 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Interpretable Machine Learning Effective at Feature Selection for Neural Learning-to-Rank?
May 13, 2024Neural ranking models have become increasingly popular for real-world search and recommendation systems in recent years. Unlike their tree-based counterparts, neural models are much less interpretable. That is, it is very difficult to understand their inner workings and answer questions like how do they make their ranking decisions? or what document features do they find important? This is particularly disadvantageous since interpretability is highly important for real-world systems. In this work, we explore feature selection for neural learning-to-rank (LTR). In particular, we investigate six widely-used methods from the field of interpretable machine learning (ML) and introduce our own modification, to select the input features that are most important to the ranking behavior. To understand whether these methods are useful for practitioners, we further study whether they contribute to efficiency enhancement. Our experimental results reveal a large feature redundancy in several LTR benchmarks: the local selection method TabNet can achieve optimal ranking performance with less than 10 features; the global methods, particularly our G-L2X, require slightly more selected features, but exhibit higher potential in improving efficiency. We hope that our analysis of these feature selection methods will bring the fields of interpretable ML and LTR closer together.
* Published at ECIR 2024 as a long paper. 13 pages excl. reference, 20 pages incl. reference
Hear Me Out: A Study on the Use of the Voice Modality for Crowdsourced Relevance Assessments
Apr 21, 2023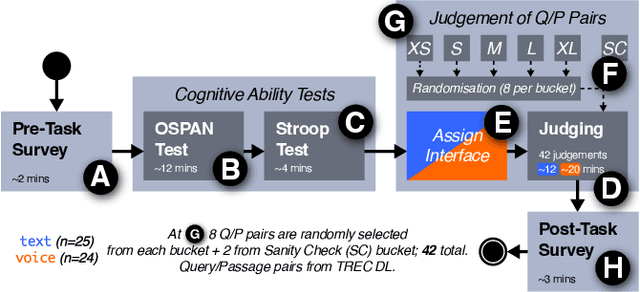
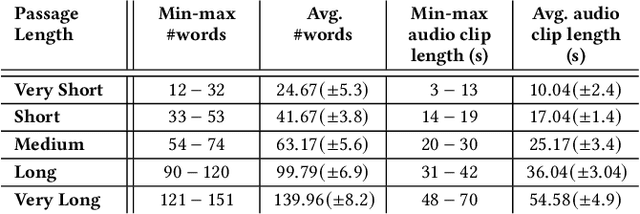


The creation of relevance assessments by human assessors (often nowadays crowdworkers) is a vital step when building IR test collections. Prior works have investigated assessor quality & behaviour, though into the impact of a document's presentation modality on assessor efficiency and effectiveness. Given the rise of voice-based interfaces, we investigate whether it is feasible for assessors to judge the relevance of text documents via a voice-based interface. We ran a user study (n = 49) on a crowdsourcing platform where participants judged the relevance of short and long documents sampled from the TREC Deep Learning corpus-presented to them either in the text or voice modality. We found that: (i) participants are equally accurate in their judgements across both the text and voice modality; (ii) with increased document length it takes participants significantly longer (for documents of length > 120 words it takes almost twice as much time) to make relevance judgements in the voice condition; and (iii) the ability of assessors to ignore stimuli that are not relevant (i.e., inhibition) impacts the assessment quality in the voice modality-assessors with higher inhibition are significantly more accurate than those with lower inhibition. Our results indicate that we can reliably leverage the voice modality as a means to effectively collect relevance labels from crowdworkers.
Users and Contemporary SERPs: A (Re-)Investigation Examining User Interactions and Experiences
Jul 26, 2022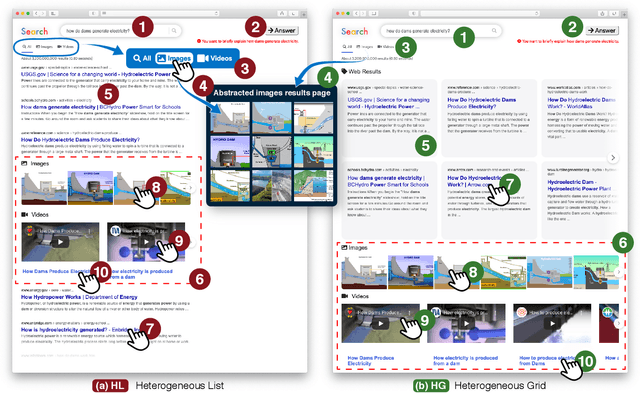
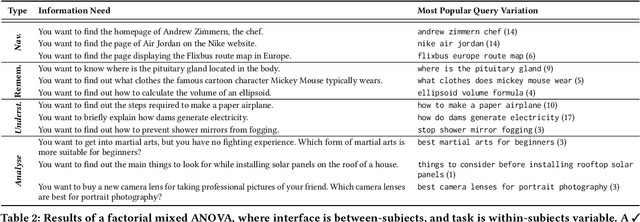

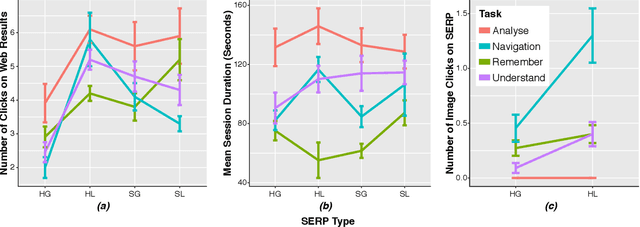
The Search Engine Results Page (SERP) has evolved significantly over the last two decades, moving away from the simple ten blue links paradigm to considerably more complex presentations that contain results from multiple verticals and granularities of textual information. Prior works have investigated how user interactions on the SERP are influenced by the presence or absence of heterogeneous content (e.g., images, videos, or news content), the layout of the SERP (list vs. grid layout), and task complexity. In this paper, we reproduce the user studies conducted in prior works-specifically those of Arguello et al. [4] and Siu and Chaparro [29]-to explore to what extent the findings from research conducted five to ten years ago still hold today as the average web user has become accustomed to SERPs with ever-increasing presentational complexity. To this end, we designed and ran a user study with four different SERP interfaces: (i) a heterogeneous grid; (ii) a heterogeneous list; (iii) a simple grid; and (iv) a simple list. We collected the interactions of 41 study participants over 12 search tasks for our analyses. We observed that SERP types and task complexity affect user interactions with search results. We also find evidence to support most (6 out of 8) observations from [4 , 29] indicating that user interactions with different interfaces and to solve tasks of different complexity have remained mostly similar over time.
* Figure 2 in the SIGIR proceedings version has a mistake---the legends of Remember and Navigation are flipped. This submission has the correct version of the plot
Searching to Learn with Instructional Scaffolding
Nov 29, 2021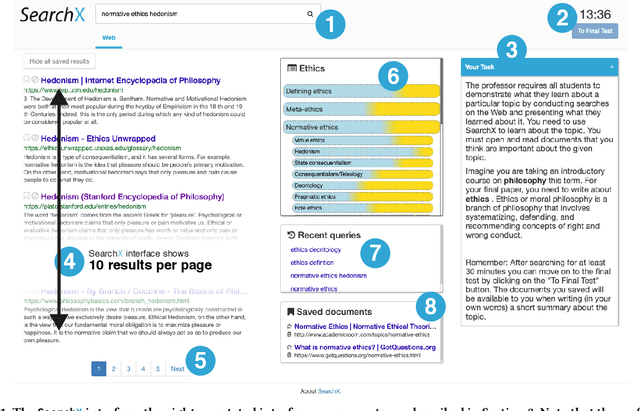


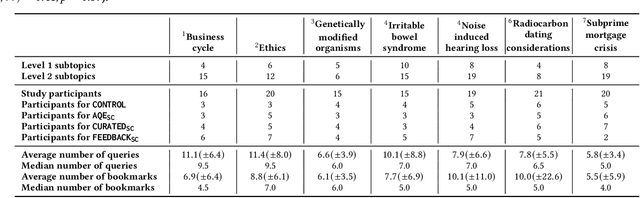
Search engines are considered the primary tool to assist and empower learners in finding information relevant to their learning goals-be it learning something new, improving their existing skills, or just fulfilling a curiosity. While several approaches for improving search engines for the learning scenario have been proposed, instructional scaffolding has not been studied in the context of search as learning, despite being shown to be effective for improving learning in both digital and traditional learning contexts. When scaffolding is employed, instructors provide learners with support throughout their autonomous learning process. We hypothesize that the usage of scaffolding techniques within a search system can be an effective way to help learners achieve their learning objectives whilst searching. As such, this paper investigates the incorporation of scaffolding into a search system employing three different strategies (as well as a control condition): (I) AQE_{SC}, the automatic expansion of user queries with relevant subtopics; (ii) CURATED_{SC}, the presenting of a manually curated static list of relevant subtopics on the search engine result page; and (iii) FEEDBACK_{SC}, which projects real-time feedback about a user's exploration of the topic space on top of the CURATED_{SC} visualization. To investigate the effectiveness of these approaches with respect to human learning, we conduct a user study (N=126) where participants were tasked with searching and learning about topics such as `genetically modified organisms'. We find that (I) the introduction of the proposed scaffolding methods does not significantly improve learning gains. However, (ii) it does significantly impact search behavior. Furthermore, (iii) immediate feedback of the participants' learning leads to undesirable user behavior, with participants focusing on the feedback gauges instead of learning.