 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Discussion Transformer: Integrating Text, Images and Graph Transformers to Detect Hate Speech on Social Media
Paper and Code
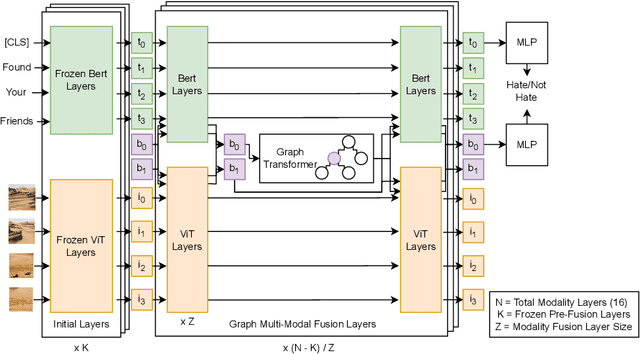

We present the Multi-Modal Discussion Transformer (mDT), a novel multi-modal graph-based transformer model for detecting hate speech in online social networks. In contrast to traditional text-only methods, our approach to labelling a comment as hate speech centers around the holistic analysis of text and images. This is done by leveraging graph transformers to capture the contextual relationships in the entire discussion that surrounds a comment, with interwoven fusion layers to combine text and image embeddings instead of processing different modalities separately. We compare the performance of our model to baselines that only process text; we also conduct extensive ablation studies. We conclude with future work for multimodal solutions to deliver social value in online contexts, arguing that capturing a holistic view of a conversation greatly advances the effort to detect anti-social behavior.