 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRCC-GAN: Regularized Compound Conditional GAN for Large-Scale Tabular Data Synthesis
May 24, 2022
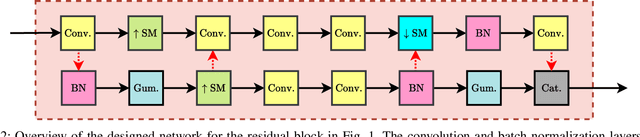
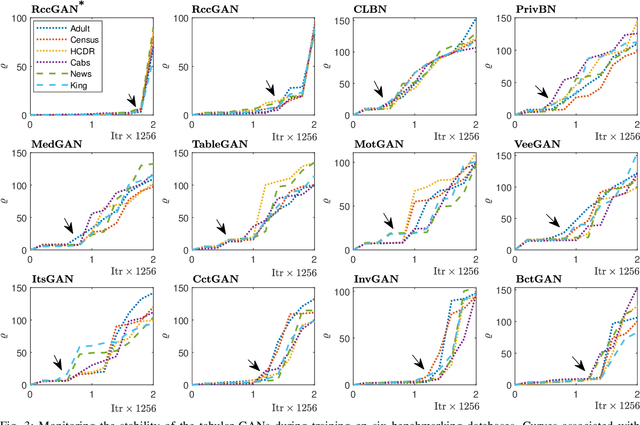
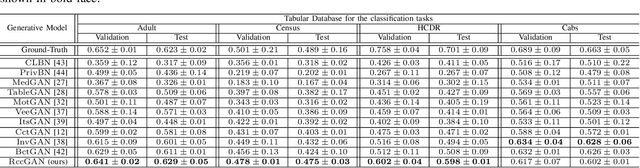
This paper introduces a novel generative adversarial network (GAN) for synthesizing large-scale tabular databases which contain various features such as continuous, discrete, and binary. Technically, our GAN belongs to the category of class-conditioned generative models with a predefined conditional vector. However, we propose a new formulation for deriving such a vector incorporating both binary and discrete features simultaneously. We refer to this noble definition as compound conditional vector and employ it for training the generator network. The core architecture of this network is a three-layered deep residual neural network with skip connections. For improving the stability of such complex architecture, we present a regularization scheme towards limiting unprecedented variations on its weight vectors during training. This regularization approach is quite compatible with the nature of adversarial training and it is not computationally prohibitive in runtime. Furthermore, we constantly monitor the variation of the weight vectors for identifying any potential instabilities or irregularities to measure the strength of our proposed regularizer. Toward this end, we also develop a new metric for tracking sudden perturbation on the weight vectors using the singular value decomposition theory. Finally, we evaluate the performance of our proposed synthesis approach on six benchmarking tabular databases, namely Adult, Census, HCDR, Cabs, News, and King. The achieved results corroborate that for the majority of the cases, our proposed RccGAN outperforms other conventional and modern generative models in terms of accuracy, stability, and reliability.
Bi-Discriminator Class-Conditional Tabular GAN
Dec 02, 2021
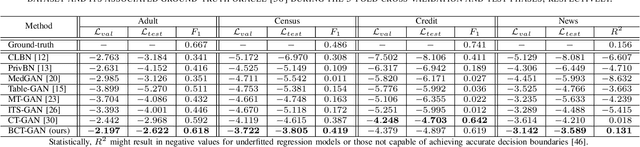
This paper introduces a bi-discriminator GAN for synthesizing tabular datasets containing continuous, binary, and discrete columns. Our proposed approach employs an adapted preprocessing scheme and a novel conditional term for the generator network to more effectively capture the input sample distributions. Additionally, we implement straightforward yet effective architectures for discriminator networks aiming at providing more discriminative gradient information to the generator. Our experimental results on four benchmarking public datasets corroborates the superior performance of our GAN both in terms of likelihood fitness metric and machine learning efficacy.
On the Effectiveness of Interpretable Feedforward Neural Network
Nov 03, 2021
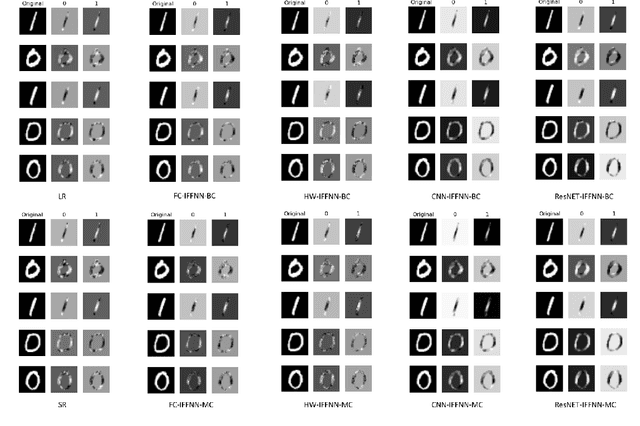


Deep learning models have achieved state-of-the-art performance in many classification tasks. However, most of them cannot provide an interpretation for their classification results. Machine learning models that are interpretable are usually linear or piecewise linear and yield inferior performance. Non-linear models achieve much better classification performance, but it is hard to interpret their classification results. This may have been changed by an interpretable feedforward neural network (IFFNN) proposed that achieves both high classification performance and interpretability for malware detection. If the IFFNN can perform well in a more flexible and general form for other classification tasks while providing meaningful interpretations, it may be of great interest to the applied machine learning community. In this paper, we propose a way to generalize the interpretable feedforward neural network to multi-class classification scenarios and any type of feedforward neural networks, and evaluate its classification performance and interpretability on intrinsic interpretable datasets. We conclude by finding that the generalized IFFNNs achieve comparable classification performance to their normal feedforward neural network counterparts and provide meaningful interpretations. Thus, this kind of neural network architecture has great practical use.
Generative Adversarial Networks for Mitigating Biases in Machine Learning Systems
May 23, 2019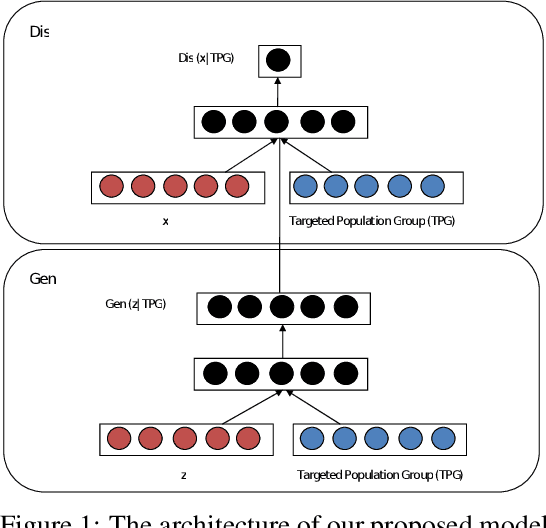


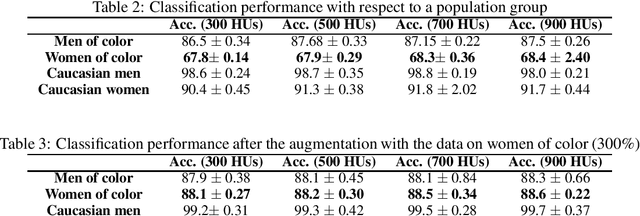
In this paper, we propose a new framework for mitigating biases in machine learning systems. The problem of the existing mitigation approaches is that they are model-oriented in the sense that they focus on tuning the training algorithms to produce fair results, while overlooking the fact that the training data can itself be the main reason for biased outcomes. Technically speaking, two essential limitations can be found in such model-based approaches: 1) the mitigation cannot be achieved without degrading the accuracy of the machine learning models, and 2) when the data used for training are largely biased, the training time automatically increases so as to find suitable learning parameters that help produce fair results. To address these shortcomings, we propose in this work a new framework that can largely mitigate the biases and discriminations in machine learning systems while at the same time enhancing the prediction accuracy of these systems. The proposed framework is based on conditional Generative Adversarial Networks (cGANs), which are used to generate new synthetic fair data with selective properties from the original data. We also propose a framework for analyzing data biases, which is important for understanding the amount and type of data that need to be synthetically sampled and labeled for each population group. Experimental results show that the proposed solution can efficiently mitigate different types of biases, while at the same time enhancing the prediction accuracy of the underlying machine learning model.