 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Repetition for Mitigating Position Bias in LLM-Based Ranking
Jul 23, 2025


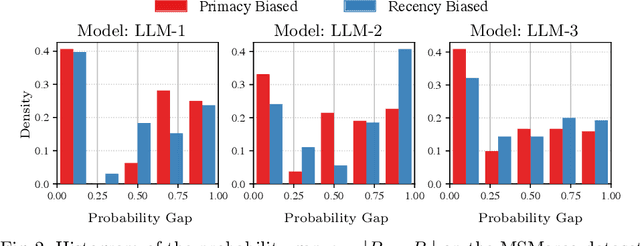
When using LLMs to rank items based on given criteria, or evaluate answers, the order of candidate items can influence the model's final decision. This sensitivity to item positioning in a LLM's prompt is known as position bias. Prior research shows that this bias exists even in large models, though its severity varies across models and tasks. In addition to position bias, LLMs also exhibit varying degrees of low repetition consistency, where repeating the LLM call with the same candidate ordering can lead to different rankings. To address both inconsistencies, a common approach is to prompt the model multiple times with different candidate orderings and aggregate the results via majority voting. However, this repetition strategy, significantly increases computational costs. Extending prior findings, we observe that both the direction -- favoring either the earlier or later candidate in the prompt -- and magnitude of position bias across instances vary substantially, even within a single dataset. This observation highlights the need for a per-instance mitigation strategy. To this end, we introduce a dynamic early-stopping method that adaptively determines the number of repetitions required for each instance. Evaluating our approach across three LLMs of varying sizes and on two tasks, namely re-ranking and alignment, we demonstrate that transitioning to a dynamic repetition strategy reduces the number of LLM calls by an average of 81%, while preserving the accuracy. Furthermore, we propose a confidence-based adaptation to our early-stopping method, reducing LLM calls by an average of 87% compared to static repetition, with only a slight accuracy trade-off relative to our original early-stopping method.
Policy-as-Prompt: Rethinking Content Moderation in the Age of Large Language Models
Feb 25, 2025
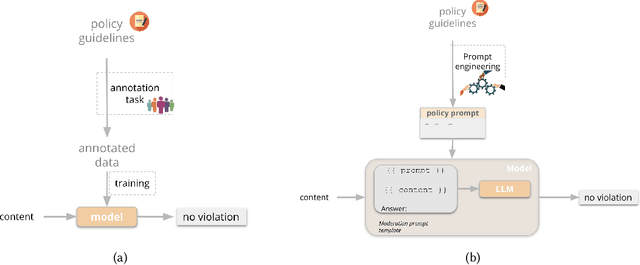

Content moderation plays a critical role in shaping safe and inclusive online environments, balancing platform standards, user expectations, and regulatory frameworks. Traditionally, this process involves operationalising policies into guidelines, which are then used by downstream human moderators for enforcement, or to further annotate datasets for training machine learning moderation models. However, recent advancements in large language models (LLMs) are transforming this landscape. These models can now interpret policies directly as textual inputs, eliminating the need for extensive data curation. This approach offers unprecedented flexibility, as moderation can be dynamically adjusted through natural language interactions. This paradigm shift raises important questions about how policies are operationalised and the implications for content moderation practices. In this paper, we formalise the emerging policy-as-prompt framework and identify five key challenges across four domains: Technical Implementation (1. translating policy to prompts, 2. sensitivity to prompt structure and formatting), Sociotechnical (3. the risk of technological determinism in policy formation), Organisational (4. evolving roles between policy and machine learning teams), and Governance (5. model governance and accountability). Through analysing these challenges across technical, sociotechnical, organisational, and governance dimensions, we discuss potential mitigation approaches. This research provides actionable insights for practitioners and lays the groundwork for future exploration of scalable and adaptive content moderation systems in digital ecosystems.
PODTILE: Facilitating Podcast Episode Browsing with Auto-generated Chapters
Oct 21, 2024


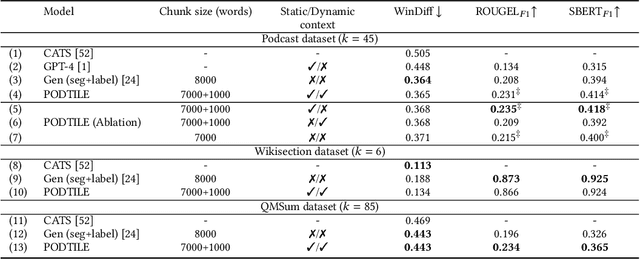
Listeners of long-form talk-audio content, such as podcast episodes, often find it challenging to understand the overall structure and locate relevant sections. A practical solution is to divide episodes into chapters--semantically coherent segments labeled with titles and timestamps. Since most episodes on our platform at Spotify currently lack creator-provided chapters, automating the creation of chapters is essential. Scaling the chapterization of podcast episodes presents unique challenges. First, episodes tend to be less structured than written texts, featuring spontaneous discussions with nuanced transitions. Second, the transcripts are usually lengthy, averaging about 16,000 tokens, which necessitates efficient processing that can preserve context. To address these challenges, we introduce PODTILE, a fine-tuned encoder-decoder transformer to segment conversational data. The model simultaneously generates chapter transitions and titles for the input transcript. To preserve context, each input text is augmented with global context, including the episode's title, description, and previous chapter titles. In our intrinsic evaluation, PODTILE achieved an 11% improvement in ROUGE score over the strongest baseline. Additionally, we provide insights into the practical benefits of auto-generated chapters for listeners navigating episode content. Our findings indicate that auto-generated chapters serve as a useful tool for engaging with less popular podcasts. Finally, we present empirical evidence that using chapter titles can enhance effectiveness of sparse retrieval in search tasks.
When the Music Stops: Tip-of-the-Tongue Retrieval for Music
May 23, 2023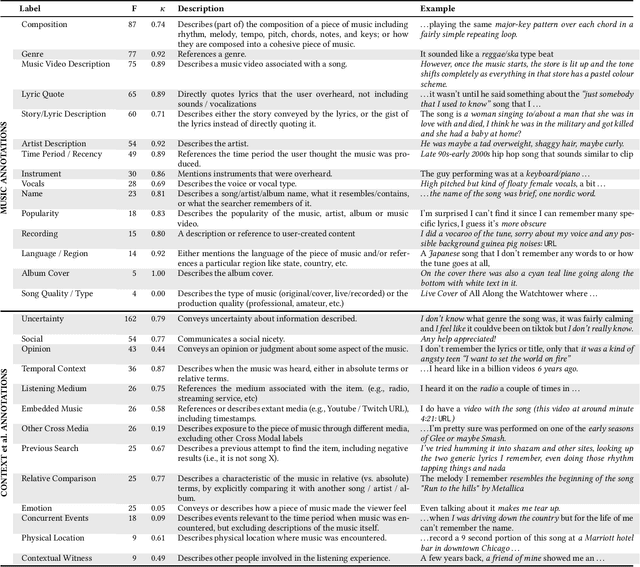
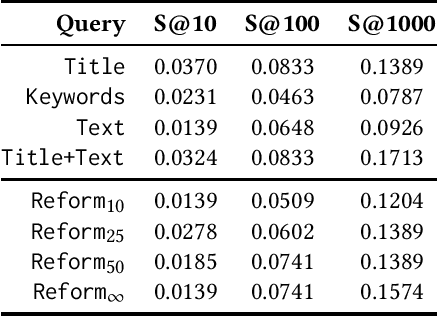
We present a study of Tip-of-the-tongue (ToT) retrieval for music, where a searcher is trying to find an existing music entity, but is unable to succeed as they cannot accurately recall important identifying information. ToT information needs are characterized by complexity, verbosity, uncertainty, and possible false memories. We make four contributions. (1) We collect a dataset - $ToT_{Music}$ - of 2,278 information needs and ground truth answers. (2) We introduce a schema for these information needs and show that they often involve multiple modalities encompassing several Music IR subtasks such as lyric search, audio-based search, audio fingerprinting, and text search. (3) We underscore the difficulty of this task by benchmarking a standard text retrieval approach on this dataset. (4) We investigate the efficacy of query reformulations generated by a large language model (LLM), and show that they are not as effective as simply employing the entire information need as a query - leaving several open questions for future research.
Hear Me Out: A Study on the Use of the Voice Modality for Crowdsourced Relevance Assessments
Apr 21, 2023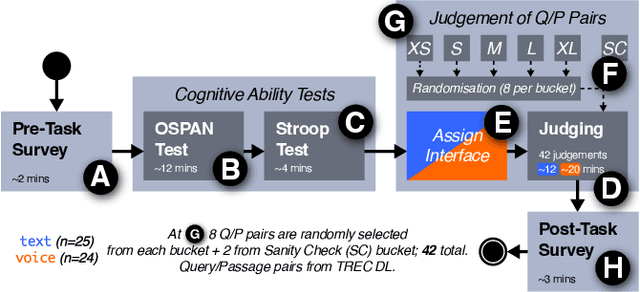
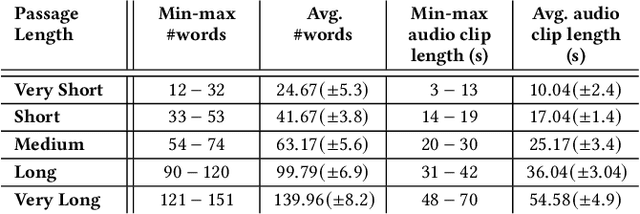


The creation of relevance assessments by human assessors (often nowadays crowdworkers) is a vital step when building IR test collections. Prior works have investigated assessor quality & behaviour, though into the impact of a document's presentation modality on assessor efficiency and effectiveness. Given the rise of voice-based interfaces, we investigate whether it is feasible for assessors to judge the relevance of text documents via a voice-based interface. We ran a user study (n = 49) on a crowdsourcing platform where participants judged the relevance of short and long documents sampled from the TREC Deep Learning corpus-presented to them either in the text or voice modality. We found that: (i) participants are equally accurate in their judgements across both the text and voice modality; (ii) with increased document length it takes participants significantly longer (for documents of length > 120 words it takes almost twice as much time) to make relevance judgements in the voice condition; and (iii) the ability of assessors to ignore stimuli that are not relevant (i.e., inhibition) impacts the assessment quality in the voice modality-assessors with higher inhibition are significantly more accurate than those with lower inhibition. Our results indicate that we can reliably leverage the voice modality as a means to effectively collect relevance labels from crowdworkers.
Perspectives on Large Language Models for Relevance Judgment
Apr 13, 2023
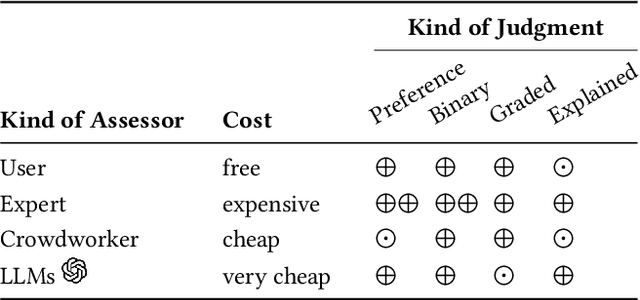

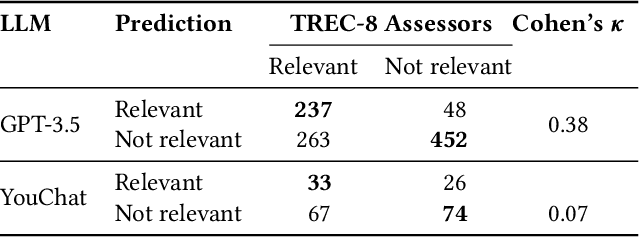
When asked, current large language models (LLMs) like ChatGPT claim that they can assist us with relevance judgments. Many researchers think this would not lead to credible IR research. In this perspective paper, we discuss possible ways for LLMs to assist human experts along with concerns and issues that arise. We devise a human-machine collaboration spectrum that allows categorizing different relevance judgment strategies, based on how much the human relies on the machine. For the extreme point of "fully automated assessment", we further include a pilot experiment on whether LLM-based relevance judgments correlate with judgments from trained human assessors. We conclude the paper by providing two opposing perspectives - for and against the use of LLMs for automatic relevance judgments - and a compromise perspective, informed by our analyses of the literature, our preliminary experimental evidence, and our experience as IR researchers. We hope to start a constructive discussion within the community to avoid a stale-mate during review, where work is dammed if is uses LLMs for evaluation and dammed if it doesn't.
Do the Findings of Document and Passage Retrieval Generalize to the Retrieval of Responses for Dialogues?
Jan 13, 2023

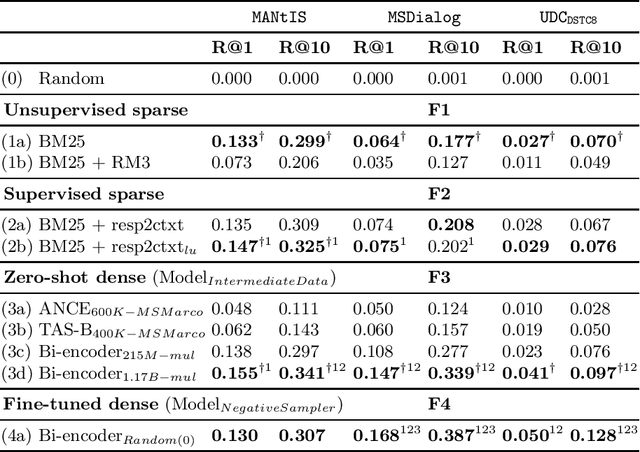

A number of learned sparse and dense retrieval approaches have recently been proposed and proven effective in tasks such as passage retrieval and document retrieval. In this paper we analyze with a replicability study if the lessons learned generalize to the retrieval of responses for dialogues, an important task for the increasingly popular field of conversational search. Unlike passage and document retrieval where documents are usually longer than queries, in response ranking for dialogues the queries (dialogue contexts) are often longer than the documents (responses). Additionally, dialogues have a particular structure, i.e. multiple utterances by different users. With these differences in mind, we here evaluate how generalizable the following major findings from previous works are: (F1) query expansion outperforms a no-expansion baseline; (F2) document expansion outperforms a no-expansion baseline; (F3) zero-shot dense retrieval underperforms sparse baselines; (F4) dense retrieval outperforms sparse baselines; (F5) hard negative sampling is better than random sampling for training dense models. Our experiments -- based on three different information-seeking dialogue datasets -- reveal that four out of five findings (F2-F5) generalize to our domain
Users and Contemporary SERPs: A (Re-)Investigation Examining User Interactions and Experiences
Jul 26, 2022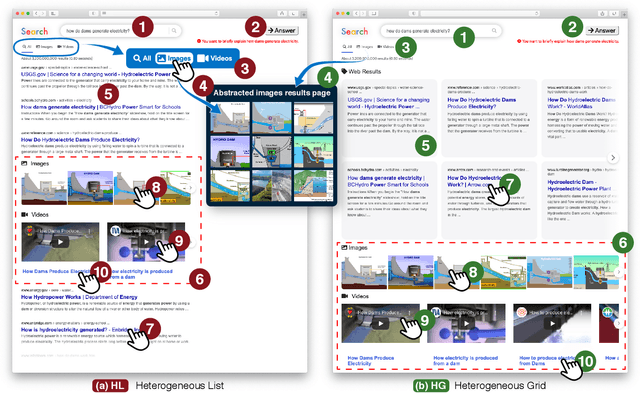
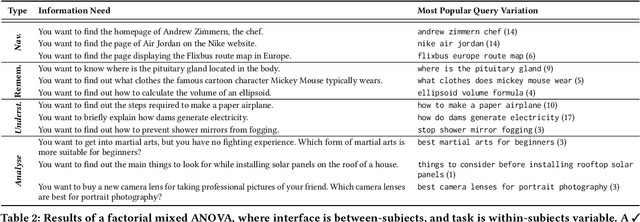

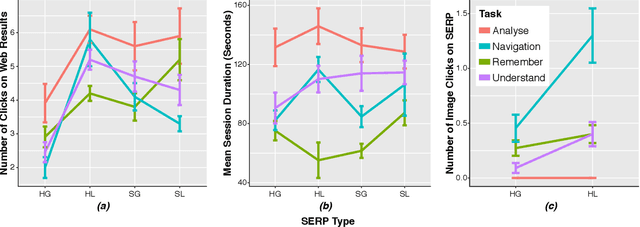
The Search Engine Results Page (SERP) has evolved significantly over the last two decades, moving away from the simple ten blue links paradigm to considerably more complex presentations that contain results from multiple verticals and granularities of textual information. Prior works have investigated how user interactions on the SERP are influenced by the presence or absence of heterogeneous content (e.g., images, videos, or news content), the layout of the SERP (list vs. grid layout), and task complexity. In this paper, we reproduce the user studies conducted in prior works-specifically those of Arguello et al. [4] and Siu and Chaparro [29]-to explore to what extent the findings from research conducted five to ten years ago still hold today as the average web user has become accustomed to SERPs with ever-increasing presentational complexity. To this end, we designed and ran a user study with four different SERP interfaces: (i) a heterogeneous grid; (ii) a heterogeneous list; (iii) a simple grid; and (iv) a simple list. We collected the interactions of 41 study participants over 12 search tasks for our analyses. We observed that SERP types and task complexity affect user interactions with search results. We also find evidence to support most (6 out of 8) observations from [4 , 29] indicating that user interactions with different interfaces and to solve tasks of different complexity have remained mostly similar over time.
* Figure 2 in the SIGIR proceedings version has a mistake---the legends of Remember and Navigation are flipped. This submission has the correct version of the plot
Moving Stuff Around: A study on efficiency of moving documents into memory for Neural IR models
May 17, 2022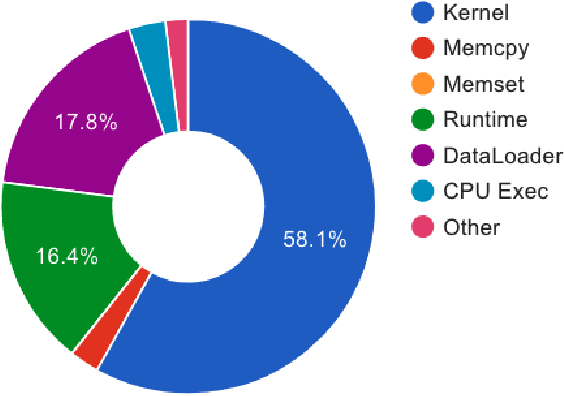



When training neural rankers using Large Language Models, it's expected that a practitioner would make use of multiple GPUs to accelerate the training time. By using more devices, deep learning frameworks, like PyTorch, allow the user to drastically increase the available VRAM pool, making larger batches possible when training, therefore shrinking training time. At the same time, one of the most critical processes, that is generally overlooked when running data-hungry models, is how data is managed between disk, main memory and VRAM. Most open source research implementations overlook this memory hierarchy, and instead resort to loading all documents from disk to main memory and then allowing the framework (e.g., PyTorch) to handle moving data into VRAM. Therefore, with the increasing sizes of datasets dedicated to IR research, a natural question arises: s this the optimal solution for optimizing training time? We here study how three different popular approaches to handling documents for IR datasets behave and how they scale with multiple GPUs. Namely, loading documents directly into memory, reading documents directly from text files with a lookup table and using a library for handling IR datasets (ir_datasets) differ, both in performance (i.e. samples processed per second) and memory footprint. We show that, when using the most popular libraries for neural ranker research (i.e. PyTorch and Hugging Face's Transformers), the practice of loading all documents into main memory is not always the fastest option and is not feasible for setups with more than a couple GPUs. Meanwhile, a good implementation of data streaming from disk can be faster, while being considerably more scalable. We also show how popular techniques for improving loading times, like memory pining, multiple workers, and RAMDISK usage, can reduce the training time further with minor memory overhead.
Sparse and Dense Approaches for the Full-rank Retrieval of Responses for Dialogues
Apr 22, 2022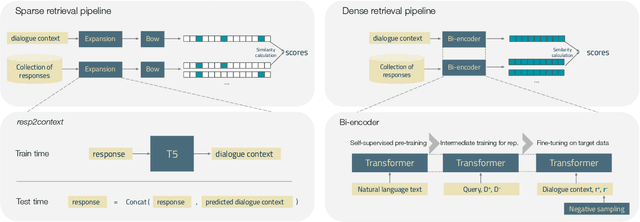
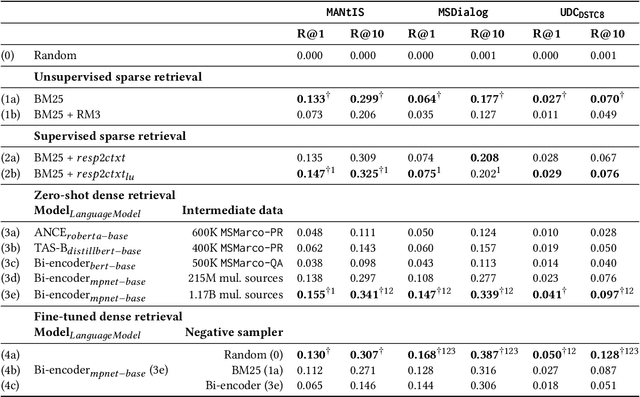
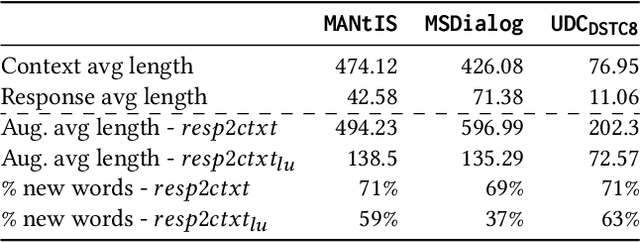
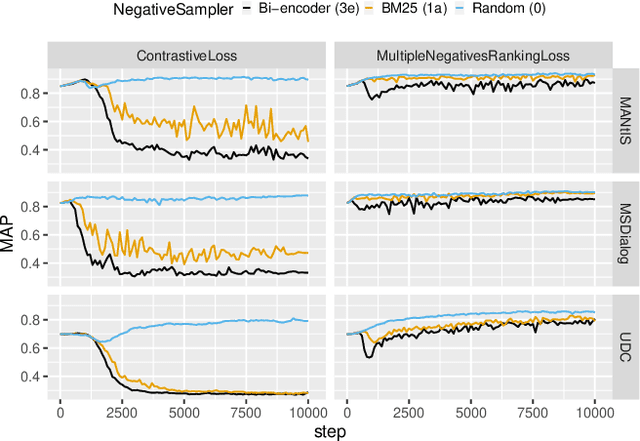
Ranking responses for a given dialogue context is a popular benchmark in which the setup is to re-rank the ground-truth response over a limited set of $n$ responses, where $n$ is typically 10. The predominance of this setup in conversation response ranking has lead to a great deal of attention to building neural re-rankers, while the first-stage retrieval step has been overlooked. Since the correct answer is always available in the candidate list of $n$ responses, this artificial evaluation setup assumes that there is a first-stage retrieval step which is always able to rank the correct response in its top-$n$ list. In this paper we focus on the more realistic task of full-rank retrieval of responses, where $n$ can be up to millions of responses. We investigate both dialogue context and response expansion techniques for sparse retrieval, as well as zero-shot and fine-tuned dense retrieval approaches. Our findings based on three different information-seeking dialogue datasets reveal that a learned response expansion technique is a solid baseline for sparse retrieval. We find the best performing method overall to be dense retrieval with intermediate training, i.e. a step after the language model pre-training where sentence representations are learned, followed by fine-tuning on the target conversational data. We also investigate the intriguing phenomena that harder negatives sampling techniques lead to worse results for the fine-tuned dense retrieval models. The code and datasets are available at https://github.com/Guzpenha/transformer_rankers/tree/full_rank_retrieval_dialogues.