 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoALFake: Collaborative Active Learning with Human-LLM Co-Annotation for Cross-Domain Fake News Detection
Apr 05, 2026The proliferation of fake news across diverse domains highlights critical limitations in current detection systems, which often exhibit narrow domain specificity and poor generalization. Existing cross-domain approaches face two key challenges: (1) reliance on labelled data, which is frequently unavailable and resource intensive to acquire and (2) information loss caused by rigid domain categorization or neglect of domain-specific features. To address these issues, we propose CoALFake, a novel approach for cross-domain fake news detection that integrates Human-Large Language Model (LLM) co-annotation with domain-aware Active Learning (AL). Our method employs LLMs for scalable, low-cost annotation while maintaining human oversight to ensure label reliability. By integrating domain embedding techniques, the CoALFake dynamically captures both domain specific nuances and cross-domain patterns, enabling the training of a domain agnostic model. Furthermore, a domain-aware sampling strategy optimizes sample acquisition by prioritizing diverse domain coverage. Experimental results across multiple datasets demonstrate that the proposed approach consistently outperforms various baselines. Our results emphasize that human-LLM co-annotation is a highly cost-effective approach that delivers excellent performance. Evaluations across several datasets show that CoALFake consistently outperforms a range of existing baselines, even with minimal human oversight.
FNDEX: Fake News and Doxxing Detection with Explainable AI
Oct 29, 2024The widespread and diverse online media platforms and other internet-driven communication technologies have presented significant challenges in defining the boundaries of freedom of expression. Consequently, the internet has been transformed into a potential cyber weapon. Within this evolving landscape, two particularly hazardous phenomena have emerged: fake news and doxxing. Although these threats have been subjects of extensive scholarly analysis, the crossroads where they intersect remain unexplored. This research addresses this convergence by introducing a novel system. The Fake News and Doxxing Detection with Explainable Artificial Intelligence (FNDEX) system leverages the capabilities of three distinct transformer models to achieve high-performance detection for both fake news and doxxing. To enhance data security, a rigorous three-step anonymization process is employed, rooted in a pattern-based approach for anonymizing personally identifiable information. Finally, this research emphasizes the importance of generating coherent explanations for the outcomes produced by both detection models. Our experiments on realistic datasets demonstrate that our system significantly outperforms the existing baselines
From Deception to Detection: The Dual Roles of Large Language Models in Fake News
Sep 25, 2024

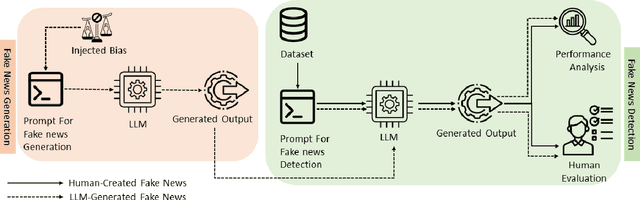

Fake news poses a significant threat to the integrity of information ecosystems and public trust. The advent of Large Language Models (LLMs) holds considerable promise for transforming the battle against fake news. Generally, LLMs represent a double-edged sword in this struggle. One major concern is that LLMs can be readily used to craft and disseminate misleading information on a large scale. This raises the pressing questions: Can LLMs easily generate biased fake news? Do all LLMs have this capability? Conversely, LLMs offer valuable prospects for countering fake news, thanks to their extensive knowledge of the world and robust reasoning capabilities. This leads to other critical inquiries: Can we use LLMs to detect fake news, and do they outperform typical detection models? In this paper, we aim to address these pivotal questions by exploring the performance of various LLMs. Our objective is to explore the capability of various LLMs in effectively combating fake news, marking this as the first investigation to analyze seven such models. Our results reveal that while some models adhere strictly to safety protocols, refusing to generate biased or misleading content, other models can readily produce fake news across a spectrum of biases. Additionally, our results show that larger models generally exhibit superior detection abilities and that LLM-generated fake news are less likely to be detected than human-written ones. Finally, our findings demonstrate that users can benefit from LLM-generated explanations in identifying fake news.
ExFake: Towards an Explainable Fake News Detection Based on Content and Social Context Information
Nov 16, 2023



ExFake is an explainable fake news detection system based on content and context-level information. It is concerned with the veracity analysis of online posts based on their content, social context (i.e., online users' credibility and historical behaviour), and data coming from trusted entities such as fact-checking websites and named entities. Unlike state-of-the-art systems, an Explainable AI (XAI) assistant is also adopted to help online social networks (OSN) users develop good reflexes when faced with any doubted information that spreads on social networks. The trustworthiness of OSN users is also addressed by assigning a credibility score to OSN users, as OSN users are one of the main culprits for spreading fake news. Experimental analysis on a real-world dataset demonstrates that ExFake significantly outperforms other baseline methods for fake news detection.
Towards ethical multimodal systems
Apr 26, 2023

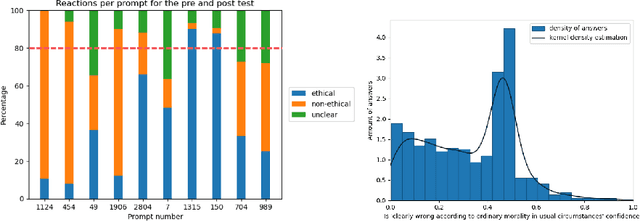
The impact of artificial intelligence systems on our society is increasing at an unprecedented speed. For instance, ChatGPT is being tested in mental health treatment applications such as Koko, Stable Diffusion generates pieces of art competitive with (or outperforming) human artists, and so on. Ethical concerns regarding the behavior and applications of generative AI systems have been increasing over the past years, and the field of AI alignment - steering the behavior of AI systems towards being aligned with human values - is a rapidly growing subfield of modern AI. In this paper, we address the challenges involved in ethical evaluation of a multimodal artificial intelligence system. The multimodal systems we focus on take both text and an image as input and output text, completing the sentence or answering the question asked as input. We perform the evaluation of these models in two steps: we first discus the creation of a multimodal ethical database and then use this database to construct morality-evaluating algorithms. The creation of the multimodal ethical database is done interactively through human feedback. Users are presented with multiple examples and votes on whether they are ethical or not. Once these answers have been aggregated into a dataset, we built and tested different algorithms to automatically evaluate the morality of multimodal systems. These algorithms aim to classify the answers as ethical or not. The models we tested are a RoBERTa-large classifier and a multilayer perceptron classifier.
Generative Adversarial Networks for Mitigating Biases in Machine Learning Systems
May 23, 2019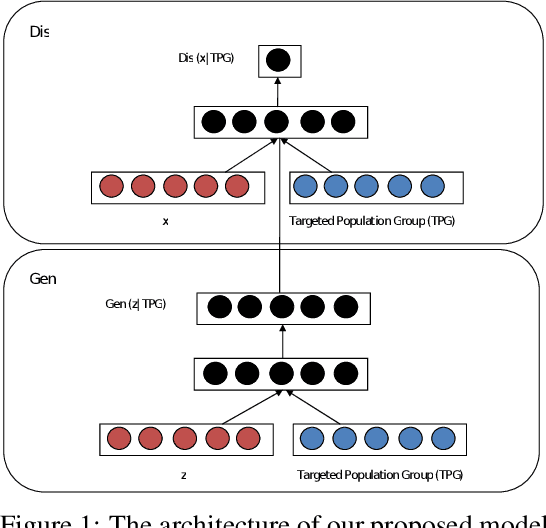


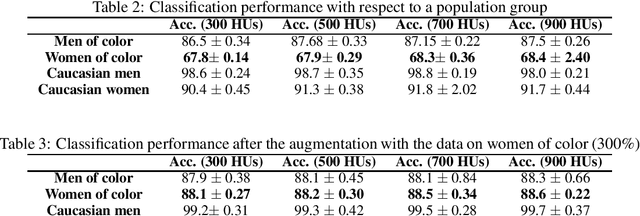
In this paper, we propose a new framework for mitigating biases in machine learning systems. The problem of the existing mitigation approaches is that they are model-oriented in the sense that they focus on tuning the training algorithms to produce fair results, while overlooking the fact that the training data can itself be the main reason for biased outcomes. Technically speaking, two essential limitations can be found in such model-based approaches: 1) the mitigation cannot be achieved without degrading the accuracy of the machine learning models, and 2) when the data used for training are largely biased, the training time automatically increases so as to find suitable learning parameters that help produce fair results. To address these shortcomings, we propose in this work a new framework that can largely mitigate the biases and discriminations in machine learning systems while at the same time enhancing the prediction accuracy of these systems. The proposed framework is based on conditional Generative Adversarial Networks (cGANs), which are used to generate new synthetic fair data with selective properties from the original data. We also propose a framework for analyzing data biases, which is important for understanding the amount and type of data that need to be synthetically sampled and labeled for each population group. Experimental results show that the proposed solution can efficiently mitigate different types of biases, while at the same time enhancing the prediction accuracy of the underlying machine learning model.