 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Compound Retrieval Systems
Apr 16, 2025



Modern retrieval systems do not rely on a single ranking model to construct their rankings. Instead, they generally take a cascading approach where a sequence of ranking models are applied in multiple re-ranking stages. Thereby, they balance the quality of the top-K ranking with computational costs by limiting the number of documents each model re-ranks. However, the cascading approach is not the only way models can interact to form a retrieval system. We propose the concept of compound retrieval systems as a broader class of retrieval systems that apply multiple prediction models. This encapsulates cascading models but also allows other types of interactions than top-K re-ranking. In particular, we enable interactions with large language models (LLMs) which can provide relative relevance comparisons. We focus on the optimization of compound retrieval system design which uniquely involves learning where to apply the component models and how to aggregate their predictions into a final ranking. This work shows how our compound approach can combine the classic BM25 retrieval model with state-of-the-art (pairwise) LLM relevance predictions, while optimizing a given ranking metric and efficiency target. Our experimental results show optimized compound retrieval systems provide better trade-offs between effectiveness and efficiency than cascading approaches, even when applied in a self-supervised manner. With the introduction of compound retrieval systems, we hope to inspire the information retrieval field to more out-of-the-box thinking on how prediction models can interact to form rankings.
Inference Scaling for Long-Context Retrieval Augmented Generation
Oct 06, 2024



The scaling of inference computation has unlocked the potential of long-context large language models (LLMs) across diverse settings. For knowledge-intensive tasks, the increased compute is often allocated to incorporate more external knowledge. However, without effectively utilizing such knowledge, solely expanding context does not always enhance performance. In this work, we investigate inference scaling for retrieval augmented generation (RAG), exploring strategies beyond simply increasing the quantity of knowledge. We focus on two inference scaling strategies: in-context learning and iterative prompting. These strategies provide additional flexibility to scale test-time computation (e.g., by increasing retrieved documents or generation steps), thereby enhancing LLMs' ability to effectively acquire and utilize contextual information. We address two key questions: (1) How does RAG performance benefit from the scaling of inference computation when optimally configured? (2) Can we predict the optimal test-time compute allocation for a given budget by modeling the relationship between RAG performance and inference parameters? Our observations reveal that increasing inference computation leads to nearly linear gains in RAG performance when optimally allocated, a relationship we describe as the inference scaling laws for RAG. Building on this, we further develop the computation allocation model to estimate RAG performance across different inference configurations. The model predicts optimal inference parameters under various computation constraints, which align closely with the experimental results. By applying these optimal configurations, we demonstrate that scaling inference compute on long-context LLMs achieves up to 58.9% gains on benchmark datasets compared to standard RAG.
Reliable Confidence Intervals for Information Retrieval Evaluation Using Generative A.I
Jul 02, 2024



The traditional evaluation of information retrieval (IR) systems is generally very costly as it requires manual relevance annotation from human experts. Recent advancements in generative artificial intelligence -- specifically large language models (LLMs) -- can generate relevance annotations at an enormous scale with relatively small computational costs. Potentially, this could alleviate the costs traditionally associated with IR evaluation and make it applicable to numerous low-resource applications. However, generated relevance annotations are not immune to (systematic) errors, and as a result, directly using them for evaluation produces unreliable results. In this work, we propose two methods based on prediction-powered inference and conformal risk control that utilize computer-generated relevance annotations to place reliable confidence intervals (CIs) around IR evaluation metrics. Our proposed methods require a small number of reliable annotations from which the methods can statistically analyze the errors in the generated annotations. Using this information, we can place CIs around evaluation metrics with strong theoretical guarantees. Unlike existing approaches, our conformal risk control method is specifically designed for ranking metrics and can vary its CIs per query and document. Our experimental results show that our CIs accurately capture both the variance and bias in evaluation based on LLM annotations, better than the typical empirical bootstrapping estimates. We hope our contributions bring reliable evaluation to the many IR applications where this was traditionally infeasible.
Consolidating Ranking and Relevance Predictions of Large Language Models through Post-Processing
Apr 17, 2024



The powerful generative abilities of large language models (LLMs) show potential in generating relevance labels for search applications. Previous work has found that directly asking about relevancy, such as ``How relevant is document A to query Q?", results in sub-optimal ranking. Instead, the pairwise ranking prompting (PRP) approach produces promising ranking performance through asking about pairwise comparisons, e.g., ``Is document A more relevant than document B to query Q?". Thus, while LLMs are effective at their ranking ability, this is not reflected in their relevance label generation. In this work, we propose a post-processing method to consolidate the relevance labels generated by an LLM with its powerful ranking abilities. Our method takes both LLM generated relevance labels and pairwise preferences. The labels are then altered to satisfy the pairwise preferences of the LLM, while staying as close to the original values as possible. Our experimental results indicate that our approach effectively balances label accuracy and ranking performance. Thereby, our work shows it is possible to combine both the ranking and labeling abilities of LLMs through post-processing.
Generate, Filter, and Fuse: Query Expansion via Multi-Step Keyword Generation for Zero-Shot Neural Rankers
Nov 15, 2023



Query expansion has been proved to be effective in improving recall and precision of first-stage retrievers, and yet its influence on a complicated, state-of-the-art cross-encoder ranker remains under-explored. We first show that directly applying the expansion techniques in the current literature to state-of-the-art neural rankers can result in deteriorated zero-shot performance. To this end, we propose GFF, a pipeline that includes a large language model and a neural ranker, to Generate, Filter, and Fuse query expansions more effectively in order to improve the zero-shot ranking metrics such as nDCG@10. Specifically, GFF first calls an instruction-following language model to generate query-related keywords through a reasoning chain. Leveraging self-consistency and reciprocal rank weighting, GFF further filters and combines the ranking results of each expanded query dynamically. By utilizing this pipeline, we show that GFF can improve the zero-shot nDCG@10 on BEIR and TREC DL 2019/2020. We also analyze different modelling choices in the GFF pipeline and shed light on the future directions in query expansion for zero-shot neural rankers.
Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting
Jun 30, 2023



Ranking documents using Large Language Models (LLMs) by directly feeding the query and candidate documents into the prompt is an interesting and practical problem. However, there has been limited success so far, as researchers have found it difficult to outperform fine-tuned baseline rankers on benchmark datasets. We analyze pointwise and listwise ranking prompts used by existing methods and argue that off-the-shelf LLMs do not fully understand these ranking formulations, possibly due to the nature of how LLMs are trained. In this paper, we propose to significantly reduce the burden on LLMs by using a new technique called Pairwise Ranking Prompting (PRP). Our results are the first in the literature to achieve state-of-the-art ranking performance on standard benchmarks using moderate-sized open-sourced LLMs. On TREC-DL2020, PRP based on the Flan-UL2 model with 20B parameters outperforms the previous best approach in the literature, which is based on the blackbox commercial GPT-4 that has 50x (estimated) model size, by over 5% at NDCG@1. On TREC-DL2019, PRP is only inferior to the GPT-4 solution on the NDCG@5 and NDCG@10 metrics, while outperforming other existing solutions, such as InstructGPT which has 175B parameters, by over 10% for nearly all ranking metrics. Furthermore, we propose several variants of PRP to improve efficiency and show that it is possible to achieve competitive results even with linear complexity. We also discuss other benefits of PRP, such as supporting both generation and scoring LLM APIs, as well as being insensitive to input ordering.
RD-Suite: A Benchmark for Ranking Distillation
Jun 12, 2023



The distillation of ranking models has become an important topic in both academia and industry. In recent years, several advanced methods have been proposed to tackle this problem, often leveraging ranking information from teacher rankers that is absent in traditional classification settings. To date, there is no well-established consensus on how to evaluate this class of models. Moreover, inconsistent benchmarking on a wide range of tasks and datasets make it difficult to assess or invigorate advances in this field. This paper first examines representative prior arts on ranking distillation, and raises three questions to be answered around methodology and reproducibility. To that end, we propose a systematic and unified benchmark, Ranking Distillation Suite (RD-Suite), which is a suite of tasks with 4 large real-world datasets, encompassing two major modalities (textual and numeric) and two applications (standard distillation and distillation transfer). RD-Suite consists of benchmark results that challenge some of the common wisdom in the field, and the release of datasets with teacher scores and evaluation scripts for future research. RD-Suite paves the way towards better understanding of ranking distillation, facilities more research in this direction, and presents new challenges.
Query Expansion by Prompting Large Language Models
May 05, 2023



Query expansion is a widely used technique to improve the recall of search systems. In this paper, we propose an approach to query expansion that leverages the generative abilities of Large Language Models (LLMs). Unlike traditional query expansion approaches such as Pseudo-Relevance Feedback (PRF) that relies on retrieving a good set of pseudo-relevant documents to expand queries, we rely on the generative and creative abilities of an LLM and leverage the knowledge inherent in the model. We study a variety of different prompts, including zero-shot, few-shot and Chain-of-Thought (CoT). We find that CoT prompts are especially useful for query expansion as these prompts instruct the model to break queries down step-by-step and can provide a large number of terms related to the original query. Experimental results on MS-MARCO and BEIR demonstrate that query expansions generated by LLMs can be more powerful than traditional query expansion methods.
Regression Compatible Listwise Objectives for Calibrated Ranking
Nov 02, 2022


As Learning-to-Rank (LTR) approaches primarily seek to improve ranking quality, their output scores are not scale-calibrated by design -- for example, adding a constant to the score of each item on the list will not affect the list ordering. This fundamentally limits LTR usage in score-sensitive applications. Though a simple multi-objective approach that combines a regression and a ranking objective can effectively learn scale-calibrated scores, we argue that the two objectives can be inherently conflicting, which makes the trade-off far from ideal for both of them. In this paper, we propose a novel regression compatible ranking (RCR) approach to achieve a better trade-off. The advantage of the proposed approach is that the regression and ranking components are well aligned which brings new opportunities for harmonious regression and ranking. Theoretically, we show that the two components share the same minimizer at global minima while the regression component ensures scale calibration. Empirically, we show that the proposed approach performs well on both regression and ranking metrics on several public LTR datasets, and significantly improves the Pareto frontiers in the context of multi-objective optimization. Furthermore, we evaluated the proposed approach on YouTube Search and found that it not only improved the ranking quality of the production pCTR model, but also brought gains to the click prediction accuracy.
RankT5: Fine-Tuning T5 for Text Ranking with Ranking Losses
Oct 12, 2022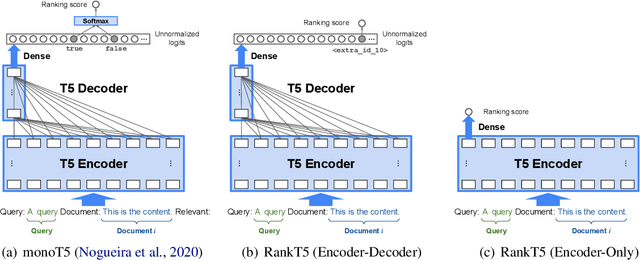
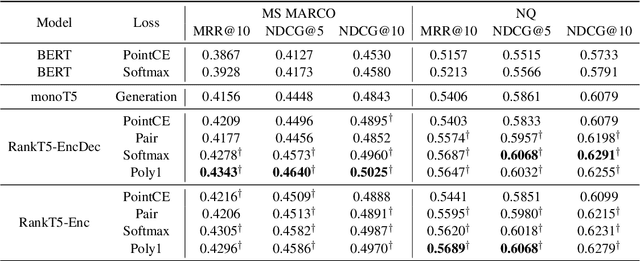
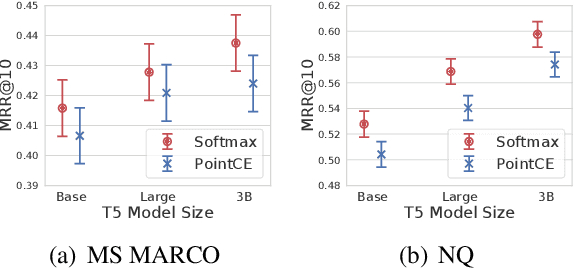
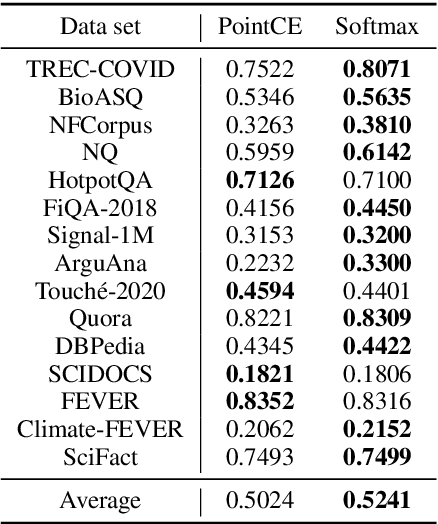
Recently, substantial progress has been made in text ranking based on pretrained language models such as BERT. However, there are limited studies on how to leverage more powerful sequence-to-sequence models such as T5. Existing attempts usually formulate text ranking as classification and rely on postprocessing to obtain a ranked list. In this paper, we propose RankT5 and study two T5-based ranking model structures, an encoder-decoder and an encoder-only one, so that they not only can directly output ranking scores for each query-document pair, but also can be fine-tuned with "pairwise" or "listwise" ranking losses to optimize ranking performances. Our experiments show that the proposed models with ranking losses can achieve substantial ranking performance gains on different public text ranking data sets. Moreover, when fine-tuned with listwise ranking losses, the ranking model appears to have better zero-shot ranking performance on out-of-domain data sets compared to the model fine-tuned with classification losses.