 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Feature Selection without Label or Feature Leakage for Interpretable Machine Learning Predictions
Jul 16, 2024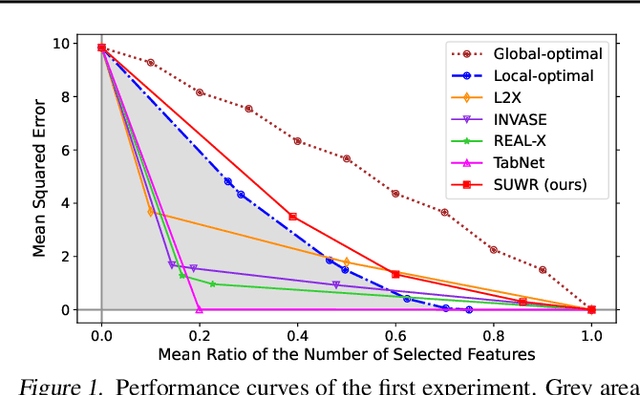
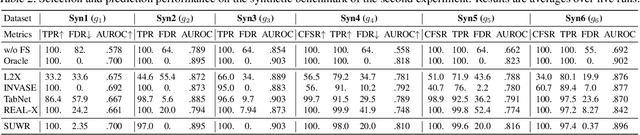

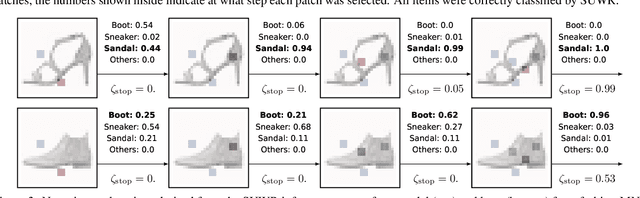
Local feature selection in machine learning provides instance-specific explanations by focusing on the most relevant features for each prediction, enhancing the interpretability of complex models. However, such methods tend to produce misleading explanations by encoding additional information in their selections. In this work, we attribute the problem of misleading selections by formalizing the concepts of label and feature leakage. We rigorously derive the necessary and sufficient conditions under which we can guarantee no leakage, and show existing methods do not meet these conditions. Furthermore, we propose the first local feature selection method that is proven to have no leakage called SUWR. Our experimental results indicate that SUWR is less prone to overfitting and combines state-of-the-art predictive performance with high feature-selection sparsity. Our generic and easily extendable formal approach provides a strong theoretical basis for future work on interpretability with reliable explanations.
Is Interpretable Machine Learning Effective at Feature Selection for Neural Learning-to-Rank?
May 13, 2024Neural ranking models have become increasingly popular for real-world search and recommendation systems in recent years. Unlike their tree-based counterparts, neural models are much less interpretable. That is, it is very difficult to understand their inner workings and answer questions like how do they make their ranking decisions? or what document features do they find important? This is particularly disadvantageous since interpretability is highly important for real-world systems. In this work, we explore feature selection for neural learning-to-rank (LTR). In particular, we investigate six widely-used methods from the field of interpretable machine learning (ML) and introduce our own modification, to select the input features that are most important to the ranking behavior. To understand whether these methods are useful for practitioners, we further study whether they contribute to efficiency enhancement. Our experimental results reveal a large feature redundancy in several LTR benchmarks: the local selection method TabNet can achieve optimal ranking performance with less than 10 features; the global methods, particularly our G-L2X, require slightly more selected features, but exhibit higher potential in improving efficiency. We hope that our analysis of these feature selection methods will bring the fields of interpretable ML and LTR closer together.
* Published at ECIR 2024 as a long paper. 13 pages excl. reference, 20 pages incl. reference
Explainable Information Retrieval: A Survey
Nov 04, 2022Explainable information retrieval is an emerging research area aiming to make transparent and trustworthy information retrieval systems. Given the increasing use of complex machine learning models in search systems, explainability is essential in building and auditing responsible information retrieval models. This survey fills a vital gap in the otherwise topically diverse literature of explainable information retrieval. It categorizes and discusses recent explainability methods developed for different application domains in information retrieval, providing a common framework and unifying perspectives. In addition, it reflects on the common concern of evaluating explanations and highlights open challenges and opportunities.
BERT Rankers are Brittle: a Study using Adversarial Document Perturbations
Jun 23, 2022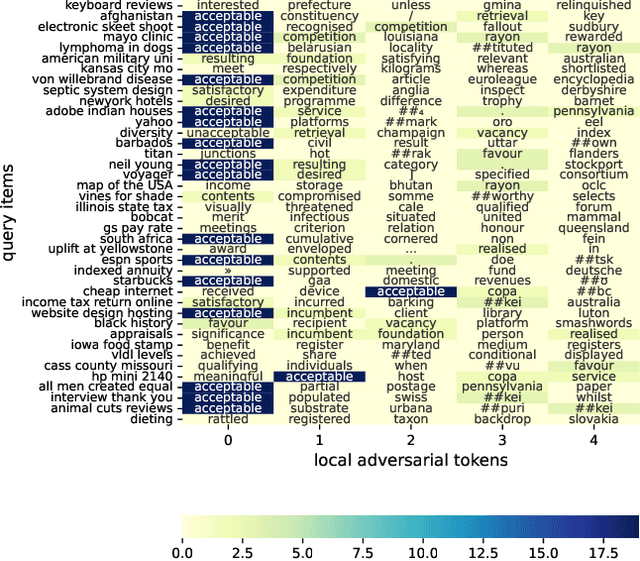
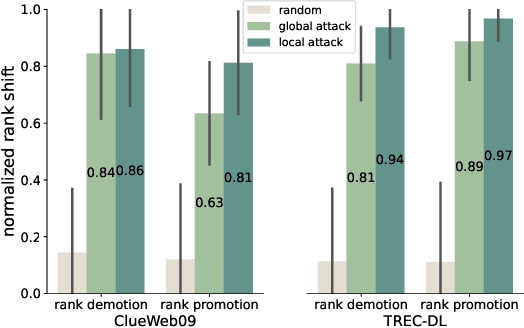
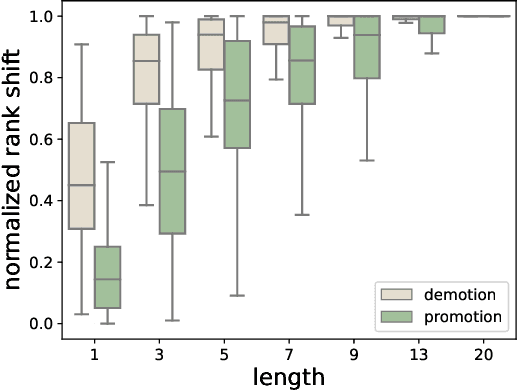
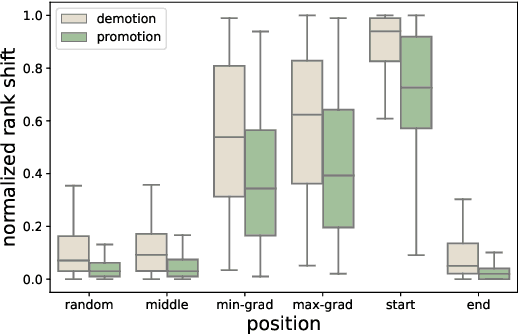
Contextual ranking models based on BERT are now well established for a wide range of passage and document ranking tasks. However, the robustness of BERT-based ranking models under adversarial inputs is under-explored. In this paper, we argue that BERT-rankers are not immune to adversarial attacks targeting retrieved documents given a query. Firstly, we propose algorithms for adversarial perturbation of both highly relevant and non-relevant documents using gradient-based optimization methods. The aim of our algorithms is to add/replace a small number of tokens to a highly relevant or non-relevant document to cause a large rank demotion or promotion. Our experiments show that a small number of tokens can already result in a large change in the rank of a document. Moreover, we find that BERT-rankers heavily rely on the document start/head for relevance prediction, making the initial part of the document more susceptible to adversarial attacks. More interestingly, we find a small set of recurring adversarial words that when added to documents result in successful rank demotion/promotion of any relevant/non-relevant document respectively. Finally, our adversarial tokens also show particular topic preferences within and across datasets, exposing potential biases from BERT pre-training or downstream datasets.
Towards Benchmarking the Utility of Explanations for Model Debugging
May 10, 2021
Post-hoc explanation methods are an important class of approaches that help understand the rationale underlying a trained model's decision. But how useful are they for an end-user towards accomplishing a given task? In this vision paper, we argue the need for a benchmark to facilitate evaluations of the utility of post-hoc explanation methods. As a first step to this end, we enumerate desirable properties that such a benchmark should possess for the task of debugging text classifiers. Additionally, we highlight that such a benchmark facilitates not only assessing the effectiveness of explanations but also their efficiency.
Neural OCR Post-Hoc Correction of Historical Corpora
Feb 01, 2021
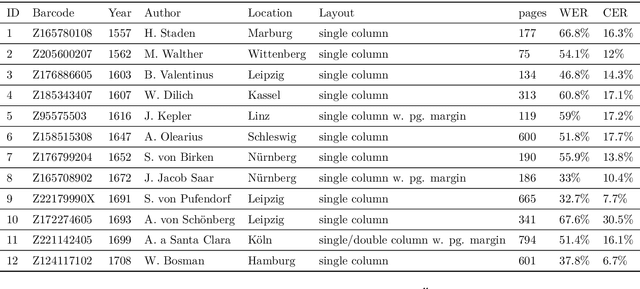
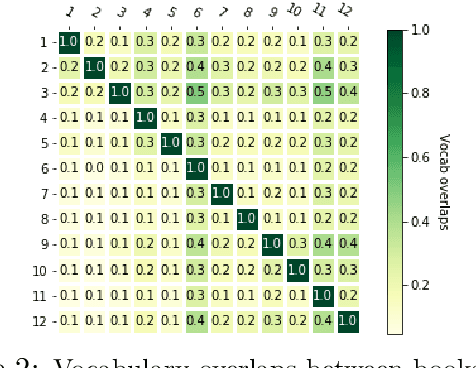
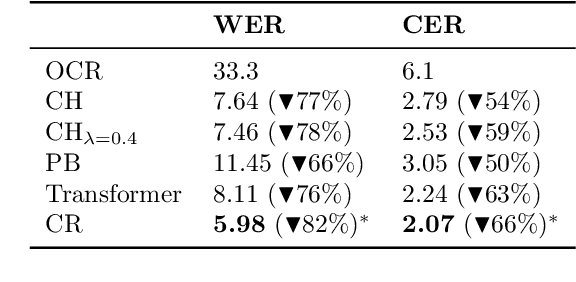
Optical character recognition (OCR) is crucial for a deeper access to historical collections. OCR needs to account for orthographic variations, typefaces, or language evolution (i.e., new letters, word spellings), as the main source of character, word, or word segmentation transcription errors. For digital corpora of historical prints, the errors are further exacerbated due to low scan quality and lack of language standardization. For the task of OCR post-hoc correction, we propose a neural approach based on a combination of recurrent (RNN) and deep convolutional network (ConvNet) to correct OCR transcription errors. At character level we flexibly capture errors, and decode the corrected output based on a novel attention mechanism. Accounting for the input and output similarity, we propose a new loss function that rewards the model's correcting behavior. Evaluation on a historical book corpus in German language shows that our models are robust in capturing diverse OCR transcription errors and reduce the word error rate of 32.3% by more than 89%.