Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi-Discriminator Class-Conditional Tabular GAN
Paper and Code

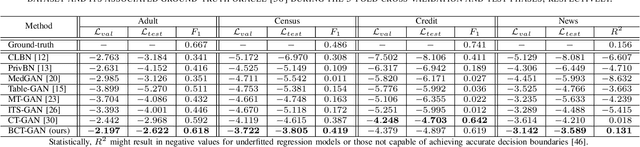
This paper introduces a bi-discriminator GAN for synthesizing tabular datasets containing continuous, binary, and discrete columns. Our proposed approach employs an adapted preprocessing scheme and a novel conditional term for the generator network to more effectively capture the input sample distributions. Additionally, we implement straightforward yet effective architectures for discriminator networks aiming at providing more discriminative gradient information to the generator. Our experimental results on four benchmarking public datasets corroborates the superior performance of our GAN both in terms of likelihood fitness metric and machine learning efficacy.
* Submitted to Elsevier Pattern Recognition Letter
View paper on