 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoving Stuff Around: A study on efficiency of moving documents into memory for Neural IR models
Paper and Code
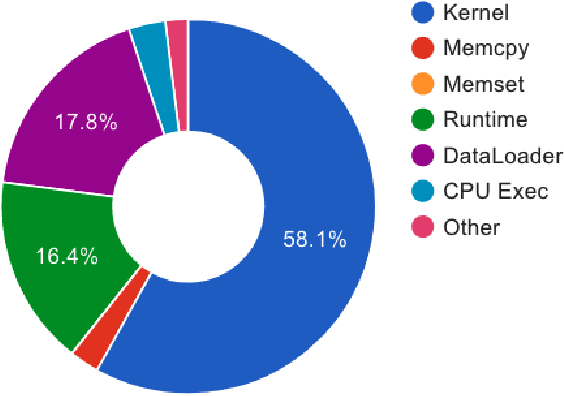



When training neural rankers using Large Language Models, it's expected that a practitioner would make use of multiple GPUs to accelerate the training time. By using more devices, deep learning frameworks, like PyTorch, allow the user to drastically increase the available VRAM pool, making larger batches possible when training, therefore shrinking training time. At the same time, one of the most critical processes, that is generally overlooked when running data-hungry models, is how data is managed between disk, main memory and VRAM. Most open source research implementations overlook this memory hierarchy, and instead resort to loading all documents from disk to main memory and then allowing the framework (e.g., PyTorch) to handle moving data into VRAM. Therefore, with the increasing sizes of datasets dedicated to IR research, a natural question arises: s this the optimal solution for optimizing training time? We here study how three different popular approaches to handling documents for IR datasets behave and how they scale with multiple GPUs. Namely, loading documents directly into memory, reading documents directly from text files with a lookup table and using a library for handling IR datasets (ir_datasets) differ, both in performance (i.e. samples processed per second) and memory footprint. We show that, when using the most popular libraries for neural ranker research (i.e. PyTorch and Hugging Face's Transformers), the practice of loading all documents into main memory is not always the fastest option and is not feasible for setups with more than a couple GPUs. Meanwhile, a good implementation of data streaming from disk can be faster, while being considerably more scalable. We also show how popular techniques for improving loading times, like memory pining, multiple workers, and RAMDISK usage, can reduce the training time further with minor memory overhead.