 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagnosing BERT with Retrieval Heuristics
Paper and Code
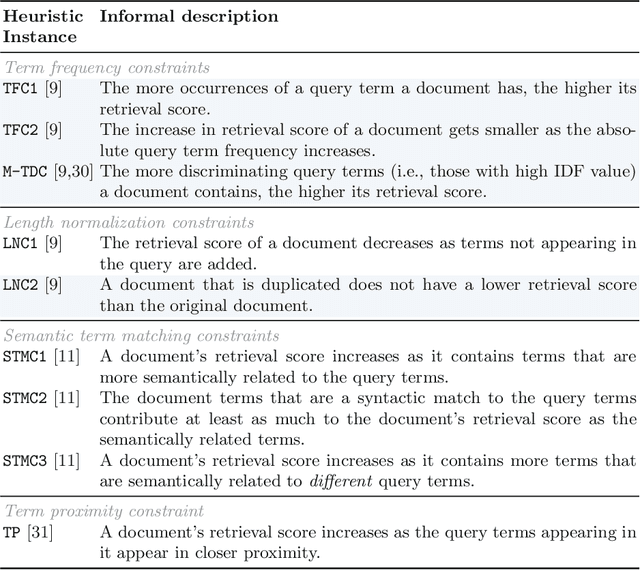
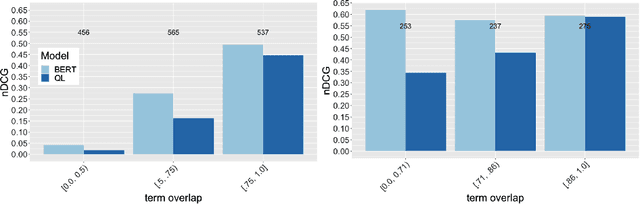


Word embeddings, made widely popular in 2013 with the release of word2vec, have become a mainstay of NLP engineering pipelines. Recently, with the release of BERT, word embeddings have moved from the term-based embedding space to the contextual embedding space -- each term is no longer represented by a single low-dimensional vector but instead each term and \emph{its context} determine the vector weights. BERT's setup and architecture have been shown to be general enough to be applicable to many natural language tasks. Importantly for Information Retrieval (IR), in contrast to prior deep learning solutions to IR problems which required significant tuning of neural net architectures and training regimes, "vanilla BERT" has been shown to outperform existing retrieval algorithms by a wide margin, including on tasks and corpora that have long resisted retrieval effectiveness gains over traditional IR baselines (such as Robust04). In this paper, we employ the recently proposed axiomatic dataset analysis technique -- that is, we create diagnostic datasets that each fulfil a retrieval heuristic (both term matching and semantic-based) -- to explore what BERT is able to learn. In contrast to our expectations, we find BERT, when applied to a recently released large-scale web corpus with ad-hoc topics, to \emph{not} adhere to any of the explored axioms. At the same time, BERT outperforms the traditional query likelihood retrieval model by 40\%. This means that the axiomatic approach to IR (and its extension of diagnostic datasets created for retrieval heuristics) may in its current form not be applicable to large-scale corpora. Additional -- different -- axioms are needed.