 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat do people want to fact-check?
Feb 11, 2026Research on misinformation has focused almost exclusively on supply, asking what falsehoods circulate, who produces them, and whether corrections work. A basic demand-side question remains unanswered. When ordinary people can fact-check anything they want, what do they actually ask about? We provide the first large-scale evidence on this question by analyzing close to 2{,}500 statements submitted by 457 participants to an open-ended AI fact-checking system. Each claim is classified along five semantic dimensions (domain, epistemic form, verifiability, target entity, and temporal reference), producing a behavioral map of public verification demand. Three findings stand out. First, users range widely across topics but default to a narrow epistemic repertoire, overwhelmingly submitting simple descriptive claims about present-day observables. Second, roughly one in four requests concerns statements that cannot be empirically resolved, including moral judgments, speculative predictions, and subjective evaluations, revealing a systematic mismatch between what users seek from fact-checking tools and what such tools can deliver. Third, comparison with the FEVER benchmark dataset exposes sharp structural divergences across all five dimensions, indicating that standard evaluation corpora encode a synthetic claim environment that does not resemble real-world verification needs. These results reframe fact-checking as a demand-driven problem and identify where current AI systems and benchmarks are misaligned with the uncertainty people actually experience.
FNDEX: Fake News and Doxxing Detection with Explainable AI
Oct 29, 2024The widespread and diverse online media platforms and other internet-driven communication technologies have presented significant challenges in defining the boundaries of freedom of expression. Consequently, the internet has been transformed into a potential cyber weapon. Within this evolving landscape, two particularly hazardous phenomena have emerged: fake news and doxxing. Although these threats have been subjects of extensive scholarly analysis, the crossroads where they intersect remain unexplored. This research addresses this convergence by introducing a novel system. The Fake News and Doxxing Detection with Explainable Artificial Intelligence (FNDEX) system leverages the capabilities of three distinct transformer models to achieve high-performance detection for both fake news and doxxing. To enhance data security, a rigorous three-step anonymization process is employed, rooted in a pattern-based approach for anonymizing personally identifiable information. Finally, this research emphasizes the importance of generating coherent explanations for the outcomes produced by both detection models. Our experiments on realistic datasets demonstrate that our system significantly outperforms the existing baselines
From Deception to Detection: The Dual Roles of Large Language Models in Fake News
Sep 25, 2024

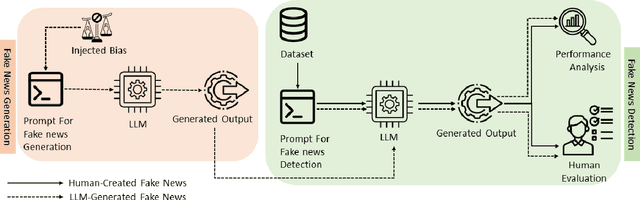

Fake news poses a significant threat to the integrity of information ecosystems and public trust. The advent of Large Language Models (LLMs) holds considerable promise for transforming the battle against fake news. Generally, LLMs represent a double-edged sword in this struggle. One major concern is that LLMs can be readily used to craft and disseminate misleading information on a large scale. This raises the pressing questions: Can LLMs easily generate biased fake news? Do all LLMs have this capability? Conversely, LLMs offer valuable prospects for countering fake news, thanks to their extensive knowledge of the world and robust reasoning capabilities. This leads to other critical inquiries: Can we use LLMs to detect fake news, and do they outperform typical detection models? In this paper, we aim to address these pivotal questions by exploring the performance of various LLMs. Our objective is to explore the capability of various LLMs in effectively combating fake news, marking this as the first investigation to analyze seven such models. Our results reveal that while some models adhere strictly to safety protocols, refusing to generate biased or misleading content, other models can readily produce fake news across a spectrum of biases. Additionally, our results show that larger models generally exhibit superior detection abilities and that LLM-generated fake news are less likely to be detected than human-written ones. Finally, our findings demonstrate that users can benefit from LLM-generated explanations in identifying fake news.