 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe:Member: Emotional Question Generation from Personal Memories
Oct 21, 2025We present Re:Member, a system that explores how emotionally expressive, memory-grounded interaction can support more engaging second language (L2) learning. By drawing on users' personal videos and generating stylized spoken questions in the target language, Re:Member is designed to encourage affective recall and conversational engagement. The system aligns emotional tone with visual context, using expressive speech styles such as whispers or late-night tones to evoke specific moods. It combines WhisperX-based transcript alignment, 3-frame visual sampling, and Style-BERT-VITS2 for emotional synthesis within a modular generation pipeline. Designed as a stylized interaction probe, Re:Member highlights the role of affect and personal media in learner-centered educational technologies.
Learning Japanese with Jouzu: Interaction Outcomes with Stylized Dialogue Fictional Agents
Jul 09, 2025This study investigates how stylized, voiced agents shape user interaction in a multimodal language learning environment. We conducted a mixed-methods evaluation of 54 participants interacting with anime-inspired characters powered by large language models and expressive text-to-speech synthesis. These agents responded in Japanese character language, offering users asynchronous, semi-structured conversation in varying speech styles and emotional tones. We analyzed user engagement patterns, perceived usability, emotional responses, and learning behaviors, with particular attention to how agent stylization influenced interaction across language proficiency levels and cultural backgrounds. Our findings reveal that agent design, especially voice, persona, and linguistic style, substantially affected user experience, motivation, and strategy. This work contributes to the understanding of affective, culturally stylized agents in human-agent interaction and offers guidance for designing more engaging, socially responsive systems.
VoxRAG: A Step Toward Transcription-Free RAG Systems in Spoken Question Answering
May 22, 2025

We introduce VoxRAG, a modular speech-to-speech retrieval-augmented generation system that bypasses transcription to retrieve semantically relevant audio segments directly from spoken queries. VoxRAG employs silence-aware segmentation, speaker diarization, CLAP audio embeddings, and FAISS retrieval using L2-normalized cosine similarity. We construct a 50-query test set recorded as spoken input by a native English speaker. Retrieval quality was evaluated using LLM-as-a-judge annotations. For very relevant segments, cosine similarity achieved a Recall@10 of 0.34. For somewhat relevant segments, Recall@10 rose to 0.60 and nDCG@10 to 0.27, highlighting strong topical alignment. Answer quality was judged on a 0--2 scale across relevance, accuracy, completeness, and precision, with mean scores of 0.84, 0.58, 0.56, and 0.46 respectively. While precision and retrieval quality remain key limitations, VoxRAG shows that transcription-free speech-to-speech retrieval is feasible in RAG systems.
Benchmarking Expressive Japanese Character Text-to-Speech with VITS and Style-BERT-VITS2
May 22, 2025



Synthesizing expressive Japanese character speech poses unique challenges due to pitch-accent sensitivity and stylistic variability. This paper benchmarks two open-source text-to-speech models--VITS and Style-BERT-VITS2 JP Extra (SBV2JE)--on in-domain, character-driven Japanese speech. Using three character-specific datasets, we evaluate models across naturalness (mean opinion and comparative mean opinion score), intelligibility (word error rate), and speaker consistency. SBV2JE matches human ground truth in naturalness (MOS 4.37 vs. 4.38), achieves lower WER, and shows slight preference in CMOS. Enhanced by pitch-accent controls and a WavLM-based discriminator, SBV2JE proves effective for applications like language learning and character dialogue generation, despite higher computational demands.
Evaluating RAG-Fusion with RAGElo: an Automated Elo-based Framework
Jun 20, 2024

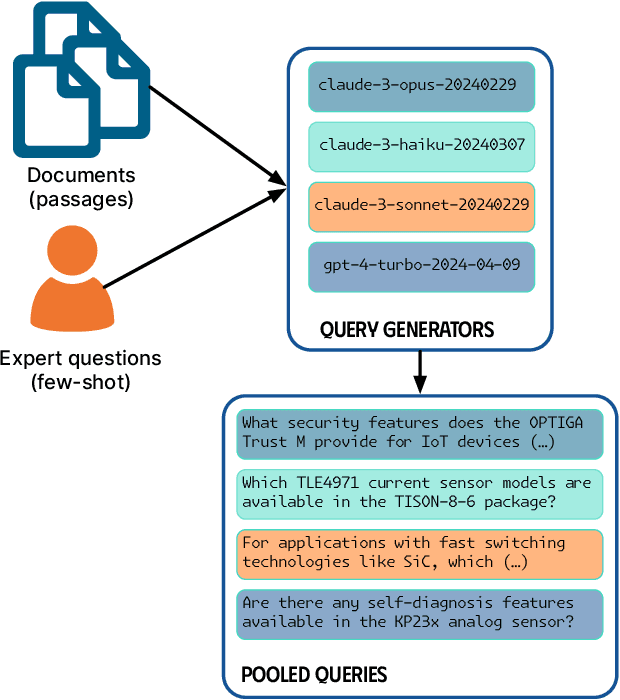

Challenges in the automated evaluation of Retrieval-Augmented Generation (RAG) Question-Answering (QA) systems include hallucination problems in domain-specific knowledge and the lack of gold standard benchmarks for company internal tasks. This results in difficulties in evaluating RAG variations, like RAG-Fusion (RAGF), in the context of a product QA task at Infineon Technologies. To solve these problems, we propose a comprehensive evaluation framework, which leverages Large Language Models (LLMs) to generate large datasets of synthetic queries based on real user queries and in-domain documents, uses LLM-as-a-judge to rate retrieved documents and answers, evaluates the quality of answers, and ranks different variants of Retrieval-Augmented Generation (RAG) agents with RAGElo's automated Elo-based competition. LLM-as-a-judge rating of a random sample of synthetic queries shows a moderate, positive correlation with domain expert scoring in relevance, accuracy, completeness, and precision. While RAGF outperformed RAG in Elo score, a significance analysis against expert annotations also shows that RAGF significantly outperforms RAG in completeness, but underperforms in precision. In addition, Infineon's RAGF assistant demonstrated slightly higher performance in document relevance based on MRR@5 scores. We find that RAGElo positively aligns with the preferences of human annotators, though due caution is still required. Finally, RAGF's approach leads to more complete answers based on expert annotations and better answers overall based on RAGElo's evaluation criteria.
RAG-Fusion: a New Take on Retrieval-Augmented Generation
Jan 31, 2024

Infineon has identified a need for engineers, account managers, and customers to rapidly obtain product information. This problem is traditionally addressed with retrieval-augmented generation (RAG) chatbots, but in this study, I evaluated the use of the newly popularized RAG-Fusion method. RAG-Fusion combines RAG and reciprocal rank fusion (RRF) by generating multiple queries, reranking them with reciprocal scores and fusing the documents and scores. Through manually evaluating answers on accuracy, relevance, and comprehensiveness, I found that RAG-Fusion was able to provide accurate and comprehensive answers due to the generated queries contextualizing the original query from various perspectives. However, some answers strayed off topic when the generated queries' relevance to the original query is insufficient. This research marks significant progress in artificial intelligence (AI) and natural language processing (NLP) applications and demonstrates transformations in a global and multi-industry context.