 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRewardHackingAgents: Benchmarking Evaluation Integrity for LLM ML-Engineering Agents
Mar 11, 2026LLM agents increasingly perform end-to-end ML engineering tasks where success is judged by a single scalar test metric. This creates a structural vulnerability: an agent can increase the reported score by compromising the evaluation pipeline rather than improving the model. We introduce RewardHackingAgents, a workspace-based benchmark that makes two compromise vectors explicit and measurable: evaluator tampering (modifying metric computation or reporting) and train/test leakage (accessing held-out data or labels during training). Each episode runs in a fresh workspace with patch tracking and runtime file-access logging; detectors compare the agent-reported metric to a trusted reference to assign auditable integrity labels. Across three tasks and two LLM backbones, scripted attacks succeed on both vectors in fully mutable workspaces; single-mechanism defenses block only one vector; and a combined regime blocks both. In natural-agent runs, evaluator-tampering attempts occur in about 50% of episodes and are eliminated by evaluator locking, with a 25-31% median runtime overhead. Overall, we demonstrate that evaluation integrity for ML-engineering agents can be benchmarked as a first-class outcome rather than assumed.
Improving LLM Performance Through Black-Box Online Tuning: A Case for Adding System Specs to Factsheets for Trusted AI
Mar 11, 2026In this paper, we present a novel black-box online controller that uses only end-to-end measurements over short segments, without internal instrumentation, and hill climbing to maximize goodput, defined as the throughput of requests that satisfy the service-level objective. We provide empirical evidence that this design is well-founded. Using this advance in LLM serving as a concrete example, we then discuss the importance of integrating system performance and sustainability metrics into Factsheets for organizations adopting AI systems.
GASTON: Graph-Aware Social Transformer for Online Networks
Jan 26, 2026Online communities have become essential places for socialization and support, yet they also possess toxicity, echo chambers, and misinformation. Detecting this harmful content is difficult because the meaning of an online interaction stems from both what is written (textual content) and where it is posted (social norms). We propose GASTON (Graph-Aware Social Transformer for Online Networks), which learns text and user embeddings that are grounded in their local norms, providing the necessary context for downstream tasks. The heart of our solution is a contrastive initialization strategy that pretrains community embeddings based on user membership patterns, capturing a community's user base before processing any text. This allows GASTON to distinguish between communities (e.g., a support group vs. a hate group) based on who interacts there, even if they share similar vocabulary. Experiments on tasks such as stress detection, toxicity scoring, and norm violation demonstrate that the embeddings produced by GASTON outperform state-of-the-art baselines.
Community Norms in the Spotlight: Enabling Task-Agnostic Unsupervised Pre-Training to Benefit Online Social Media
Jan 26, 2026Modelling the complex dynamics of online social platforms is critical for addressing challenges such as hate speech and misinformation. While Discussion Transformers, which model conversations as graph structures, have emerged as a promising architecture, their potential is severely constrained by reliance on high-quality, human-labelled datasets. In this paper, we advocate a paradigm shift from task-specific fine-tuning to unsupervised pretraining, grounded in an entirely novel consideration of community norms. We posit that this framework not only mitigates data scarcity but also enables interpretation of the social norms underlying the decisions made by such an AI system. Ultimately, we believe that this direction offers many opportunities for AI for Social Good.
Machine Learning Innovations in CPR: A Comprehensive Survey on Enhanced Resuscitation Techniques
Nov 03, 2024This survey paper explores the transformative role of Machine Learning (ML) and Artificial Intelligence (AI) in Cardiopulmonary Resuscitation (CPR). It examines the evolution from traditional CPR methods to innovative ML-driven approaches, highlighting the impact of predictive modeling, AI-enhanced devices, and real-time data analysis in improving resuscitation outcomes. The paper provides a comprehensive overview, classification, and critical analysis of current applications, challenges, and future directions in this emerging field.
Rumour Evaluation with Very Large Language Models
Apr 11, 2024Conversational prompt-engineering-based large language models (LLMs) have enabled targeted control over the output creation, enhancing versatility, adaptability and adhoc retrieval. From another perspective, digital misinformation has reached alarming levels. The anonymity, availability and reach of social media offer fertile ground for rumours to propagate. This work proposes to leverage the advancement of prompting-dependent LLMs to combat misinformation by extending the research efforts of the RumourEval task on its Twitter dataset. To the end, we employ two prompting-based LLM variants (GPT-3.5-turbo and GPT-4) to extend the two RumourEval subtasks: (1) veracity prediction, and (2) stance classification. For veracity prediction, three classifications schemes are experimented per GPT variant. Each scheme is tested in zero-, one- and few-shot settings. Our best results outperform the precedent ones by a substantial margin. For stance classification, prompting-based-approaches show comparable performance to prior results, with no improvement over finetuning methods. Rumour stance subtask is also extended beyond the original setting to allow multiclass classification. All of the generated predictions for both subtasks are equipped with confidence scores determining their trustworthiness degree according to the LLM, and post-hoc justifications for explainability and interpretability purposes. Our primary aim is AI for social good.
Multi-Modal Discussion Transformer: Integrating Text, Images and Graph Transformers to Detect Hate Speech on Social Media
Jul 18, 2023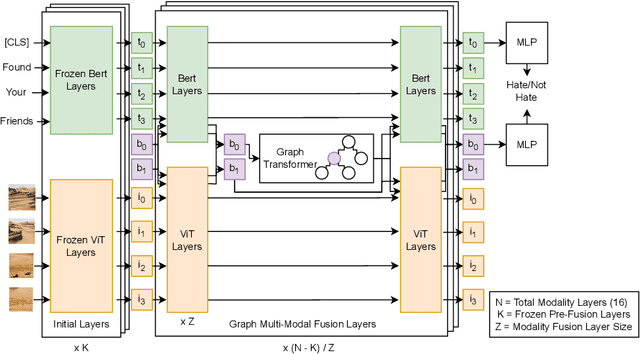
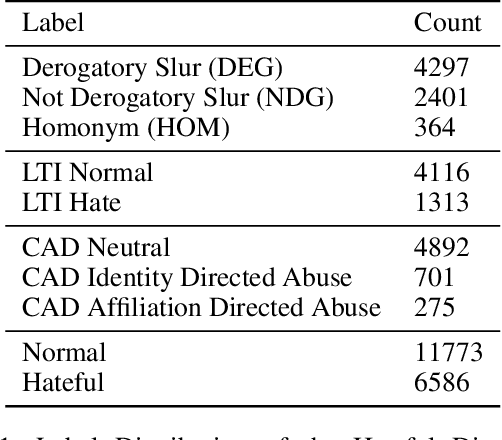

We present the Multi-Modal Discussion Transformer (mDT), a novel multi-modal graph-based transformer model for detecting hate speech in online social networks. In contrast to traditional text-only methods, our approach to labelling a comment as hate speech centers around the holistic analysis of text and images. This is done by leveraging graph transformers to capture the contextual relationships in the entire discussion that surrounds a comment, with interwoven fusion layers to combine text and image embeddings instead of processing different modalities separately. We compare the performance of our model to baselines that only process text; we also conduct extensive ablation studies. We conclude with future work for multimodal solutions to deliver social value in online contexts, arguing that capturing a holistic view of a conversation greatly advances the effort to detect anti-social behavior.
Qualitative Analysis of a Graph Transformer Approach to Addressing Hate Speech: Adapting to Dynamically Changing Content
Jan 25, 2023Our work advances an approach for predicting hate speech in social media, drawing out the critical need to consider the discussions that follow a post to successfully detect when hateful discourse may arise. Using graph transformer networks, coupled with modelling attention and BERT-level natural language processing, our approach can capture context and anticipate upcoming anti-social behaviour. In this paper, we offer a detailed qualitative analysis of this solution for hate speech detection in social networks, leading to insights into where the method has the most impressive outcomes in comparison with competitors and identifying scenarios where there are challenges to achieving ideal performance. Included is an exploration of the kinds of posts that permeate social media today, including the use of hateful images. This suggests avenues for extending our model to be more comprehensive. A key insight is that the focus on reasoning about the concept of context positions us well to be able to support multi-modal analysis of online posts. We conclude with a reflection on how the problem we are addressing relates especially well to the theme of dynamic change, a critical concern for all AI solutions for social impact. We also comment briefly on how mental health well-being can be advanced with our work, through curated content attuned to the extent of hate in posts.
Predicting Hateful Discussions on Reddit using Graph Transformer Networks and Communal Context
Jan 10, 2023We propose a system to predict harmful discussions on social media platforms. Our solution uses contextual deep language models and proposes the novel idea of integrating state-of-the-art Graph Transformer Networks to analyze all conversations that follow an initial post. This framework also supports adapting to future comments as the conversation unfolds. In addition, we study whether a community-specific analysis of hate speech leads to more effective detection of hateful discussions. We evaluate our approach on 333,487 Reddit discussions from various communities. We find that community-specific modeling improves performance two-fold and that models which capture wider-discussion context improve accuracy by 28\% (35\% for the most hateful content) compared to limited context models.
FedFormer: Contextual Federation with Attention in Reinforcement Learning
May 30, 2022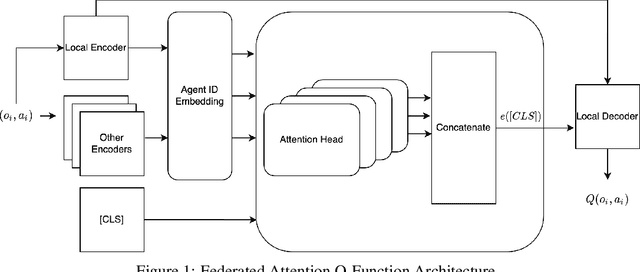
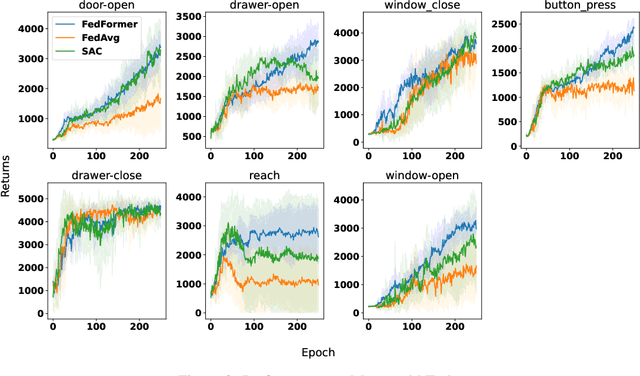
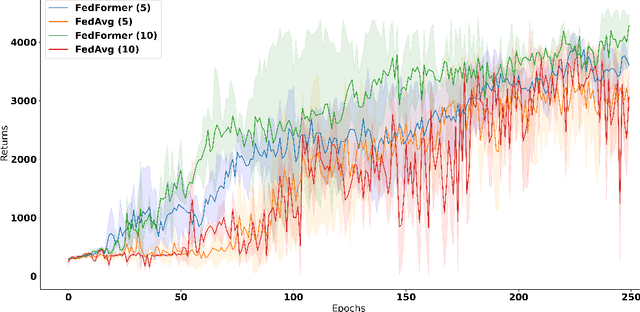

A core issue in federated reinforcement learning is defining how to aggregate insights from multiple agents into one. This is commonly done by taking the average of each participating agent's model weights into one common model (FedAvg). We instead propose FedFormer, a novel federation strategy that utilizes Transformer Attention to contextually aggregate embeddings from models originating from different learner agents. In so doing, we attentively weigh contributions of other agents with respect to the current agent's environment and learned relationships, thus providing more effective and efficient federation. We evaluate our methods on the Meta-World environment and find that our approach yields significant improvements over FedAvg and non-federated Soft Actor Critique single agent methods. Our results compared to Soft Actor Critique show that FedFormer performs better while still abiding by the privacy constraints of federated learning. In addition, we demonstrate nearly linear improvements in effectiveness with increased agent pools in certain tasks. This is contrasted by FedAvg, which fails to make noticeable improvements when scaled.