 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRumour Evaluation with Very Large Language Models
Apr 11, 2024Conversational prompt-engineering-based large language models (LLMs) have enabled targeted control over the output creation, enhancing versatility, adaptability and adhoc retrieval. From another perspective, digital misinformation has reached alarming levels. The anonymity, availability and reach of social media offer fertile ground for rumours to propagate. This work proposes to leverage the advancement of prompting-dependent LLMs to combat misinformation by extending the research efforts of the RumourEval task on its Twitter dataset. To the end, we employ two prompting-based LLM variants (GPT-3.5-turbo and GPT-4) to extend the two RumourEval subtasks: (1) veracity prediction, and (2) stance classification. For veracity prediction, three classifications schemes are experimented per GPT variant. Each scheme is tested in zero-, one- and few-shot settings. Our best results outperform the precedent ones by a substantial margin. For stance classification, prompting-based-approaches show comparable performance to prior results, with no improvement over finetuning methods. Rumour stance subtask is also extended beyond the original setting to allow multiclass classification. All of the generated predictions for both subtasks are equipped with confidence scores determining their trustworthiness degree according to the LLM, and post-hoc justifications for explainability and interpretability purposes. Our primary aim is AI for social good.
Information Retrieval with Entity Linking
Apr 07, 2024Despite the advantages of their low-resource settings, traditional sparse retrievers depend on exact matching approaches between high-dimensional bag-of-words (BoW) representations of both the queries and the collection. As a result, retrieval performance is restricted by semantic discrepancies and vocabulary gaps. On the other hand, transformer-based dense retrievers introduce significant improvements in information retrieval tasks by exploiting low-dimensional contextualized representations of the corpus. While dense retrievers are known for their relative effectiveness, they suffer from lower efficiency and lack of generalization issues, when compared to sparse retrievers. For a lightweight retrieval task, high computational resources and time consumption are major barriers encouraging the renunciation of dense models despite potential gains. In this work, I propose boosting the performance of sparse retrievers by expanding both the queries and the documents with linked entities in two formats for the entity names: 1) explicit and 2) hashed. A zero-shot end-to-end dense entity linking system is employed for entity recognition and disambiguation to augment the corpus. By leveraging the advanced entity linking methods, I believe that the effectiveness gap between sparse and dense retrievers can be narrowed. Experiments are conducted on the MS MARCO passage dataset using the original qrel set, the re-ranked qrels favoured by MonoT5 and the latter set further re-ranked by DuoT5. Since I am concerned with the early stage retrieval in cascaded ranking architectures of large information retrieval systems, the results are evaluated using recall@1000. The suggested approach is also capable of retrieving documents for query subsets judged to be particularly difficult in prior work.
Early Stage Sparse Retrieval with Entity Linking
Aug 10, 2022
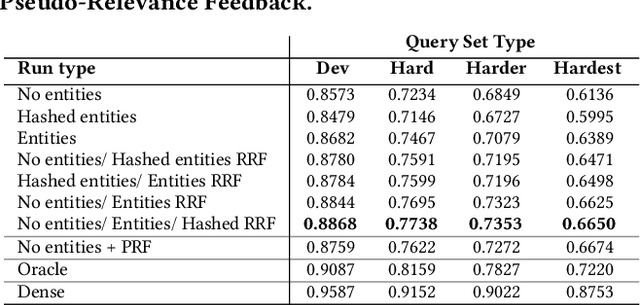
Despite the advantages of their low-resource settings, traditional sparse retrievers depend on exact matching approaches between high-dimensional bag-of-words (BoW) representations of both the queries and the collection. As a result, retrieval performance is restricted by semantic discrepancies and vocabulary gaps. On the other hand, transformer-based dense retrievers introduce significant improvements in information retrieval tasks by exploiting low-dimensional contextualized representations of the corpus. While dense retrievers are known for their relative effectiveness, they suffer from lower efficiency and lack of generalization issues, when compared to sparse retrievers. For a lightweight retrieval task, high computational resources and time consumption are major barriers encouraging the renunciation of dense models despite potential gains. In this work, we propose boosting the performance of sparse retrievers by expanding both the queries and the documents with linked entities in two formats for the entity names: 1) explicit and 2) hashed. We employ a zero-shot end-to-end dense entity linking system for entity recognition and disambiguation to augment the corpus. By leveraging the advanced entity linking methods, we believe that the effectiveness gap between sparse and dense retrievers can be narrowed. We conduct our experiments on the MS MARCO passage dataset. Since we are concerned with the early stage retrieval in cascaded ranking architectures of large information retrieval systems, we evaluate our results using recall@1000. Our approach is also capable of retrieving documents for query subsets judged to be particularly difficult in prior work. We further demonstrate that the non-expanded and the expanded runs with both explicit and hashed entities retrieve complementary results. Consequently, we adopt a run fusion approach to maximize the benefits of entity linking.