 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Mutual Trustworthiness in Federated Learning for Data-Rich Smart Cities
May 01, 2024



Federated learning is a promising collaborative and privacy-preserving machine learning approach in data-rich smart cities. Nevertheless, the inherent heterogeneity of these urban environments presents a significant challenge in selecting trustworthy clients for collaborative model training. The usage of traditional approaches, such as the random client selection technique, poses several threats to the system's integrity due to the possibility of malicious client selection. Primarily, the existing literature focuses on assessing the trustworthiness of clients, neglecting the crucial aspect of trust in federated servers. To bridge this gap, in this work, we propose a novel framework that addresses the mutual trustworthiness in federated learning by considering the trust needs of both the client and the server. Our approach entails: (1) Creating preference functions for servers and clients, allowing them to rank each other based on trust scores, (2) Establishing a reputation-based recommendation system leveraging multiple clients to assess newly connected servers, (3) Assigning credibility scores to recommending devices for better server trustworthiness measurement, (4) Developing a trust assessment mechanism for smart devices using a statistical Interquartile Range (IQR) method, (5) Designing intelligent matching algorithms considering the preferences of both parties. Based on simulation and experimental results, our approach outperforms baseline methods by increasing trust levels, global model accuracy, and reducing non-trustworthy clients in the system.
The Metaverse: Survey, Trends, Novel Pipeline Ecosystem & Future Directions
Apr 18, 2023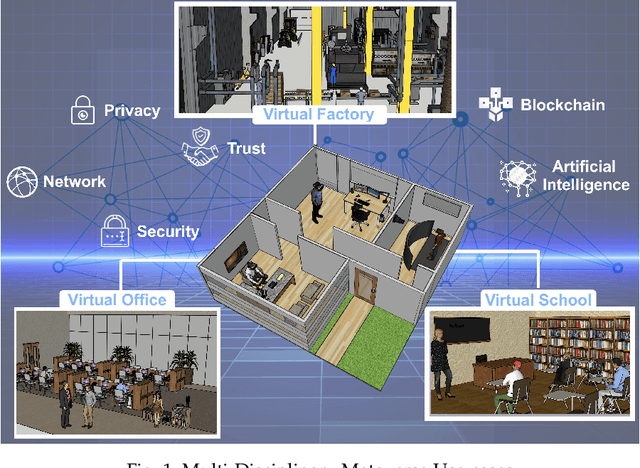

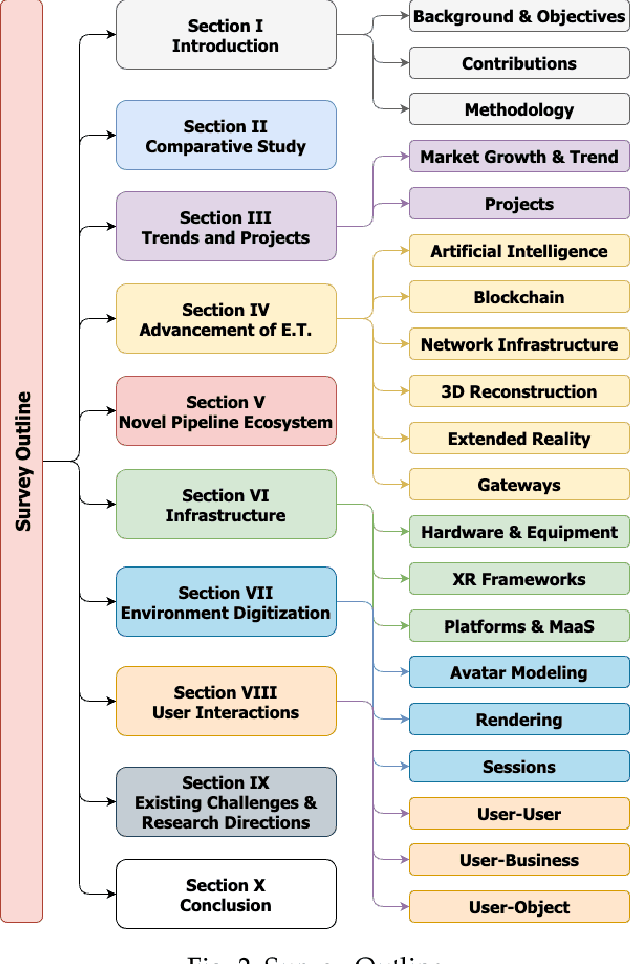

The Metaverse offers a second world beyond reality, where boundaries are non-existent, and possibilities are endless through engagement and immersive experiences using the virtual reality (VR) technology. Many disciplines can benefit from the advancement of the Metaverse when accurately developed, including the fields of technology, gaming, education, art, and culture. Nevertheless, developing the Metaverse environment to its full potential is an ambiguous task that needs proper guidance and directions. Existing surveys on the Metaverse focus only on a specific aspect and discipline of the Metaverse and lack a holistic view of the entire process. To this end, a more holistic, multi-disciplinary, in-depth, and academic and industry-oriented review is required to provide a thorough study of the Metaverse development pipeline. To address these issues, we present in this survey a novel multi-layered pipeline ecosystem composed of (1) the Metaverse computing, networking, communications and hardware infrastructure, (2) environment digitization, and (3) user interactions. For every layer, we discuss the components that detail the steps of its development. Also, for each of these components, we examine the impact of a set of enabling technologies and empowering domains (e.g., Artificial Intelligence, Security & Privacy, Blockchain, Business, Ethics, and Social) on its advancement. In addition, we explain the importance of these technologies to support decentralization, interoperability, user experiences, interactions, and monetization. Our presented study highlights the existing challenges for each component, followed by research directions and potential solutions. To the best of our knowledge, this survey is the most comprehensive and allows users, scholars, and entrepreneurs to get an in-depth understanding of the Metaverse ecosystem to find their opportunities and potentials for contribution.
FedMint: Intelligent Bilateral Client Selection in Federated Learning with Newcomer IoT Devices
Oct 31, 2022
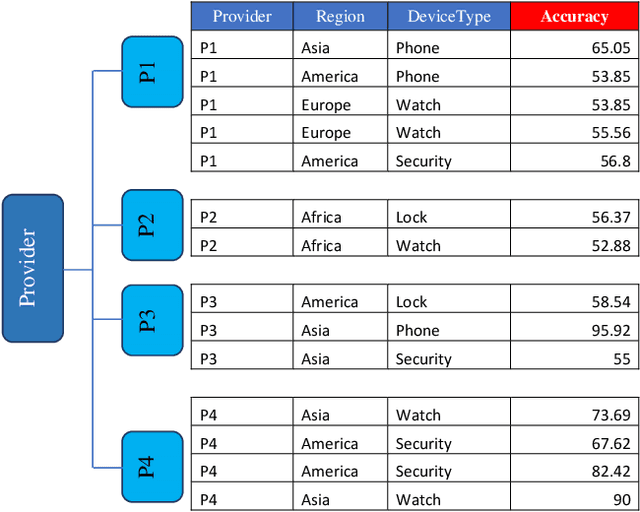


Federated Learning (FL) is a novel distributed privacy-preserving learning paradigm, which enables the collaboration among several participants (e.g., Internet of Things devices) for the training of machine learning models. However, selecting the participants that would contribute to this collaborative training is highly challenging. Adopting a random selection strategy would entail substantial problems due to the heterogeneity in terms of data quality, and computational and communication resources across the participants. Although several approaches have been proposed in the literature to overcome the problem of random selection, most of these approaches follow a unilateral selection strategy. In fact, they base their selection strategy on only the federated server's side, while overlooking the interests of the client devices in the process. To overcome this problem, we present in this paper FedMint, an intelligent client selection approach for federated learning on IoT devices using game theory and bootstrapping mechanism. Our solution involves the design of: (1) preference functions for the client IoT devices and federated servers to allow them to rank each other according to several factors such as accuracy and price, (2) intelligent matching algorithms that take into account the preferences of both parties in their design, and (3) bootstrapping technique that capitalizes on the collaboration of multiple federated servers in order to assign initial accuracy value for the newly connected IoT devices. Based on our simulation findings, our strategy surpasses the VanillaFL selection approach in terms of maximizing both the revenues of the client devices and accuracy of the global federated learning model.
Cloud computing as a platform for monetizing data services: A two-sided game business model
Apr 26, 2021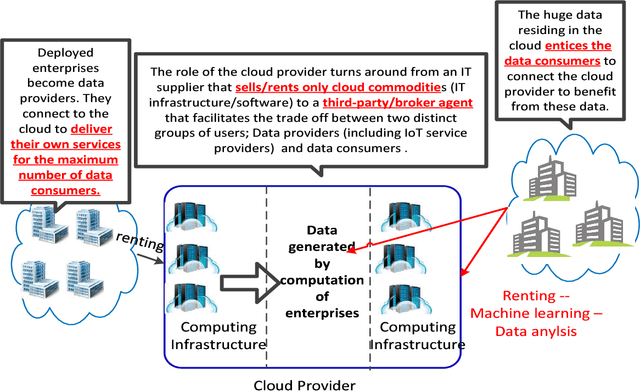
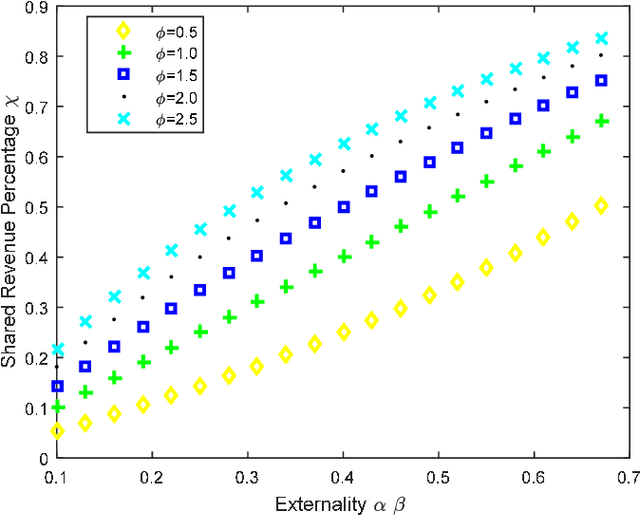
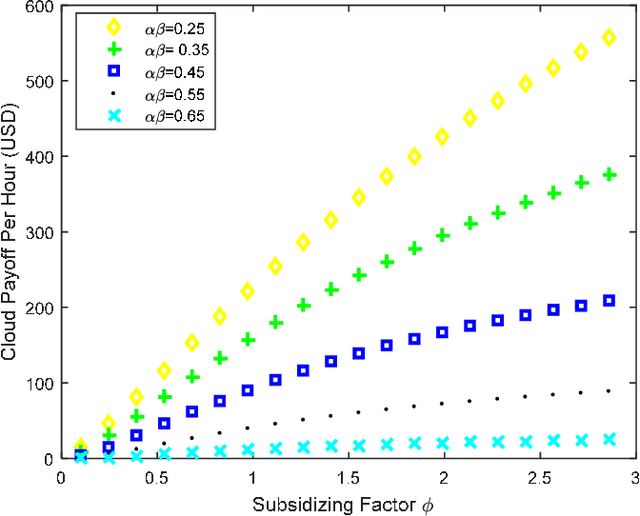
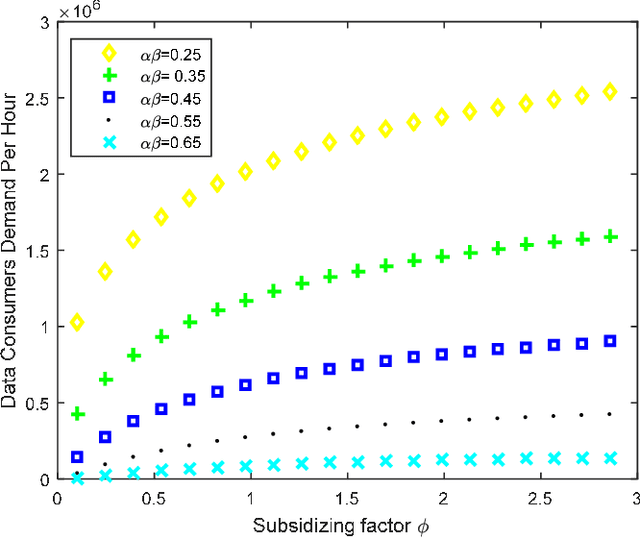
With the unprecedented reliance on cloud computing as the backbone for storing today's big data, we argue in this paper that the role of the cloud should be reshaped from being a passive virtual market to become an active platform for monetizing the big data through Artificial Intelligence (AI) services. The objective is to enable the cloud to be an active platform that can help big data service providers reach a wider set of customers and cloud users (i.e., data consumers) to be exposed to a larger and richer variety of data to run their data analytic tasks. To achieve this vision, we propose a novel game theoretical model, which consists of a mix of cooperative and competitive strategies. The players of the game are the big data service providers, cloud computing platform, and cloud users. The strategies of the players are modeled using the two-sided market theory that takes into consideration the network effects among involved parties, while integrating the externalities between the cloud resources and consumer demands into the design of the game. Simulations conducted using Amazon and google clustered data show that the proposed model improves the total surplus of all the involved parties in terms of cloud resources provision and monetary profits compared to the current merchant model.
A two-level solution to fight against dishonest opinions in recommendation-based trust systems
Jun 09, 2020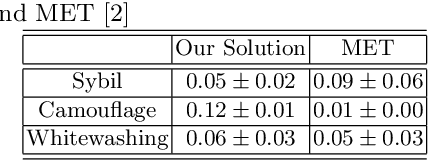
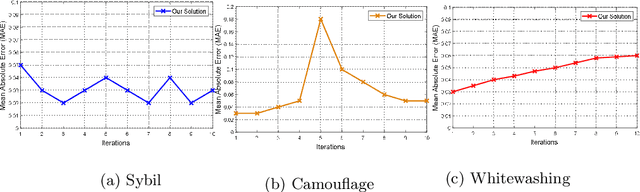
In this paper, we propose a mechanism to deal with dishonest opinions in recommendation-based trust models, at both the collection and processing levels. We consider a scenario in which an agent requests recommendations from multiple parties to build trust toward another agent. At the collection level, we propose to allow agents to self-assess the accuracy of their recommendations and autonomously decide on whether they would participate in the recommendation process or not. At the processing level, we propose a recommendations aggregation technique that is resilient to collusion attacks, followed by a credibility update mechanism for the participating agents. The originality of our work stems from its consideration of dishonest opinions at both the collection and processing levels, which allows for better and more persistent protection against dishonest recommenders. Experiments conducted on the Epinions dataset show that our solution yields better performance in protecting the recommendation process against Sybil attacks, in comparison with a competing model that derives the optimal network of advisors based on the agents' trust values.
Generative Adversarial Networks for Mitigating Biases in Machine Learning Systems
May 23, 2019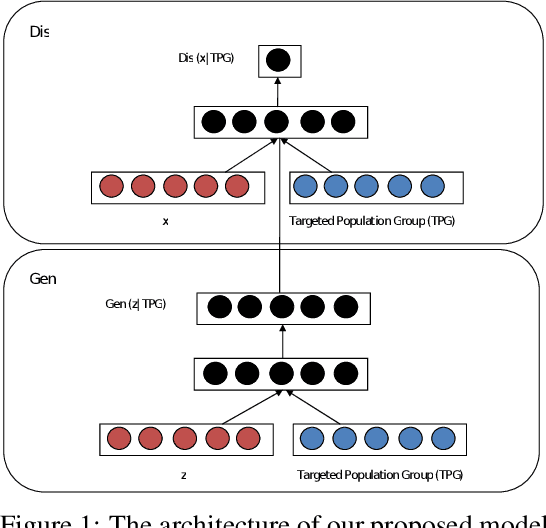


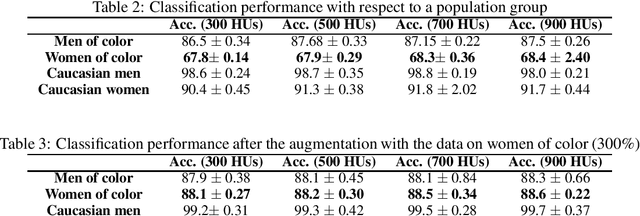
In this paper, we propose a new framework for mitigating biases in machine learning systems. The problem of the existing mitigation approaches is that they are model-oriented in the sense that they focus on tuning the training algorithms to produce fair results, while overlooking the fact that the training data can itself be the main reason for biased outcomes. Technically speaking, two essential limitations can be found in such model-based approaches: 1) the mitigation cannot be achieved without degrading the accuracy of the machine learning models, and 2) when the data used for training are largely biased, the training time automatically increases so as to find suitable learning parameters that help produce fair results. To address these shortcomings, we propose in this work a new framework that can largely mitigate the biases and discriminations in machine learning systems while at the same time enhancing the prediction accuracy of these systems. The proposed framework is based on conditional Generative Adversarial Networks (cGANs), which are used to generate new synthetic fair data with selective properties from the original data. We also propose a framework for analyzing data biases, which is important for understanding the amount and type of data that need to be synthetically sampled and labeled for each population group. Experimental results show that the proposed solution can efficiently mitigate different types of biases, while at the same time enhancing the prediction accuracy of the underlying machine learning model.