 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComprehensive Review of Reinforcement Learning for Medical Ultrasound Imaging
Mar 19, 2025



Medical Ultrasound (US) imaging has seen increasing demands over the past years, becoming one of the most preferred imaging modalities in clinical practice due to its affordability, portability, and real-time capabilities. However, it faces several challenges that limit its applicability, such as operator dependency, variability in interpretation, and limited resolution, which are amplified by the low availability of trained experts. This calls for the need of autonomous systems that are capable of reducing the dependency on humans for increased efficiency and throughput. Reinforcement Learning (RL) comes as a rapidly advancing field under Artificial Intelligence (AI) that allows the development of autonomous and intelligent agents that are capable of executing complex tasks through rewarded interactions with their environments. Existing surveys on advancements in the US scanning domain predominantly focus on partially autonomous solutions leveraging AI for scanning guidance, organ identification, plane recognition, and diagnosis. However, none of these surveys explore the intersection between the stages of the US process and the recent advancements in RL solutions. To bridge this gap, this review proposes a comprehensive taxonomy that integrates the stages of the US process with the RL development pipeline. This taxonomy not only highlights recent RL advancements in the US domain but also identifies unresolved challenges crucial for achieving fully autonomous US systems. This work aims to offer a thorough review of current research efforts, highlighting the potential of RL in building autonomous US solutions while identifying limitations and opportunities for further advancements in this field.
CACTUS: An Open Dataset and Framework for Automated Cardiac Assessment and Classification of Ultrasound Images Using Deep Transfer Learning
Mar 07, 2025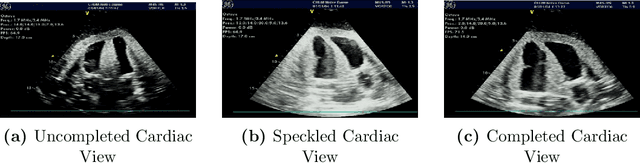
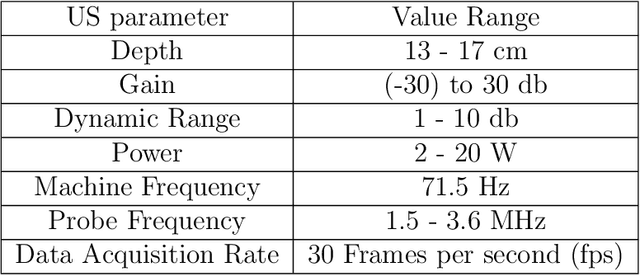
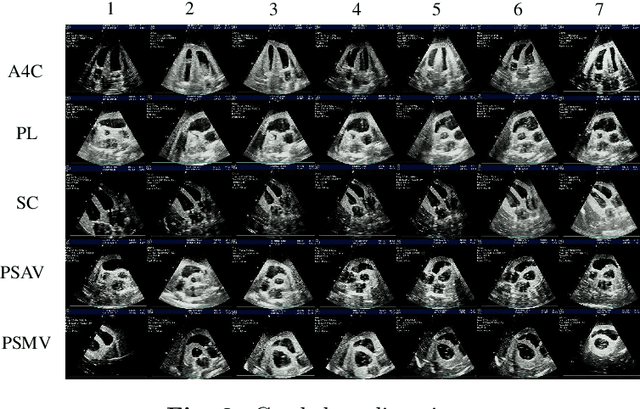
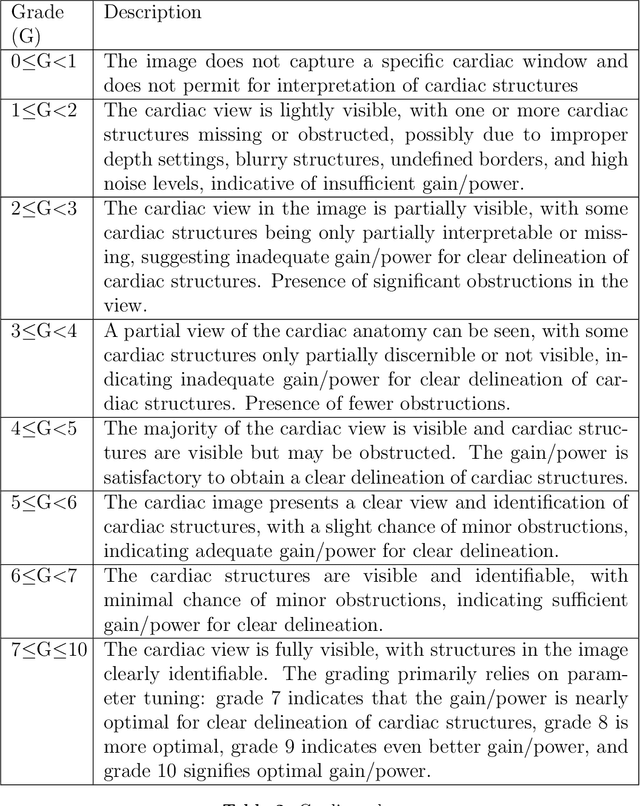
Cardiac ultrasound (US) scanning is a commonly used techniques in cardiology to diagnose the health of the heart and its proper functioning. Therefore, it is necessary to consider ways to automate these tasks and assist medical professionals in classifying and assessing cardiac US images. Machine learning (ML) techniques are regarded as a prominent solution due to their success in numerous applications aimed at enhancing the medical field, including addressing the shortage of echography technicians. However, the limited availability of medical data presents a significant barrier to applying ML in cardiology, particularly regarding US images of the heart. This paper addresses this challenge by introducing the first open graded dataset for Cardiac Assessment and ClassificaTion of UltraSound (CACTUS), which is available online. This dataset contains images obtained from scanning a CAE Blue Phantom and representing various heart views and different quality levels, exceeding the conventional cardiac views typically found in the literature. Additionally, the paper introduces a Deep Learning (DL) framework consisting of two main components. The first component classifies cardiac US images based on the heart view using a Convolutional Neural Network (CNN). The second component uses Transfer Learning (TL) to fine-tune the knowledge from the first component and create a model for grading and assessing cardiac images. The framework demonstrates high performance in both classification and grading, achieving up to 99.43% accuracy and as low as 0.3067 error, respectively. To showcase its robustness, the framework is further fine-tuned using new images representing additional cardiac views and compared to several other state-of-the-art architectures. The framework's outcomes and performance in handling real-time scans were also assessed using a questionnaire answered by cardiac experts.
CRSFL: Cluster-based Resource-aware Split Federated Learning for Continuous Authentication
May 12, 2024
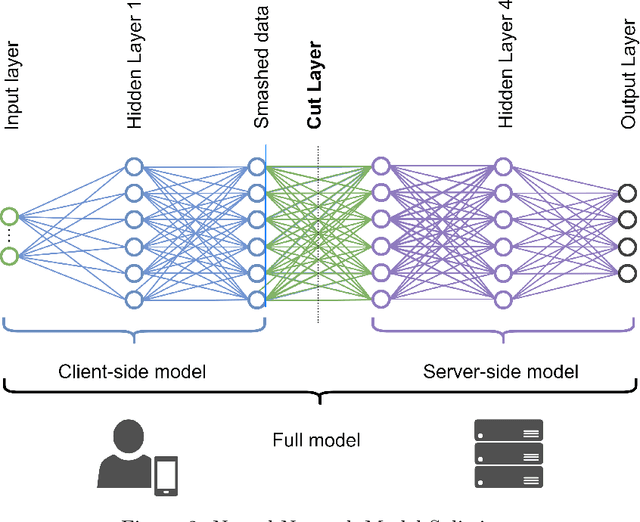

In the ever-changing world of technology, continuous authentication and comprehensive access management are essential during user interactions with a device. Split Learning (SL) and Federated Learning (FL) have recently emerged as promising technologies for training a decentralized Machine Learning (ML) model. With the increasing use of smartphones and Internet of Things (IoT) devices, these distributed technologies enable users with limited resources to complete neural network model training with server assistance and collaboratively combine knowledge between different nodes. In this study, we propose combining these technologies to address the continuous authentication challenge while protecting user privacy and limiting device resource usage. However, the model's training is slowed due to SL sequential training and resource differences between IoT devices with different specifications. Therefore, we use a cluster-based approach to group devices with similar capabilities to mitigate the impact of slow devices while filtering out the devices incapable of training the model. In addition, we address the efficiency and robustness of training ML models by using SL and FL techniques to train the clients simultaneously while analyzing the overhead burden of the process. Following clustering, we select the best set of clients to participate in training through a Genetic Algorithm (GA) optimized on a carefully designed list of objectives. The performance of our proposed framework is compared to baseline methods, and the advantages are demonstrated using a real-life UMDAA-02-FD face detection dataset. The results show that CRSFL, our proposed approach, maintains high accuracy and reduces the overhead burden in continuous authentication scenarios while preserving user privacy.
On-Demand Model and Client Deployment in Federated Learning with Deep Reinforcement Learning
May 12, 2024In Federated Learning (FL), the limited accessibility of data from diverse locations and user types poses a significant challenge due to restricted user participation. Expanding client access and diversifying data enhance models by incorporating diverse perspectives, thereby enhancing adaptability. However, challenges arise in dynamic and mobile environments where certain devices may become inaccessible as FL clients, impacting data availability and client selection methods. To address this, we propose an On-Demand solution, deploying new clients using Docker Containers on-the-fly. Our On-Demand solution, employing Deep Reinforcement Learning (DRL), targets client availability and selection, while considering data shifts, and container deployment complexities. It employs an autonomous end-to-end solution for handling model deployment and client selection. The DRL strategy uses a Markov Decision Process (MDP) framework, with a Master Learner and a Joiner Learner. The designed cost functions represent the complexity of the dynamic client deployment and selection. Simulated tests show that our architecture can easily adjust to changes in the environment and respond to On-Demand requests. This underscores its ability to improve client availability, capability, accuracy, and learning efficiency, surpassing heuristic and tabular reinforcement learning solutions.
The Metaverse: Survey, Trends, Novel Pipeline Ecosystem & Future Directions
Apr 18, 2023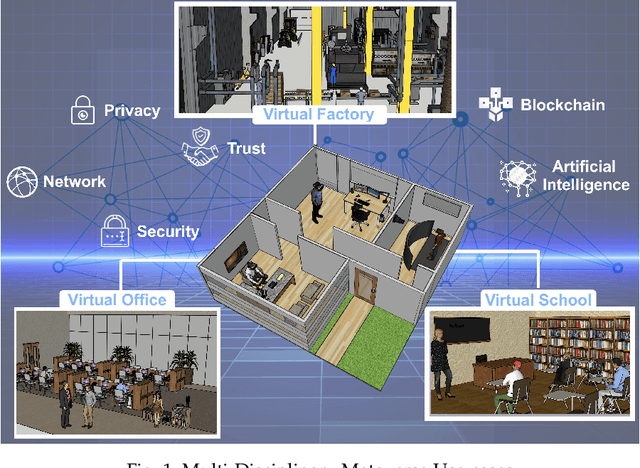

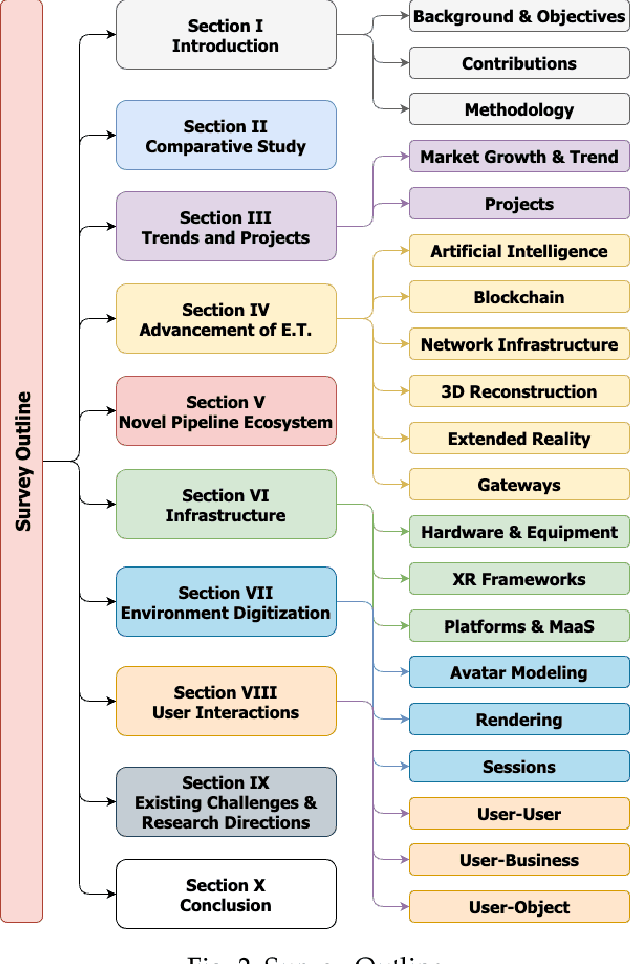

The Metaverse offers a second world beyond reality, where boundaries are non-existent, and possibilities are endless through engagement and immersive experiences using the virtual reality (VR) technology. Many disciplines can benefit from the advancement of the Metaverse when accurately developed, including the fields of technology, gaming, education, art, and culture. Nevertheless, developing the Metaverse environment to its full potential is an ambiguous task that needs proper guidance and directions. Existing surveys on the Metaverse focus only on a specific aspect and discipline of the Metaverse and lack a holistic view of the entire process. To this end, a more holistic, multi-disciplinary, in-depth, and academic and industry-oriented review is required to provide a thorough study of the Metaverse development pipeline. To address these issues, we present in this survey a novel multi-layered pipeline ecosystem composed of (1) the Metaverse computing, networking, communications and hardware infrastructure, (2) environment digitization, and (3) user interactions. For every layer, we discuss the components that detail the steps of its development. Also, for each of these components, we examine the impact of a set of enabling technologies and empowering domains (e.g., Artificial Intelligence, Security & Privacy, Blockchain, Business, Ethics, and Social) on its advancement. In addition, we explain the importance of these technologies to support decentralization, interoperability, user experiences, interactions, and monetization. Our presented study highlights the existing challenges for each component, followed by research directions and potential solutions. To the best of our knowledge, this survey is the most comprehensive and allows users, scholars, and entrepreneurs to get an in-depth understanding of the Metaverse ecosystem to find their opportunities and potentials for contribution.
ON-DEMAND-FL: A Dynamic and Efficient Multi-Criteria Federated Learning Client Deployment Scheme
Nov 05, 2022



In this paper, we increase the availability and integration of devices in the learning process to enhance the convergence of federated learning (FL) models. To address the issue of having all the data in one location, federated learning, which maintains the ability to learn over decentralized data sets, combines privacy and technology. Until the model converges, the server combines the updated weights obtained from each dataset over a number of rounds. The majority of the literature suggested client selection techniques to accelerate convergence and boost accuracy. However, none of the existing proposals have focused on the flexibility to deploy and select clients as needed, wherever and whenever that may be. Due to the extremely dynamic surroundings, some devices are actually not available to serve as clients in FL, which affects the availability of data for learning and the applicability of the existing solution for client selection. In this paper, we address the aforementioned limitations by introducing an On-Demand-FL, a client deployment approach for FL, offering more volume and heterogeneity of data in the learning process. We make use of the containerization technology such as Docker to build efficient environments using IoT and mobile devices serving as volunteers. Furthermore, Kubernetes is used for orchestration. The Genetic algorithm (GA) is used to solve the multi-objective optimization problem due to its evolutionary strategy. The performed experiments using the Mobile Data Challenge (MDC) dataset and the Localfed framework illustrate the relevance of the proposed approach and the efficiency of the on-the-fly deployment of clients whenever and wherever needed with less discarded rounds and more available data.
Reward Shaping Using Convolutional Neural Network
Oct 30, 2022



In this paper, we propose Value Iteration Network for Reward Shaping (VIN-RS), a potential-based reward shaping mechanism using Convolutional Neural Network (CNN). The proposed VIN-RS embeds a CNN trained on computed labels using the message passing mechanism of the Hidden Markov Model. The CNN processes images or graphs of the environment to predict the shaping values. Recent work on reward shaping still has limitations towards training on a representation of the Markov Decision Process (MDP) and building an estimate of the transition matrix. The advantage of VIN-RS is to construct an effective potential function from an estimated MDP while automatically inferring the environment transition matrix. The proposed VIN-RS estimates the transition matrix through a self-learned convolution filter while extracting environment details from the input frames or sampled graphs. Due to (1) the previous success of using message passing for reward shaping; and (2) the CNN planning behavior, we use these messages to train the CNN of VIN-RS. Experiments are performed on tabular games, Atari 2600 and MuJoCo, for discrete and continuous action space. Our results illustrate promising improvements in the learning speed and maximum cumulative reward compared to the state-of-the-art.