 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFollowing the Eye-Tracking Evidence: Established Web-Search Assumptions Fail in Carousel Interfaces
Apr 22, 2026Carousel interfaces have been the de-facto standard for streaming media services for over a decade. Yet, there has been very little research into user behavior with such interfaces, which thus remains poorly understood. Due to this lack of empirical research, previous work has assumed that behaviors established in single-list web-search interfaces, such as the F-pattern and the examination hypothesis, also apply to carousel interfaces, for instance when designing click models or evaluation metrics. We analyze a recently-released interaction and examination dataset resulting from an eye-tracking study performed on carousel interfaces to verify whether these assumptions actually hold. We find that (i)~the F-pattern holds only for vertical examination and not for horizontal swiping; additionally, we discover that, when conditioned on a click, user examination follows an L-pattern unique to carousel interfaces; (ii)~click-through-rates conditioned on examination indicate that the well-known examination hypothesis does not hold in carousel interfaces; and (iii)~contrary to the assumptions of previous work, users generally ignore carousel headings and focus directly on the content items. Our findings show that many user behavior assumptions, especially concerning examination patterns, do not transfer from web search interfaces to carousel recommendation settings. Our work shows that the field lacks a reliable foundation on which to build models of user behavior with these interfaces. Consequently, a re-evaluation of existing metrics and click models for carousel interfaces may be warranted.
A Non-Parametric Choice Model That Learns How Users Choose Between Recommended Options
Jul 26, 2025Choice models predict which items users choose from presented options. In recommendation settings, they can infer user preferences while countering exposure bias. In contrast with traditional univariate recommendation models, choice models consider which competitors appeared with the chosen item. This ability allows them to distinguish whether a user chose an item due to preference, i.e., they liked it; or competition, i.e., it was the best available option. Each choice model assumes specific user behavior, e.g., the multinomial logit model. However, it is currently unclear how accurately these assumptions capture actual user behavior, how wrong assumptions impact inference, and whether better models exist. In this work, we propose the learned choice model for recommendation (LCM4Rec), a non-parametric method for estimating the choice model. By applying kernel density estimation, LCM4Rec infers the most likely error distribution that describes the effect of inter-item cannibalization and thereby characterizes the users' choice model. Thus, it simultaneously infers what users prefer and how they make choices. Our experimental results indicate that our method (i) can accurately recover the choice model underlying a dataset; (ii) provides robust user preference inference, in contrast with existing choice models that are only effective when their assumptions match user behavior; and (iii) is more resistant against exposure bias than existing choice models. Thereby, we show that learning choice models, instead of assuming them, can produce more robust predictions. We believe this work provides an important step towards better understanding users' choice behavior.
RecGaze: The First Eye Tracking and User Interaction Dataset for Carousel Interfaces
Apr 29, 2025Carousel interfaces are widely used in e-commerce and streaming services, but little research has been devoted to them. Previous studies of interfaces for presenting search and recommendation results have focused on single ranked lists, but it appears their results cannot be extrapolated to carousels due to the added complexity. Eye tracking is a highly informative approach to understanding how users click, yet there are no eye tracking studies concerning carousels. There are very few interaction datasets on recommenders with carousel interfaces and none that contain gaze data. We introduce the RecGaze dataset: the first comprehensive feedback dataset on carousels that includes eye tracking results, clicks, cursor movements, and selection explanations. The dataset comprises of interactions from 3 movie selection tasks with 40 different carousel interfaces per user. In total, 87 users and 3,477 interactions are logged. In addition to the dataset, its description and possible use cases, we provide results of a survey on carousel design and the first analysis of gaze data on carousels, which reveals a golden triangle or F-pattern browsing behavior. Our work seeks to advance the field of carousel interfaces by providing the first dataset with eye tracking results on carousels. In this manner, we provide and encourage an empirical understanding of interactions with carousel interfaces, for building better recommender systems through gaze information, and also encourage the development of gaze-based recommenders.
Adaptive Orchestration of Modular Generative Information Access Systems
Apr 24, 2025Advancements in large language models (LLMs) have driven the emergence of complex new systems to provide access to information, that we will collectively refer to as modular generative information access (GenIA) systems. They integrate a broad and evolving range of specialized components, including LLMs, retrieval models, and a heterogeneous set of sources and tools. While modularity offers flexibility, it also raises critical challenges: How can we systematically characterize the space of possible modules and their interactions? How can we automate and optimize interactions among these heterogeneous components? And, how do we enable this modular system to dynamically adapt to varying user query requirements and evolving module capabilities? In this perspective paper, we argue that the architecture of future modular generative information access systems will not just assemble powerful components, but enable a self-organizing system through real-time adaptive orchestration -- where components' interactions are dynamically configured for each user input, maximizing information relevance while minimizing computational overhead. We give provisional answers to the questions raised above with a roadmap that depicts the key principles and methods for designing such an adaptive modular system. We identify pressing challenges, and propose avenues for addressing them in the years ahead. This perspective urges the IR community to rethink modular system designs for developing adaptive, self-optimizing, and future-ready architectures that evolve alongside their rapidly advancing underlying technologies.
Optimizing Compound Retrieval Systems
Apr 16, 2025



Modern retrieval systems do not rely on a single ranking model to construct their rankings. Instead, they generally take a cascading approach where a sequence of ranking models are applied in multiple re-ranking stages. Thereby, they balance the quality of the top-K ranking with computational costs by limiting the number of documents each model re-ranks. However, the cascading approach is not the only way models can interact to form a retrieval system. We propose the concept of compound retrieval systems as a broader class of retrieval systems that apply multiple prediction models. This encapsulates cascading models but also allows other types of interactions than top-K re-ranking. In particular, we enable interactions with large language models (LLMs) which can provide relative relevance comparisons. We focus on the optimization of compound retrieval system design which uniquely involves learning where to apply the component models and how to aggregate their predictions into a final ranking. This work shows how our compound approach can combine the classic BM25 retrieval model with state-of-the-art (pairwise) LLM relevance predictions, while optimizing a given ranking metric and efficiency target. Our experimental results show optimized compound retrieval systems provide better trade-offs between effectiveness and efficiency than cascading approaches, even when applied in a self-supervised manner. With the introduction of compound retrieval systems, we hope to inspire the information retrieval field to more out-of-the-box thinking on how prediction models can interact to form rankings.
A Simpler Alternative to Variational Regularized Counterfactual Risk Minimization
Sep 15, 2024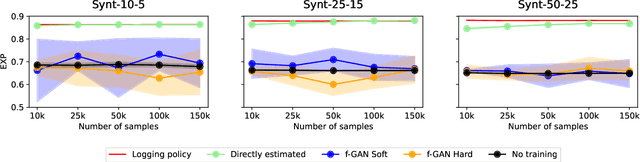

Variance regularized counterfactual risk minimization (VRCRM) has been proposed as an alternative off-policy learning (OPL) method. VRCRM method uses a lower-bound on the $f$-divergence between the logging policy and the target policy as regularization during learning and was shown to improve performance over existing OPL alternatives on multi-label classification tasks. In this work, we revisit the original experimental setting of VRCRM and propose to minimize the $f$-divergence directly, instead of optimizing for the lower bound using a $f$-GAN approach. Surprisingly, we were unable to reproduce the results reported in the original setting. In response, we propose a novel simpler alternative to f-divergence optimization by minimizing a direct approximation of f-divergence directly, instead of a $f$-GAN based lower bound. Experiments showed that minimizing the divergence using $f$-GANs did not work as expected, whereas our proposed novel simpler alternative works better empirically.
Proximal Ranking Policy Optimization for Practical Safety in Counterfactual Learning to Rank
Sep 15, 2024


Counterfactual learning to rank (CLTR) can be risky and, in various circumstances, can produce sub-optimal models that hurt performance when deployed. Safe CLTR was introduced to mitigate these risks when using inverse propensity scoring to correct for position bias. However, the existing safety measure for CLTR is not applicable to state-of-the-art CLTR methods, cannot handle trust bias, and relies on specific assumptions about user behavior. We propose a novel approach, proximal ranking policy optimization (PRPO), that provides safety in deployment without assumptions about user behavior. PRPO removes incentives for learning ranking behavior that is too dissimilar to a safe ranking model. Thereby, PRPO imposes a limit on how much learned models can degrade performance metrics, without relying on any specific user assumptions. Our experiments show that PRPO provides higher performance than the existing safe inverse propensity scoring approach. PRPO always maintains safety, even in maximally adversarial situations. By avoiding assumptions, PRPO is the first method with unconditional safety in deployment that translates to robust safety for real-world applications.
Practical and Robust Safety Guarantees for Advanced Counterfactual Learning to Rank
Jul 29, 2024



Counterfactual learning to rank (CLTR ) can be risky; various circumstances can cause it to produce sub-optimal models that hurt performance when deployed. Safe CLTR was introduced to mitigate these risks when using inverse propensity scoring to correct for position bias. However, the existing safety measure for CLTR is not applicable to state-of-the-art CLTR, it cannot handle trust bias, and its guarantees rely on specific assumptions about user behavior. Our contributions are two-fold. First, we generalize the existing safe CLTR approach to make it applicable to state-of-the-art doubly robust (DR) CLTR and trust bias. Second, we propose a novel approach, proximal ranking policy optimization (PRPO ), that provides safety in deployment without assumptions about user behavior. PRPO removes incentives for learning ranking behavior that is too dissimilar to a safe ranking model. Thereby, PRPO imposes a limit on how much learned models can degrade performance metrics, without relying on any specific user assumptions. Our experiments show that both our novel safe doubly robust method and PRPO provide higher performance than the existing safe inverse propensity scoring approach. However, when circumstances are unexpected, the safe doubly robust approach can become unsafe and bring detrimental performance. In contrast, PRPO always maintains safety, even in maximally adversarial situations. By avoiding assumptions, PRPO is the first method with unconditional safety in deployment that translates to robust safety for real-world applications.
Local Feature Selection without Label or Feature Leakage for Interpretable Machine Learning Predictions
Jul 16, 2024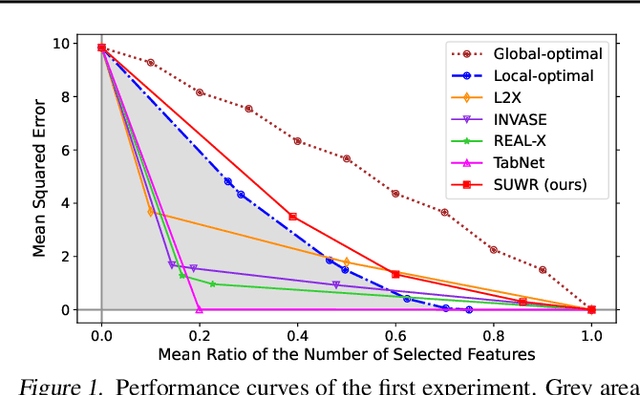
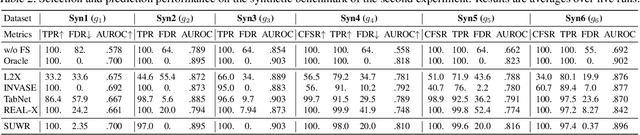

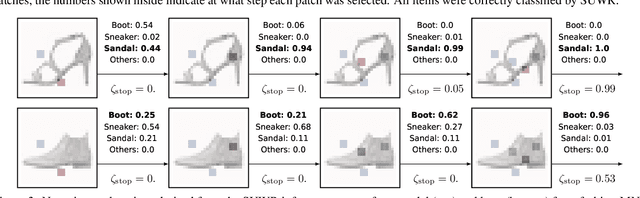
Local feature selection in machine learning provides instance-specific explanations by focusing on the most relevant features for each prediction, enhancing the interpretability of complex models. However, such methods tend to produce misleading explanations by encoding additional information in their selections. In this work, we attribute the problem of misleading selections by formalizing the concepts of label and feature leakage. We rigorously derive the necessary and sufficient conditions under which we can guarantee no leakage, and show existing methods do not meet these conditions. Furthermore, we propose the first local feature selection method that is proven to have no leakage called SUWR. Our experimental results indicate that SUWR is less prone to overfitting and combines state-of-the-art predictive performance with high feature-selection sparsity. Our generic and easily extendable formal approach provides a strong theoretical basis for future work on interpretability with reliable explanations.
Reliable Confidence Intervals for Information Retrieval Evaluation Using Generative A.I
Jul 02, 2024



The traditional evaluation of information retrieval (IR) systems is generally very costly as it requires manual relevance annotation from human experts. Recent advancements in generative artificial intelligence -- specifically large language models (LLMs) -- can generate relevance annotations at an enormous scale with relatively small computational costs. Potentially, this could alleviate the costs traditionally associated with IR evaluation and make it applicable to numerous low-resource applications. However, generated relevance annotations are not immune to (systematic) errors, and as a result, directly using them for evaluation produces unreliable results. In this work, we propose two methods based on prediction-powered inference and conformal risk control that utilize computer-generated relevance annotations to place reliable confidence intervals (CIs) around IR evaluation metrics. Our proposed methods require a small number of reliable annotations from which the methods can statistically analyze the errors in the generated annotations. Using this information, we can place CIs around evaluation metrics with strong theoretical guarantees. Unlike existing approaches, our conformal risk control method is specifically designed for ranking metrics and can vary its CIs per query and document. Our experimental results show that our CIs accurately capture both the variance and bias in evaluation based on LLM annotations, better than the typical empirical bootstrapping estimates. We hope our contributions bring reliable evaluation to the many IR applications where this was traditionally infeasible.