 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural OCR Post-Hoc Correction of Historical Corpora
Feb 01, 2021
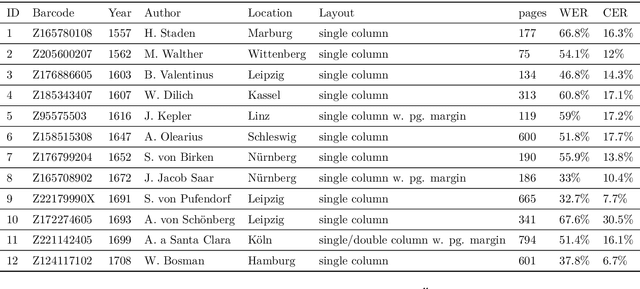
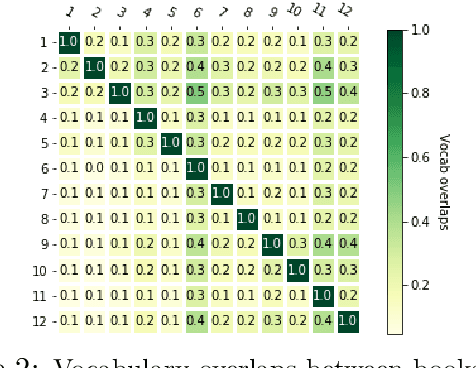
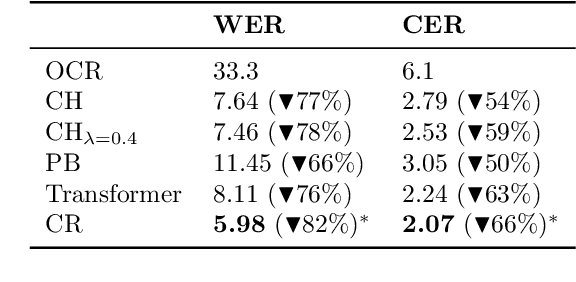
Optical character recognition (OCR) is crucial for a deeper access to historical collections. OCR needs to account for orthographic variations, typefaces, or language evolution (i.e., new letters, word spellings), as the main source of character, word, or word segmentation transcription errors. For digital corpora of historical prints, the errors are further exacerbated due to low scan quality and lack of language standardization. For the task of OCR post-hoc correction, we propose a neural approach based on a combination of recurrent (RNN) and deep convolutional network (ConvNet) to correct OCR transcription errors. At character level we flexibly capture errors, and decode the corrected output based on a novel attention mechanism. Accounting for the input and output similarity, we propose a new loss function that rewards the model's correcting behavior. Evaluation on a historical book corpus in German language shows that our models are robust in capturing diverse OCR transcription errors and reduce the word error rate of 32.3% by more than 89%.