 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Optimizing Multi-Agent Systems for Deep Research
Apr 03, 2026Given a user's complex information need, a multi-agent Deep Research system iteratively plans, retrieves, and synthesizes evidence across hundreds of documents to produce a high-quality answer. In one possible architecture, an orchestrator agent coordinates the process, while parallel worker agents execute tasks. Current Deep Research systems, however, often rely on hand-engineered prompts and static architectures, making improvement brittle, expensive, and time-consuming. We therefore explore various multi-agent optimization methods to show that enabling agents to self-play and explore different prompt combinations can produce high-quality Deep Research systems that match or outperform expert-crafted prompts.
Evaluating RAG-Fusion with RAGElo: an Automated Elo-based Framework
Jun 20, 2024

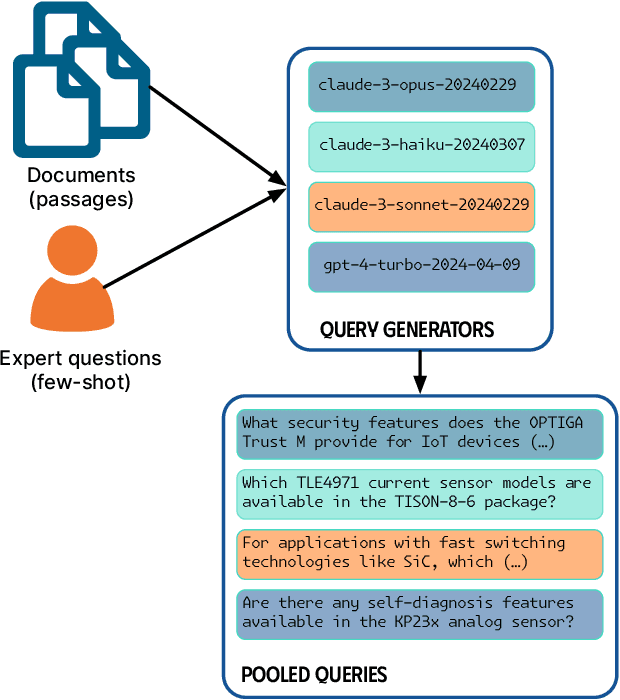

Challenges in the automated evaluation of Retrieval-Augmented Generation (RAG) Question-Answering (QA) systems include hallucination problems in domain-specific knowledge and the lack of gold standard benchmarks for company internal tasks. This results in difficulties in evaluating RAG variations, like RAG-Fusion (RAGF), in the context of a product QA task at Infineon Technologies. To solve these problems, we propose a comprehensive evaluation framework, which leverages Large Language Models (LLMs) to generate large datasets of synthetic queries based on real user queries and in-domain documents, uses LLM-as-a-judge to rate retrieved documents and answers, evaluates the quality of answers, and ranks different variants of Retrieval-Augmented Generation (RAG) agents with RAGElo's automated Elo-based competition. LLM-as-a-judge rating of a random sample of synthetic queries shows a moderate, positive correlation with domain expert scoring in relevance, accuracy, completeness, and precision. While RAGF outperformed RAG in Elo score, a significance analysis against expert annotations also shows that RAGF significantly outperforms RAG in completeness, but underperforms in precision. In addition, Infineon's RAGF assistant demonstrated slightly higher performance in document relevance based on MRR@5 scores. We find that RAGElo positively aligns with the preferences of human annotators, though due caution is still required. Finally, RAGF's approach leads to more complete answers based on expert annotations and better answers overall based on RAGElo's evaluation criteria.
Moving Stuff Around: A study on efficiency of moving documents into memory for Neural IR models
May 17, 2022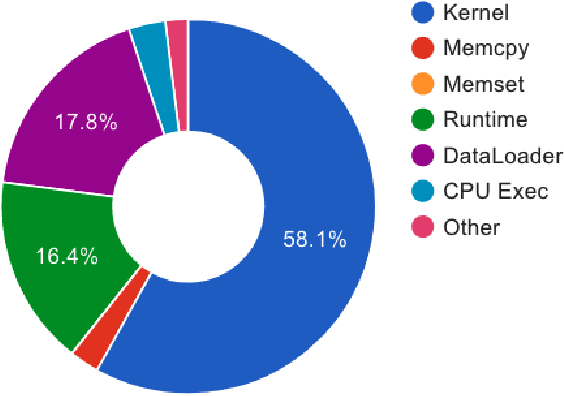



When training neural rankers using Large Language Models, it's expected that a practitioner would make use of multiple GPUs to accelerate the training time. By using more devices, deep learning frameworks, like PyTorch, allow the user to drastically increase the available VRAM pool, making larger batches possible when training, therefore shrinking training time. At the same time, one of the most critical processes, that is generally overlooked when running data-hungry models, is how data is managed between disk, main memory and VRAM. Most open source research implementations overlook this memory hierarchy, and instead resort to loading all documents from disk to main memory and then allowing the framework (e.g., PyTorch) to handle moving data into VRAM. Therefore, with the increasing sizes of datasets dedicated to IR research, a natural question arises: s this the optimal solution for optimizing training time? We here study how three different popular approaches to handling documents for IR datasets behave and how they scale with multiple GPUs. Namely, loading documents directly into memory, reading documents directly from text files with a lookup table and using a library for handling IR datasets (ir_datasets) differ, both in performance (i.e. samples processed per second) and memory footprint. We show that, when using the most popular libraries for neural ranker research (i.e. PyTorch and Hugging Face's Transformers), the practice of loading all documents into main memory is not always the fastest option and is not feasible for setups with more than a couple GPUs. Meanwhile, a good implementation of data streaming from disk can be faster, while being considerably more scalable. We also show how popular techniques for improving loading times, like memory pining, multiple workers, and RAMDISK usage, can reduce the training time further with minor memory overhead.
Searching, Learning, and Subtopic Ordering: A Simulation-based Analysis
Jan 26, 2022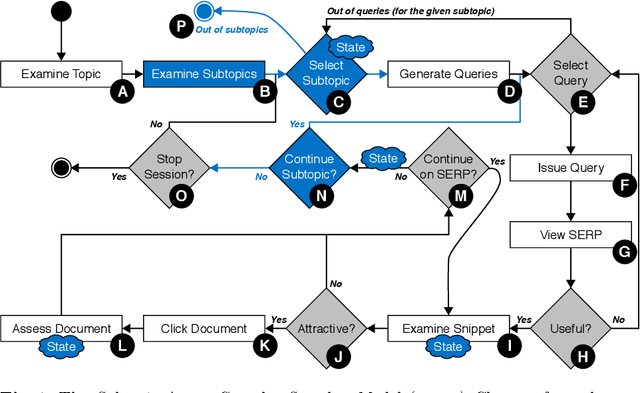

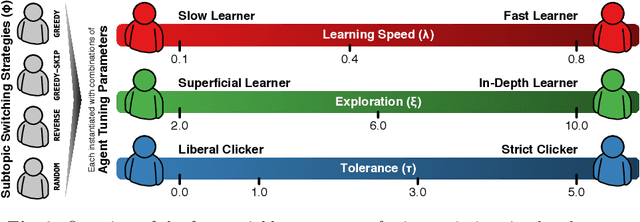
Complex search tasks - such as those from the Search as Learning (SAL) domain - often result in users developing an information need composed of several aspects. However, current models of searcher behaviour assume that individuals have an atomic need, regardless of the task. While these models generally work well for simpler informational needs, we argue that searcher models need to be developed further to allow for the decomposition of a complex search task into multiple aspects. As no searcher model yet exists that considers both aspects and the SAL domain, we propose, by augmenting the Complex Searcher Model (CSM), the Subtopic Aware Complex Searcher Model (SACSM) - modelling aspects as subtopics to the user's need. We then instantiate several agents (i.e., simulated users), with different subtopic selection strategies, which can be considered as different prototypical learning strategies (e.g., should I deeply examine one subtopic at a time, or shallowly cover several subtopics?). Finally, we report on the first large-scale simulated analysis of user behaviours in the SAL domain. Results demonstrate that the SACSM, under certain conditions, simulates user behaviours accurately.
Diagnosing BERT with Retrieval Heuristics
Jan 12, 2022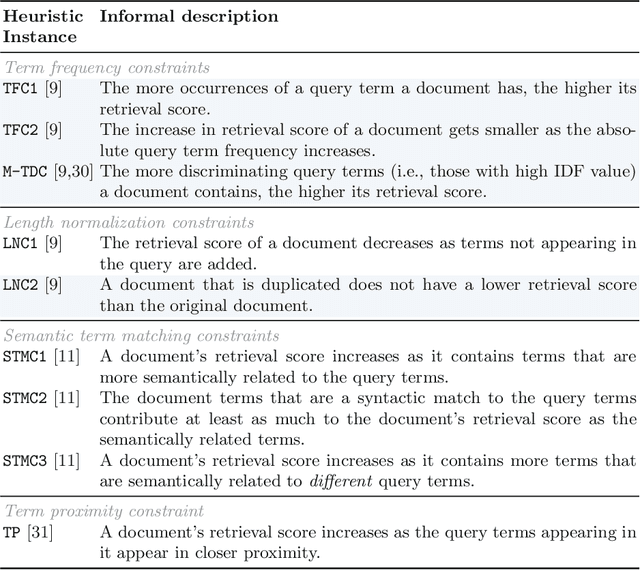
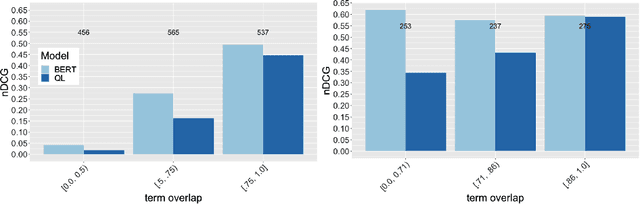


Word embeddings, made widely popular in 2013 with the release of word2vec, have become a mainstay of NLP engineering pipelines. Recently, with the release of BERT, word embeddings have moved from the term-based embedding space to the contextual embedding space -- each term is no longer represented by a single low-dimensional vector but instead each term and \emph{its context} determine the vector weights. BERT's setup and architecture have been shown to be general enough to be applicable to many natural language tasks. Importantly for Information Retrieval (IR), in contrast to prior deep learning solutions to IR problems which required significant tuning of neural net architectures and training regimes, "vanilla BERT" has been shown to outperform existing retrieval algorithms by a wide margin, including on tasks and corpora that have long resisted retrieval effectiveness gains over traditional IR baselines (such as Robust04). In this paper, we employ the recently proposed axiomatic dataset analysis technique -- that is, we create diagnostic datasets that each fulfil a retrieval heuristic (both term matching and semantic-based) -- to explore what BERT is able to learn. In contrast to our expectations, we find BERT, when applied to a recently released large-scale web corpus with ad-hoc topics, to \emph{not} adhere to any of the explored axioms. At the same time, BERT outperforms the traditional query likelihood retrieval model by 40\%. This means that the axiomatic approach to IR (and its extension of diagnostic datasets created for retrieval heuristics) may in its current form not be applicable to large-scale corpora. Additional -- different -- axioms are needed.
* Published at ECIR 2020
Evaluating the Robustness of Retrieval Pipelines with Query Variation Generators
Nov 29, 2021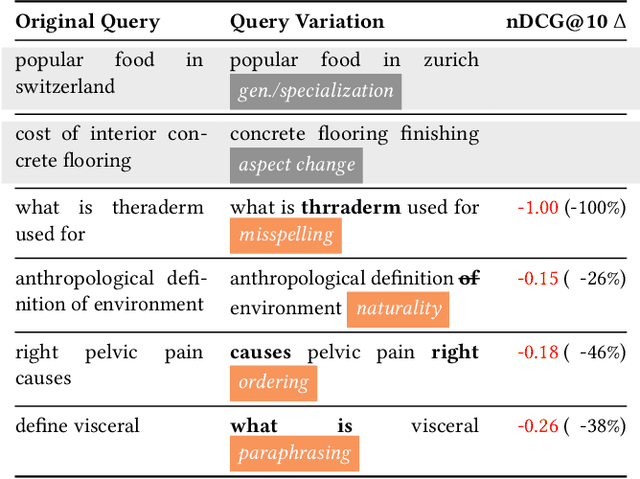
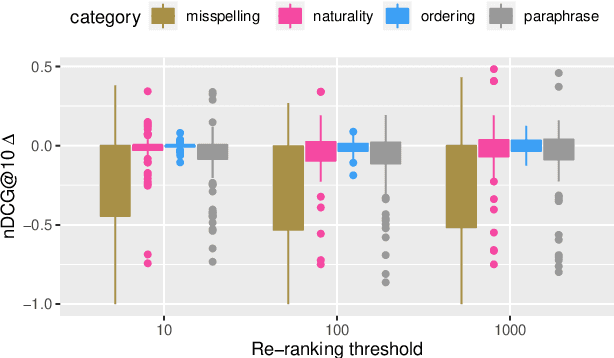
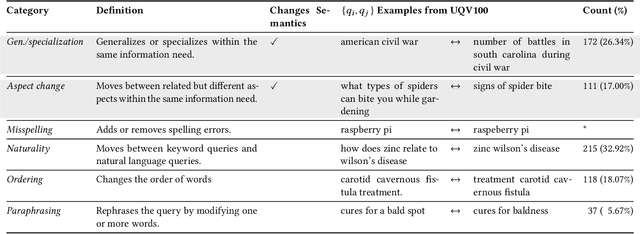
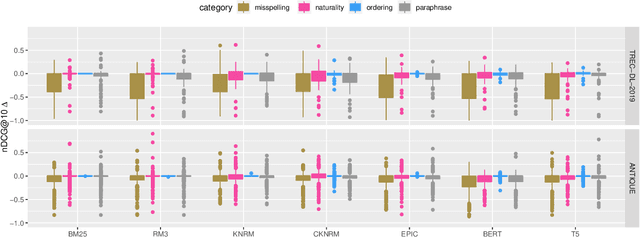
Heavily pre-trained transformers for language modelling, such as BERT, have shown to be remarkably effective for Information Retrieval (IR) tasks, typically applied to re-rank the results of a first-stage retrieval model. IR benchmarks evaluate the effectiveness of retrieval pipelines based on the premise that a single query is used to instantiate the underlying information need. However, previous research has shown that (I) queries generated by users for a fixed information need are extremely variable and, in particular, (II) neural models are brittle and often make mistakes when tested with modified inputs. Motivated by those observations we aim to answer the following question: how robust are retrieval pipelines with respect to different variations in queries that do not change the queries' semantics? In order to obtain queries that are representative of users' querying variability, we first created a taxonomy based on the manual annotation of transformations occurring in a dataset (UQV100) of user-created query variations. For each syntax-changing category of our taxonomy, we employed different automatic methods that when applied to a query generate a query variation. Our experimental results across two datasets for two IR tasks reveal that retrieval pipelines are not robust to these query variations, with effectiveness drops of $\approx20\%$ on average. The code and datasets are available at https://github.com/Guzpenha/query_variation_generators.
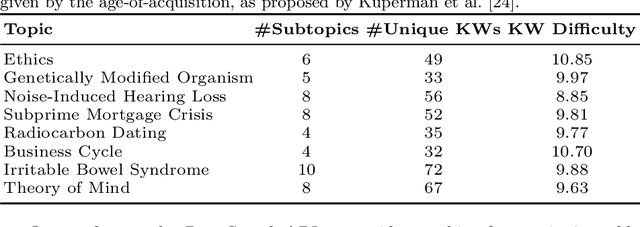
Searching to Learn with Instructional Scaffolding
Nov 29, 2021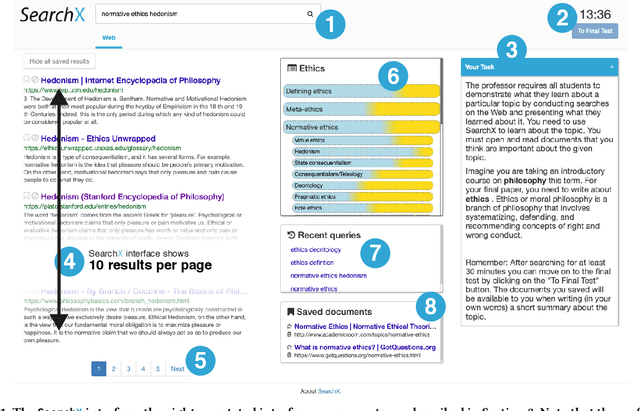


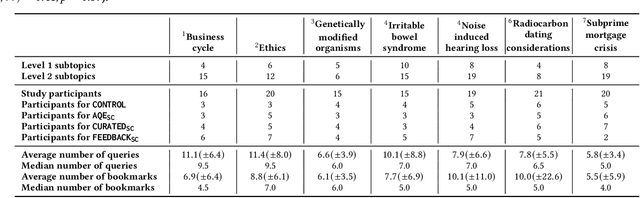
Search engines are considered the primary tool to assist and empower learners in finding information relevant to their learning goals-be it learning something new, improving their existing skills, or just fulfilling a curiosity. While several approaches for improving search engines for the learning scenario have been proposed, instructional scaffolding has not been studied in the context of search as learning, despite being shown to be effective for improving learning in both digital and traditional learning contexts. When scaffolding is employed, instructors provide learners with support throughout their autonomous learning process. We hypothesize that the usage of scaffolding techniques within a search system can be an effective way to help learners achieve their learning objectives whilst searching. As such, this paper investigates the incorporation of scaffolding into a search system employing three different strategies (as well as a control condition): (I) AQE_{SC}, the automatic expansion of user queries with relevant subtopics; (ii) CURATED_{SC}, the presenting of a manually curated static list of relevant subtopics on the search engine result page; and (iii) FEEDBACK_{SC}, which projects real-time feedback about a user's exploration of the topic space on top of the CURATED_{SC} visualization. To investigate the effectiveness of these approaches with respect to human learning, we conduct a user study (N=126) where participants were tasked with searching and learning about topics such as `genetically modified organisms'. We find that (I) the introduction of the proposed scaffolding methods does not significantly improve learning gains. However, (ii) it does significantly impact search behavior. Furthermore, (iii) immediate feedback of the participants' learning leads to undesirable user behavior, with participants focusing on the feedback gauges instead of learning.