 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHear Me Out: A Study on the Use of the Voice Modality for Crowdsourced Relevance Assessments
Paper and Code
Apr 21, 2023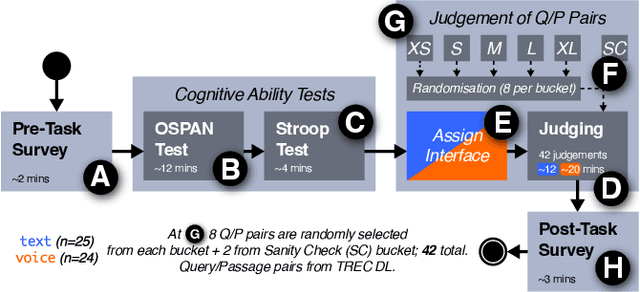
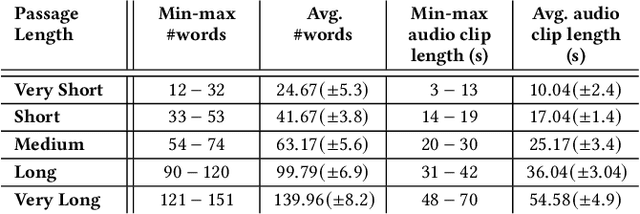


The creation of relevance assessments by human assessors (often nowadays crowdworkers) is a vital step when building IR test collections. Prior works have investigated assessor quality & behaviour, though into the impact of a document's presentation modality on assessor efficiency and effectiveness. Given the rise of voice-based interfaces, we investigate whether it is feasible for assessors to judge the relevance of text documents via a voice-based interface. We ran a user study (n = 49) on a crowdsourcing platform where participants judged the relevance of short and long documents sampled from the TREC Deep Learning corpus-presented to them either in the text or voice modality. We found that: (i) participants are equally accurate in their judgements across both the text and voice modality; (ii) with increased document length it takes participants significantly longer (for documents of length > 120 words it takes almost twice as much time) to make relevance judgements in the voice condition; and (iii) the ability of assessors to ignore stimuli that are not relevant (i.e., inhibition) impacts the assessment quality in the voice modality-assessors with higher inhibition are significantly more accurate than those with lower inhibition. Our results indicate that we can reliably leverage the voice modality as a means to effectively collect relevance labels from crowdworkers.