 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtlasPatch: An Efficient and Scalable Tool for Whole Slide Image Preprocessing in Computational Pathology
Feb 03, 2026Whole-slide image (WSI) preprocessing, typically comprising tissue detection followed by patch extraction, is foundational to AI-driven computational pathology workflows. This remains a major computational bottleneck as existing tools either rely on inaccurate heuristic thresholding for tissue detection, or adopt AI-based approaches trained on limited-diversity data that operate at the patch level, incurring substantial computational complexity. We present AtlasPatch, an efficient and scalable slide preprocessing framework for accurate tissue detection and high-throughput patch extraction with minimal computational overhead. AtlasPatch's tissue detection module is trained on a heterogeneous and semi-manually annotated dataset of ~30,000 WSI thumbnails, using efficient fine-tuning of the Segment-Anything model. The tool extrapolates tissue masks from thumbnails to full-resolution slides to extract patch coordinates at user-specified magnifications, with options to stream patches directly into common image encoders for embedding or store patch images, all efficiently parallelized across CPUs and GPUs. We assess AtlasPatch across segmentation precision, computational complexity, and downstream multiple-instance learning, matching state-of-the-art performance while operating at a fraction of their computational cost. AtlasPatch is open-source and available at https://github.com/AtlasAnalyticsLab/AtlasPatch.
Comprehensive Review of Reinforcement Learning for Medical Ultrasound Imaging
Mar 19, 2025



Medical Ultrasound (US) imaging has seen increasing demands over the past years, becoming one of the most preferred imaging modalities in clinical practice due to its affordability, portability, and real-time capabilities. However, it faces several challenges that limit its applicability, such as operator dependency, variability in interpretation, and limited resolution, which are amplified by the low availability of trained experts. This calls for the need of autonomous systems that are capable of reducing the dependency on humans for increased efficiency and throughput. Reinforcement Learning (RL) comes as a rapidly advancing field under Artificial Intelligence (AI) that allows the development of autonomous and intelligent agents that are capable of executing complex tasks through rewarded interactions with their environments. Existing surveys on advancements in the US scanning domain predominantly focus on partially autonomous solutions leveraging AI for scanning guidance, organ identification, plane recognition, and diagnosis. However, none of these surveys explore the intersection between the stages of the US process and the recent advancements in RL solutions. To bridge this gap, this review proposes a comprehensive taxonomy that integrates the stages of the US process with the RL development pipeline. This taxonomy not only highlights recent RL advancements in the US domain but also identifies unresolved challenges crucial for achieving fully autonomous US systems. This work aims to offer a thorough review of current research efforts, highlighting the potential of RL in building autonomous US solutions while identifying limitations and opportunities for further advancements in this field.
CACTUS: An Open Dataset and Framework for Automated Cardiac Assessment and Classification of Ultrasound Images Using Deep Transfer Learning
Mar 07, 2025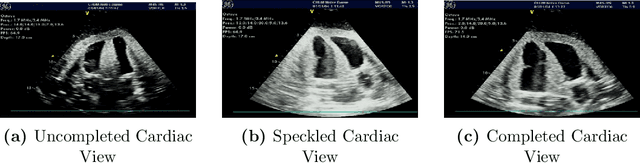
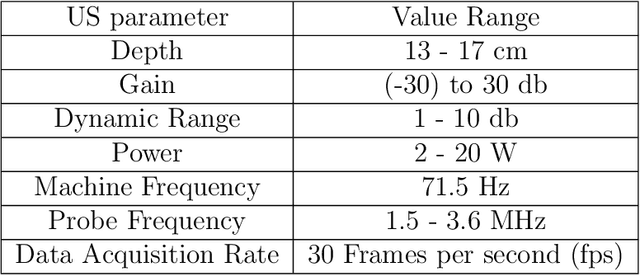
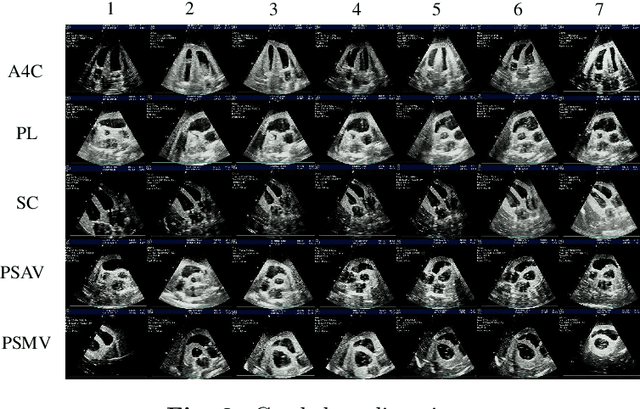
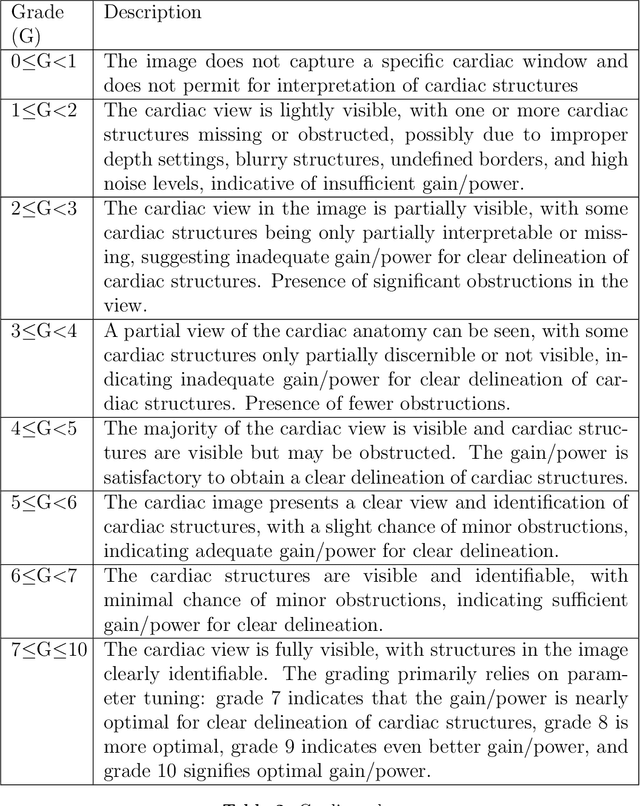
Cardiac ultrasound (US) scanning is a commonly used techniques in cardiology to diagnose the health of the heart and its proper functioning. Therefore, it is necessary to consider ways to automate these tasks and assist medical professionals in classifying and assessing cardiac US images. Machine learning (ML) techniques are regarded as a prominent solution due to their success in numerous applications aimed at enhancing the medical field, including addressing the shortage of echography technicians. However, the limited availability of medical data presents a significant barrier to applying ML in cardiology, particularly regarding US images of the heart. This paper addresses this challenge by introducing the first open graded dataset for Cardiac Assessment and ClassificaTion of UltraSound (CACTUS), which is available online. This dataset contains images obtained from scanning a CAE Blue Phantom and representing various heart views and different quality levels, exceeding the conventional cardiac views typically found in the literature. Additionally, the paper introduces a Deep Learning (DL) framework consisting of two main components. The first component classifies cardiac US images based on the heart view using a Convolutional Neural Network (CNN). The second component uses Transfer Learning (TL) to fine-tune the knowledge from the first component and create a model for grading and assessing cardiac images. The framework demonstrates high performance in both classification and grading, achieving up to 99.43% accuracy and as low as 0.3067 error, respectively. To showcase its robustness, the framework is further fine-tuned using new images representing additional cardiac views and compared to several other state-of-the-art architectures. The framework's outcomes and performance in handling real-time scans were also assessed using a questionnaire answered by cardiac experts.
Adaptive Target Localization under Uncertainty using Multi-Agent Deep Reinforcement Learning with Knowledge Transfer
Jan 19, 2025Target localization is a critical task in sensitive applications, where multiple sensing agents communicate and collaborate to identify the target location based on sensor readings. Existing approaches investigated the use of Multi-Agent Deep Reinforcement Learning (MADRL) to tackle target localization. Nevertheless, these methods do not consider practical uncertainties, like false alarms when the target does not exist or when it is unreachable due to environmental complexities. To address these drawbacks, this work proposes a novel MADRL-based method for target localization in uncertain environments. The proposed MADRL method employs Proximal Policy Optimization to optimize the decision-making of sensing agents, which is represented in the form of an actor-critic structure using Convolutional Neural Networks. The observations of the agents are designed in an optimized manner to capture essential information in the environment, and a team-based reward functions is proposed to produce cooperative agents. The MADRL method covers three action dimensionalities that control the agents' mobility to search the area for the target, detect its existence, and determine its reachability. Using the concept of Transfer Learning, a Deep Learning model builds on the knowledge from the MADRL model to accurately estimating the target location if it is unreachable, resulting in shared representations between the models for faster learning and lower computational complexity. Collectively, the final combined model is capable of searching for the target, determining its existence and reachability, and estimating its location accurately. The proposed method is tested using a radioactive target localization environment and benchmarked against existing methods, showing its efficacy.
Blockchain-assisted Demonstration Cloning for Multi-Agent Deep Reinforcement Learning
Jan 19, 2025



Multi-Agent Deep Reinforcement Learning (MDRL) is a promising research area in which agents learn complex behaviors in cooperative or competitive environments. However, MDRL comes with several challenges that hinder its usability, including sample efficiency, curse of dimensionality, and environment exploration. Recent works proposing Federated Reinforcement Learning (FRL) to tackle these issues suffer from problems related to model restrictions and maliciousness. Other proposals using reward shaping require considerable engineering and could lead to local optima. In this paper, we propose a novel Blockchain-assisted Multi-Expert Demonstration Cloning (MEDC) framework for MDRL. The proposed method utilizes expert demonstrations in guiding the learning of new MDRL agents, by suggesting exploration actions in the environment. A model sharing framework on Blockchain is designed to allow users to share their trained models, which can be allocated as expert models to requesting users to aid in training MDRL systems. A Consortium Blockchain is adopted to enable traceable and autonomous execution without the need for a single trusted entity. Smart Contracts are designed to manage users and models allocation, which are shared using IPFS. The proposed framework is tested on several applications, and is benchmarked against existing methods in FRL, Reward Shaping, and Imitation Learning-assisted RL. The results show the outperformance of the proposed framework in terms of learning speed and resiliency to faulty and malicious models.
CRSFL: Cluster-based Resource-aware Split Federated Learning for Continuous Authentication
May 12, 2024
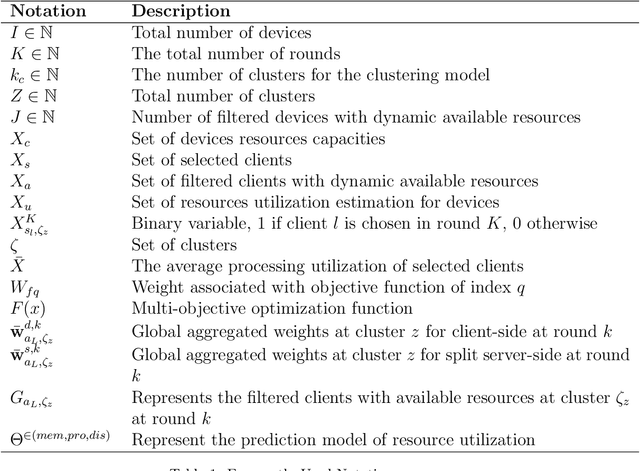

In the ever-changing world of technology, continuous authentication and comprehensive access management are essential during user interactions with a device. Split Learning (SL) and Federated Learning (FL) have recently emerged as promising technologies for training a decentralized Machine Learning (ML) model. With the increasing use of smartphones and Internet of Things (IoT) devices, these distributed technologies enable users with limited resources to complete neural network model training with server assistance and collaboratively combine knowledge between different nodes. In this study, we propose combining these technologies to address the continuous authentication challenge while protecting user privacy and limiting device resource usage. However, the model's training is slowed due to SL sequential training and resource differences between IoT devices with different specifications. Therefore, we use a cluster-based approach to group devices with similar capabilities to mitigate the impact of slow devices while filtering out the devices incapable of training the model. In addition, we address the efficiency and robustness of training ML models by using SL and FL techniques to train the clients simultaneously while analyzing the overhead burden of the process. Following clustering, we select the best set of clients to participate in training through a Genetic Algorithm (GA) optimized on a carefully designed list of objectives. The performance of our proposed framework is compared to baseline methods, and the advantages are demonstrated using a real-life UMDAA-02-FD face detection dataset. The results show that CRSFL, our proposed approach, maintains high accuracy and reduces the overhead burden in continuous authentication scenarios while preserving user privacy.
On-Demand Model and Client Deployment in Federated Learning with Deep Reinforcement Learning
May 12, 2024In Federated Learning (FL), the limited accessibility of data from diverse locations and user types poses a significant challenge due to restricted user participation. Expanding client access and diversifying data enhance models by incorporating diverse perspectives, thereby enhancing adaptability. However, challenges arise in dynamic and mobile environments where certain devices may become inaccessible as FL clients, impacting data availability and client selection methods. To address this, we propose an On-Demand solution, deploying new clients using Docker Containers on-the-fly. Our On-Demand solution, employing Deep Reinforcement Learning (DRL), targets client availability and selection, while considering data shifts, and container deployment complexities. It employs an autonomous end-to-end solution for handling model deployment and client selection. The DRL strategy uses a Markov Decision Process (MDP) framework, with a Master Learner and a Joiner Learner. The designed cost functions represent the complexity of the dynamic client deployment and selection. Simulated tests show that our architecture can easily adjust to changes in the environment and respond to On-Demand requests. This underscores its ability to improve client availability, capability, accuracy, and learning efficiency, surpassing heuristic and tabular reinforcement learning solutions.
Trust Driven On-Demand Scheme for Client Deployment in Federated Learning
May 01, 2024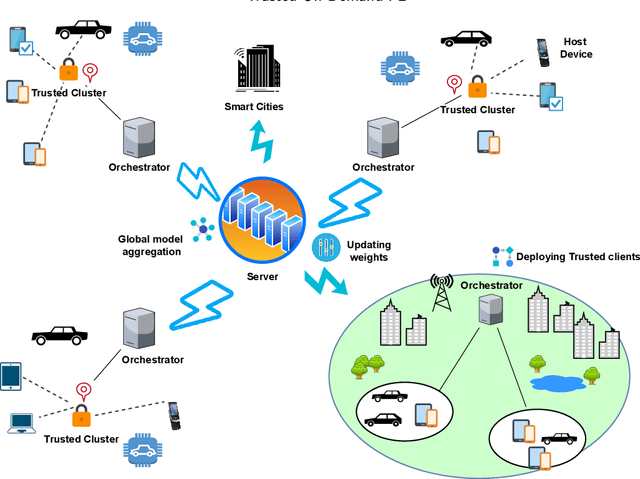
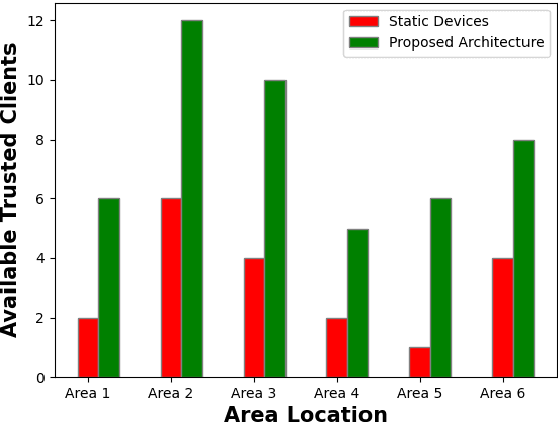
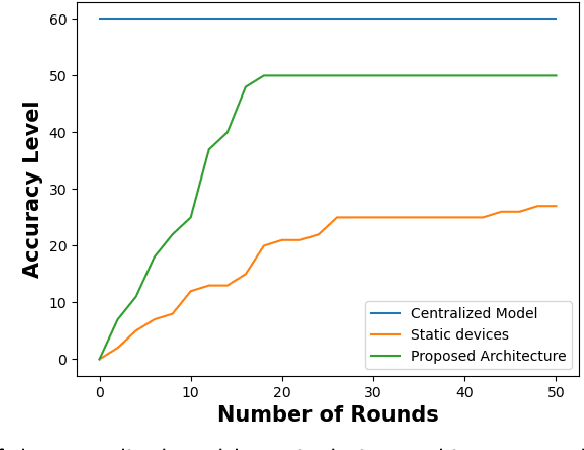
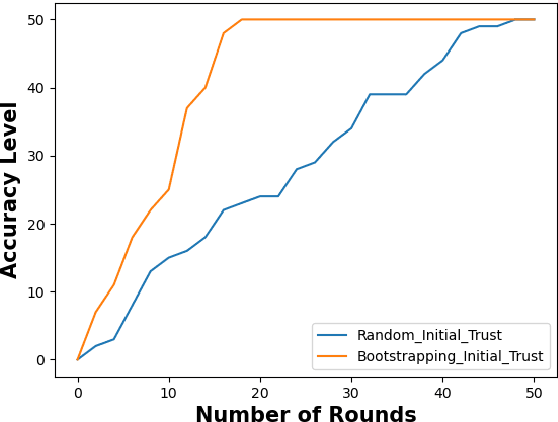
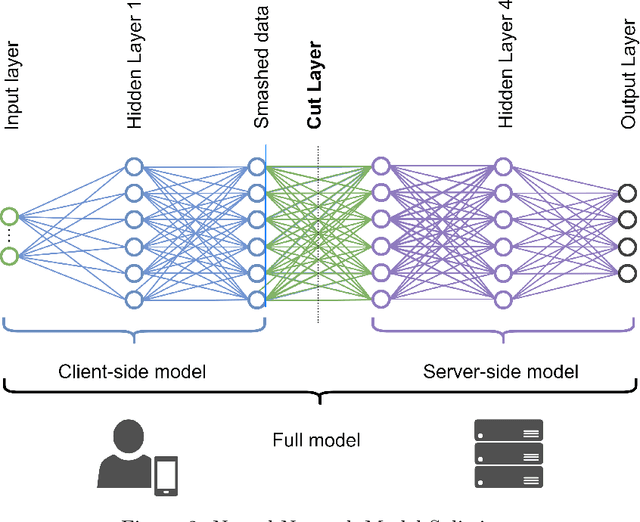
Containerization technology plays a crucial role in Federated Learning (FL) setups, expanding the pool of potential clients and ensuring the availability of specific subsets for each learning iteration. However, doubts arise about the trustworthiness of devices deployed as clients in FL scenarios, especially when container deployment processes are involved. Addressing these challenges is important, particularly in managing potentially malicious clients capable of disrupting the learning process or compromising the entire model. In our research, we are motivated to integrate a trust element into the client selection and model deployment processes within our system architecture. This is a feature lacking in the initial client selection and deployment mechanism of the On-Demand architecture. We introduce a trust mechanism, named "Trusted-On-Demand-FL", which establishes a relationship of trust between the server and the pool of eligible clients. Utilizing Docker in our deployment strategy enables us to monitor and validate participant actions effectively, ensuring strict adherence to agreed-upon protocols while strengthening defenses against unauthorized data access or tampering. Our simulations rely on a continuous user behavior dataset, deploying an optimization model powered by a genetic algorithm to efficiently select clients for participation. By assigning trust values to individual clients and dynamically adjusting these values, combined with penalizing malicious clients through decreased trust scores, our proposed framework identifies and isolates harmful clients. This approach not only reduces disruptions to regular rounds but also minimizes instances of round dismissal, Consequently enhancing both system stability and security.
Enhancing Mutual Trustworthiness in Federated Learning for Data-Rich Smart Cities
May 01, 2024



Federated learning is a promising collaborative and privacy-preserving machine learning approach in data-rich smart cities. Nevertheless, the inherent heterogeneity of these urban environments presents a significant challenge in selecting trustworthy clients for collaborative model training. The usage of traditional approaches, such as the random client selection technique, poses several threats to the system's integrity due to the possibility of malicious client selection. Primarily, the existing literature focuses on assessing the trustworthiness of clients, neglecting the crucial aspect of trust in federated servers. To bridge this gap, in this work, we propose a novel framework that addresses the mutual trustworthiness in federated learning by considering the trust needs of both the client and the server. Our approach entails: (1) Creating preference functions for servers and clients, allowing them to rank each other based on trust scores, (2) Establishing a reputation-based recommendation system leveraging multiple clients to assess newly connected servers, (3) Assigning credibility scores to recommending devices for better server trustworthiness measurement, (4) Developing a trust assessment mechanism for smart devices using a statistical Interquartile Range (IQR) method, (5) Designing intelligent matching algorithms considering the preferences of both parties. Based on simulation and experimental results, our approach outperforms baseline methods by increasing trust levels, global model accuracy, and reducing non-trustworthy clients in the system.
The Metaverse: Survey, Trends, Novel Pipeline Ecosystem & Future Directions
Apr 18, 2023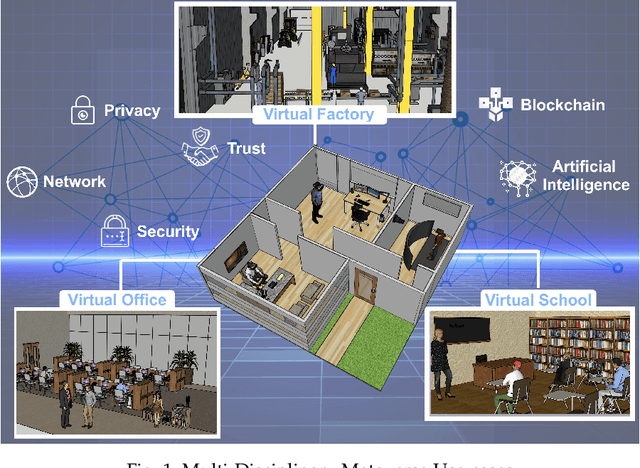

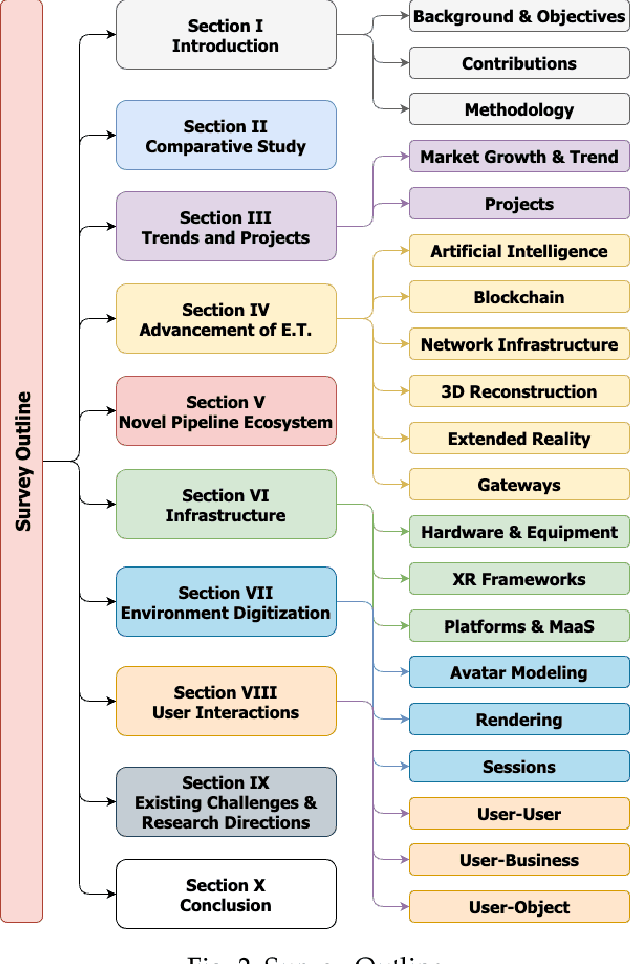

The Metaverse offers a second world beyond reality, where boundaries are non-existent, and possibilities are endless through engagement and immersive experiences using the virtual reality (VR) technology. Many disciplines can benefit from the advancement of the Metaverse when accurately developed, including the fields of technology, gaming, education, art, and culture. Nevertheless, developing the Metaverse environment to its full potential is an ambiguous task that needs proper guidance and directions. Existing surveys on the Metaverse focus only on a specific aspect and discipline of the Metaverse and lack a holistic view of the entire process. To this end, a more holistic, multi-disciplinary, in-depth, and academic and industry-oriented review is required to provide a thorough study of the Metaverse development pipeline. To address these issues, we present in this survey a novel multi-layered pipeline ecosystem composed of (1) the Metaverse computing, networking, communications and hardware infrastructure, (2) environment digitization, and (3) user interactions. For every layer, we discuss the components that detail the steps of its development. Also, for each of these components, we examine the impact of a set of enabling technologies and empowering domains (e.g., Artificial Intelligence, Security & Privacy, Blockchain, Business, Ethics, and Social) on its advancement. In addition, we explain the importance of these technologies to support decentralization, interoperability, user experiences, interactions, and monetization. Our presented study highlights the existing challenges for each component, followed by research directions and potential solutions. To the best of our knowledge, this survey is the most comprehensive and allows users, scholars, and entrepreneurs to get an in-depth understanding of the Metaverse ecosystem to find their opportunities and potentials for contribution.