 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Evaluation Tropes: Perspectives on the Validity of LLM-Evaluations
Apr 27, 2025Large Language Models (LLMs) are increasingly used to evaluate information retrieval (IR) systems, generating relevance judgments traditionally made by human assessors. Recent empirical studies suggest that LLM-based evaluations often align with human judgments, leading some to suggest that human judges may no longer be necessary, while others highlight concerns about judgment reliability, validity, and long-term impact. As IR systems begin incorporating LLM-generated signals, evaluation outcomes risk becoming self-reinforcing, potentially leading to misleading conclusions. This paper examines scenarios where LLM-evaluators may falsely indicate success, particularly when LLM-based judgments influence both system development and evaluation. We highlight key risks, including bias reinforcement, reproducibility challenges, and inconsistencies in assessment methodologies. To address these concerns, we propose tests to quantify adverse effects, guardrails, and a collaborative framework for constructing reusable test collections that integrate LLM judgments responsibly. By providing perspectives from academia and industry, this work aims to establish best practices for the principled use of LLMs in IR evaluation.
Rumour Evaluation with Very Large Language Models
Apr 11, 2024Conversational prompt-engineering-based large language models (LLMs) have enabled targeted control over the output creation, enhancing versatility, adaptability and adhoc retrieval. From another perspective, digital misinformation has reached alarming levels. The anonymity, availability and reach of social media offer fertile ground for rumours to propagate. This work proposes to leverage the advancement of prompting-dependent LLMs to combat misinformation by extending the research efforts of the RumourEval task on its Twitter dataset. To the end, we employ two prompting-based LLM variants (GPT-3.5-turbo and GPT-4) to extend the two RumourEval subtasks: (1) veracity prediction, and (2) stance classification. For veracity prediction, three classifications schemes are experimented per GPT variant. Each scheme is tested in zero-, one- and few-shot settings. Our best results outperform the precedent ones by a substantial margin. For stance classification, prompting-based-approaches show comparable performance to prior results, with no improvement over finetuning methods. Rumour stance subtask is also extended beyond the original setting to allow multiclass classification. All of the generated predictions for both subtasks are equipped with confidence scores determining their trustworthiness degree according to the LLM, and post-hoc justifications for explainability and interpretability purposes. Our primary aim is AI for social good.
Towards better Human-Agent Alignment: Assessing Task Utility in LLM-Powered Applications
Feb 22, 2024The rapid development in the field of Large Language Models (LLMs) has led to a surge in applications that facilitate collaboration among multiple agents to assist humans in their daily tasks. However, a significant gap remains in assessing whether LLM-powered applications genuinely enhance user experience and task execution efficiency. This highlights the pressing need for methods to verify utility of LLM-powered applications, particularly by ensuring alignment between the application's functionality and end-user needs. We introduce AgentEval provides an implementation for the math problems, a novel framework designed to simplify the utility verification process by automatically proposing a set of criteria tailored to the unique purpose of any given application. This allows for a comprehensive assessment, quantifying the utility of an application against the suggested criteria. We present a comprehensive analysis of the robustness of quantifier's work.
Perspectives on Large Language Models for Relevance Judgment
Apr 13, 2023
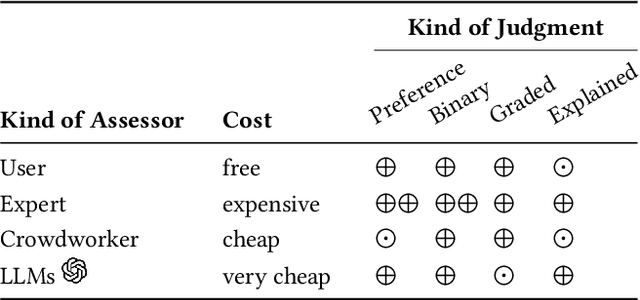

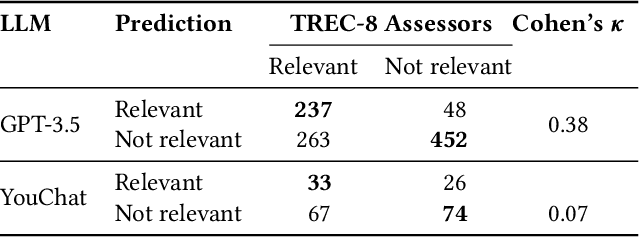
When asked, current large language models (LLMs) like ChatGPT claim that they can assist us with relevance judgments. Many researchers think this would not lead to credible IR research. In this perspective paper, we discuss possible ways for LLMs to assist human experts along with concerns and issues that arise. We devise a human-machine collaboration spectrum that allows categorizing different relevance judgment strategies, based on how much the human relies on the machine. For the extreme point of "fully automated assessment", we further include a pilot experiment on whether LLM-based relevance judgments correlate with judgments from trained human assessors. We conclude the paper by providing two opposing perspectives - for and against the use of LLMs for automatic relevance judgments - and a compromise perspective, informed by our analyses of the literature, our preliminary experimental evidence, and our experience as IR researchers. We hope to start a constructive discussion within the community to avoid a stale-mate during review, where work is dammed if is uses LLMs for evaluation and dammed if it doesn't.