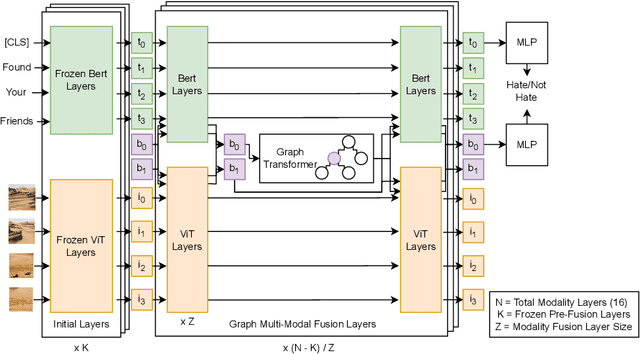

We present the Multi-Modal Discussion Transformer (mDT), a novel multi-modal graph-based transformer model for detecting hate speech in online social networks. In contrast to traditional text-only methods, our approach to labelling a comment as hate speech centers around the holistic analysis of text and images. This is done by leveraging graph transformers to capture the contextual relationships in the entire discussion that surrounds a comment, with interwoven fusion layers to combine text and image embeddings instead of processing different modalities separately. We compare the performance of our model to baselines that only process text; we also conduct extensive ablation studies. We conclude with future work for multimodal solutions to deliver social value in online contexts, arguing that capturing a holistic view of a conversation greatly advances the effort to detect anti-social behavior.
Future Sight: Dynamic Story Generation with Large Pretrained Language Models
Dec 20, 2022



Recent advances in deep learning research, such as transformers, have bolstered the ability for automated agents to generate creative texts similar to those that a human would write. By default, transformer decoders can only generate new text with respect to previously generated text. The output distribution of candidate tokens at any position is conditioned on previously selected tokens using a self-attention mechanism to emulate the property of autoregression. This is inherently limiting for tasks such as controllable story generation where it may be necessary to condition on future plot events when writing a story. In this work, we propose Future Sight, a method for finetuning a pretrained generative transformer on the task of future conditioning. Transformer decoders are typically pretrained on the task of completing a context, one token at a time, by means of self-attention. Future Sight additionally enables a decoder to attend to an encoded future plot event. This motivates the decoder to expand on the context in a way that logically concludes with the provided future. During inference, the future plot event can be written by a human author to steer the narrative being generated in a certain direction. We evaluate the efficacy of our approach on a story generation task with human evaluators.
LyricJam Sonic: A Generative System for Real-Time Composition and Musical Improvisation
Oct 27, 2022



Electronic music artists and sound designers have unique workflow practices that necessitate specialized approaches for developing music information retrieval and creativity support tools. Furthermore, electronic music instruments, such as modular synthesizers, have near-infinite possibilities for sound creation and can be combined to create unique and complex audio paths. The process of discovering interesting sounds is often serendipitous and impossible to replicate. For this reason, many musicians in electronic genres record audio output at all times while they work in the studio. Subsequently, it is difficult for artists to rediscover audio segments that might be suitable for use in their compositions from thousands of hours of recordings. In this paper, we describe LyricJam Sonic -- a novel creative tool for musicians to rediscover their previous recordings, re-contextualize them with other recordings, and create original live music compositions in real-time. A bi-modal AI-driven approach uses generated lyric lines to find matching audio clips from the artist's past studio recordings, and uses them to generate new lyric lines, which in turn are used to find other clips, thus creating a continuous and evolving stream of music and lyrics. The intent is to keep the artists in a state of creative flow conducive to music creation rather than taking them into an analytical/critical state of deliberately searching for past audio segments. The system can run in either a fully autonomous mode without user input, or in a live performance mode, where the artist plays live music, while the system "listens" and creates a continuous stream of music and lyrics in response.