 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRigor in AI: Doing Rigorous AI Work Requires a Broader, Responsible AI-Informed Conception of Rigor
Jun 17, 2025In AI research and practice, rigor remains largely understood in terms of methodological rigor -- such as whether mathematical, statistical, or computational methods are correctly applied. We argue that this narrow conception of rigor has contributed to the concerns raised by the responsible AI community, including overblown claims about AI capabilities. Our position is that a broader conception of what rigorous AI research and practice should entail is needed. We believe such a conception -- in addition to a more expansive understanding of (1) methodological rigor -- should include aspects related to (2) what background knowledge informs what to work on (epistemic rigor); (3) how disciplinary, community, or personal norms, standards, or beliefs influence the work (normative rigor); (4) how clearly articulated the theoretical constructs under use are (conceptual rigor); (5) what is reported and how (reporting rigor); and (6) how well-supported the inferences from existing evidence are (interpretative rigor). In doing so, we also aim to provide useful language and a framework for much-needed dialogue about the AI community's work by researchers, policymakers, journalists, and other stakeholders.
From Stem to Stern: Contestability Along AI Value Chains
Aug 02, 2024
This workshop will grow and consolidate a community of interdisciplinary CSCW researchers focusing on the topic of contestable AI. As an outcome of the workshop, we will synthesize the most pressing opportunities and challenges for contestability along AI value chains in the form of a research roadmap. This roadmap will help shape and inspire imminent work in this field. Considering the length and depth of AI value chains, it will especially spur discussions around the contestability of AI systems along various sites of such chains. The workshop will serve as a platform for dialogue and demonstrations of concrete, successful, and unsuccessful examples of AI systems that (could or should) have been contested, to identify requirements, obstacles, and opportunities for designing and deploying contestable AI in various contexts. This will be held primarily as an in-person workshop, with some hybrid accommodation. The day will consist of individual presentations and group activities to stimulate ideation and inspire broad reflections on the field of contestable AI. Our aim is to facilitate interdisciplinary dialogue by bringing together researchers, practitioners, and stakeholders to foster the design and deployment of contestable AI.
An Empirical Exploration of Trust Dynamics in LLM Supply Chains
May 25, 2024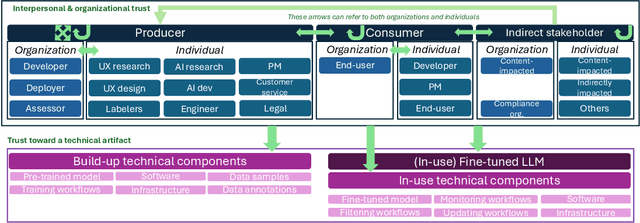
With the widespread proliferation of AI systems, trust in AI is an important and timely topic to navigate. Researchers so far have largely employed a myopic view of this relationship. In particular, a limited number of relevant trustors (e.g., end-users) and trustees (i.e., AI systems) have been considered, and empirical explorations have remained in laboratory settings, potentially overlooking factors that impact human-AI relationships in the real world. In this paper, we argue for broadening the scope of studies addressing `trust in AI' by accounting for the complex and dynamic supply chains that AI systems result from. AI supply chains entail various technical artifacts that diverse individuals, organizations, and stakeholders interact with, in a variety of ways. We present insights from an in-situ, empirical study of LLM supply chains. Our work reveals additional types of trustors and trustees and new factors impacting their trust relationships. These relationships were found to be central to the development and adoption of LLMs, but they can also be the terrain for uncalibrated trust and reliance on untrustworthy LLMs. Based on these findings, we discuss the implications for research on `trust in AI'. We highlight new research opportunities and challenges concerning the appropriate study of inter-actor relationships across the supply chain and the development of calibrated trust and meaningful reliance behaviors. We also question the meaning of building trust in the LLM supply chain.
Hear Me Out: A Study on the Use of the Voice Modality for Crowdsourced Relevance Assessments
Apr 21, 2023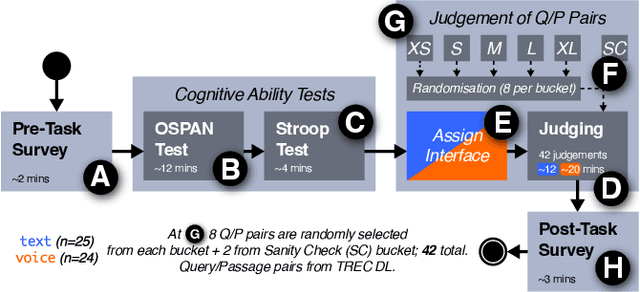
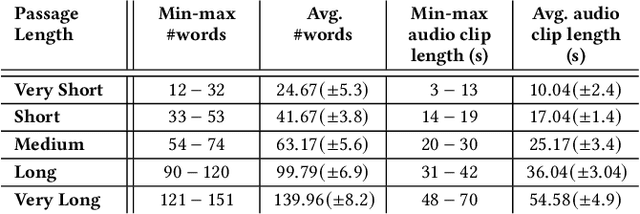


The creation of relevance assessments by human assessors (often nowadays crowdworkers) is a vital step when building IR test collections. Prior works have investigated assessor quality & behaviour, though into the impact of a document's presentation modality on assessor efficiency and effectiveness. Given the rise of voice-based interfaces, we investigate whether it is feasible for assessors to judge the relevance of text documents via a voice-based interface. We ran a user study (n = 49) on a crowdsourcing platform where participants judged the relevance of short and long documents sampled from the TREC Deep Learning corpus-presented to them either in the text or voice modality. We found that: (i) participants are equally accurate in their judgements across both the text and voice modality; (ii) with increased document length it takes participants significantly longer (for documents of length > 120 words it takes almost twice as much time) to make relevance judgements in the voice condition; and (iii) the ability of assessors to ignore stimuli that are not relevant (i.e., inhibition) impacts the assessment quality in the voice modality-assessors with higher inhibition are significantly more accurate than those with lower inhibition. Our results indicate that we can reliably leverage the voice modality as a means to effectively collect relevance labels from crowdworkers.
Explainability in AI Policies: A Critical Review of Communications, Reports, Regulations, and Standards in the EU, US, and UK
Apr 20, 2023

Public attention towards explainability of artificial intelligence (AI) systems has been rising in recent years to offer methodologies for human oversight. This has translated into the proliferation of research outputs, such as from Explainable AI, to enhance transparency and control for system debugging and monitoring, and intelligibility of system process and output for user services. Yet, such outputs are difficult to adopt on a practical level due to a lack of a common regulatory baseline, and the contextual nature of explanations. Governmental policies are now attempting to tackle such exigence, however it remains unclear to what extent published communications, regulations, and standards adopt an informed perspective to support research, industry, and civil interests. In this study, we perform the first thematic and gap analysis of this plethora of policies and standards on explainability in the EU, US, and UK. Through a rigorous survey of policy documents, we first contribute an overview of governmental regulatory trajectories within AI explainability and its sociotechnical impacts. We find that policies are often informed by coarse notions and requirements for explanations. This might be due to the willingness to conciliate explanations foremost as a risk management tool for AI oversight, but also due to the lack of a consensus on what constitutes a valid algorithmic explanation, and how feasible the implementation and deployment of such explanations are across stakeholders of an organization. Informed by AI explainability research, we conduct a gap analysis of existing policies, leading us to formulate a set of recommendations on how to address explainability in regulations for AI systems, especially discussing the definition, feasibility, and usability of explanations, as well as allocating accountability to explanation providers.
A.I. Robustness: a Human-Centered Perspective on Technological Challenges and Opportunities
Oct 19, 2022
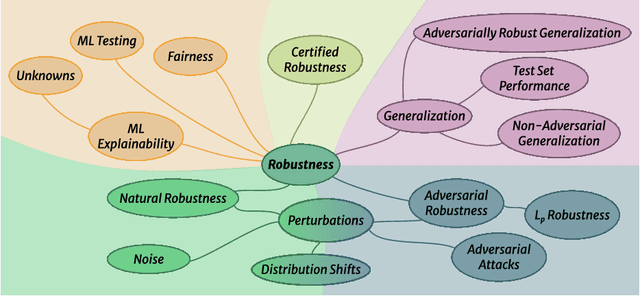
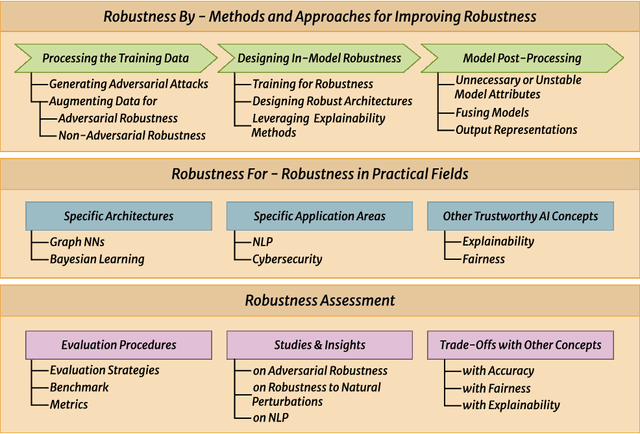
Despite the impressive performance of Artificial Intelligence (AI) systems, their robustness remains elusive and constitutes a key issue that impedes large-scale adoption. Robustness has been studied in many domains of AI, yet with different interpretations across domains and contexts. In this work, we systematically survey the recent progress to provide a reconciled terminology of concepts around AI robustness. We introduce three taxonomies to organize and describe the literature both from a fundamental and applied point of view: 1) robustness by methods and approaches in different phases of the machine learning pipeline; 2) robustness for specific model architectures, tasks, and systems; and in addition, 3) robustness assessment methodologies and insights, particularly the trade-offs with other trustworthiness properties. Finally, we identify and discuss research gaps and opportunities and give an outlook on the field. We highlight the central role of humans in evaluating and enhancing AI robustness, considering the necessary knowledge humans can provide, and discuss the need for better understanding practices and developing supportive tools in the future.
Towards a multi-stakeholder value-based assessment framework for algorithmic systems
May 09, 2022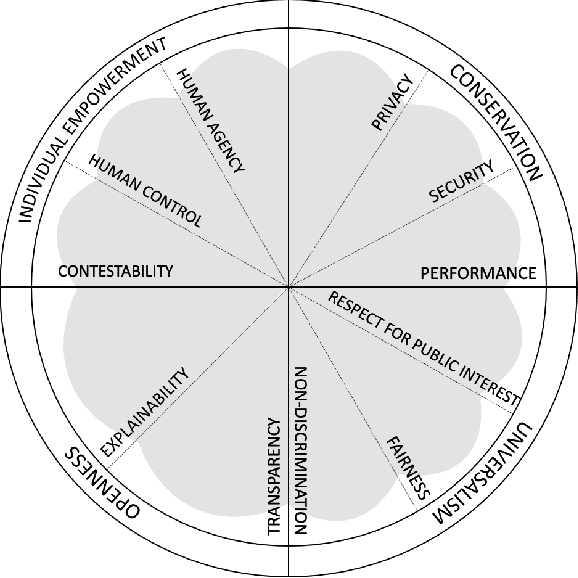

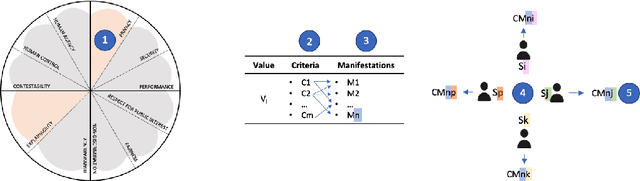
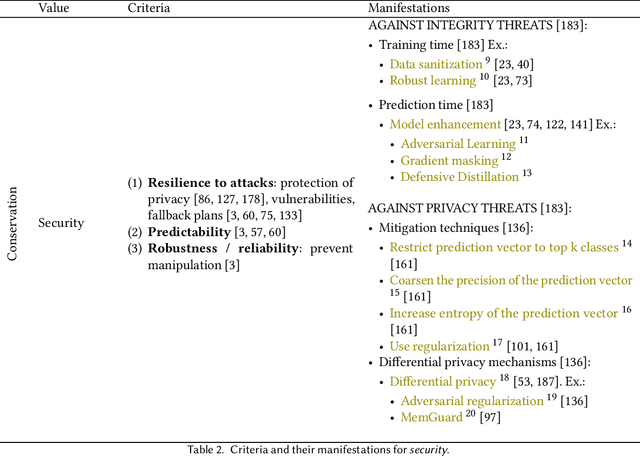
In an effort to regulate Machine Learning-driven (ML) systems, current auditing processes mostly focus on detecting harmful algorithmic biases. While these strategies have proven to be impactful, some values outlined in documents dealing with ethics in ML-driven systems are still underrepresented in auditing processes. Such unaddressed values mainly deal with contextual factors that cannot be easily quantified. In this paper, we develop a value-based assessment framework that is not limited to bias auditing and that covers prominent ethical principles for algorithmic systems. Our framework presents a circular arrangement of values with two bipolar dimensions that make common motivations and potential tensions explicit. In order to operationalize these high-level principles, values are then broken down into specific criteria and their manifestations. However, some of these value-specific criteria are mutually exclusive and require negotiation. As opposed to some other auditing frameworks that merely rely on ML researchers' and practitioners' input, we argue that it is necessary to include stakeholders that present diverse standpoints to systematically negotiate and consolidate value and criteria tensions. To that end, we map stakeholders with different insight needs, and assign tailored means for communicating value manifestations to them. We, therefore, contribute to current ML auditing practices with an assessment framework that visualizes closeness and tensions between values and we give guidelines on how to operationalize them, while opening up the evaluation and deliberation process to a wide range of stakeholders.
Exploring Data Pipelines through the Process Lens: a Reference Model forComputer Vision
Jul 05, 2021
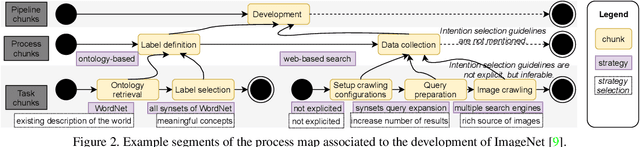
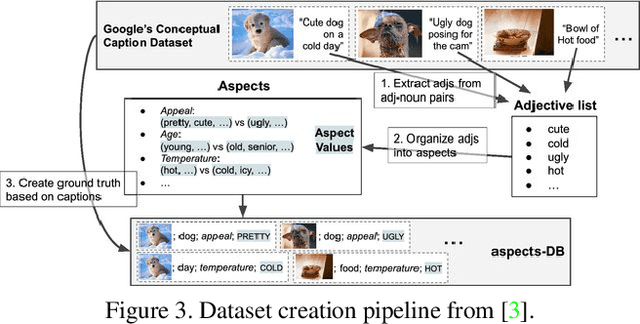
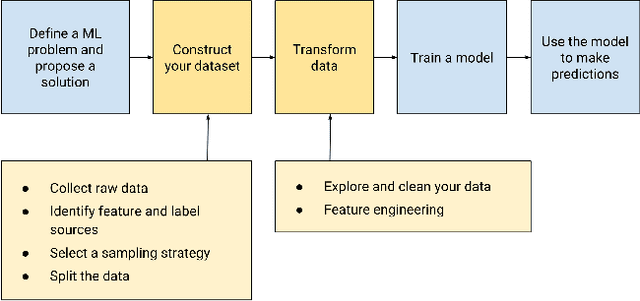
Researchers have identified datasets used for training computer vision (CV) models as an important source of hazardous outcomes, and continue to examine popular CV datasets to expose their harms. These works tend to treat datasets as objects, or focus on particular steps in data production pipelines. We argue here that we could further systematize our analysis of harms by examining CV data pipelines through a process-oriented lens that captures the creation, the evolution and use of these datasets. As a step towards cultivating a process-oriented lens, we embarked on an empirical study of CV data pipelines informed by the field of method engineering. We present here a preliminary result: a reference model of CV data pipelines. Besides exploring the questions that this endeavor raises, we discuss how the process lens could support researchers in discovering understudied issues, and could help practitioners in making their processes more transparent.
Designing Evaluations of Machine Learning Models for Subjective Inference: The Case of Sentence Toxicity
Nov 06, 2019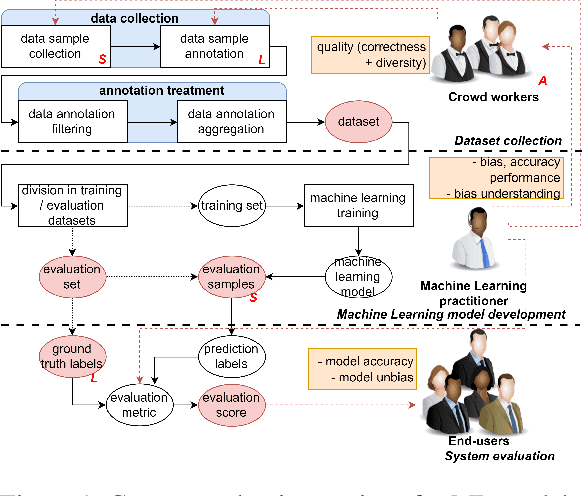

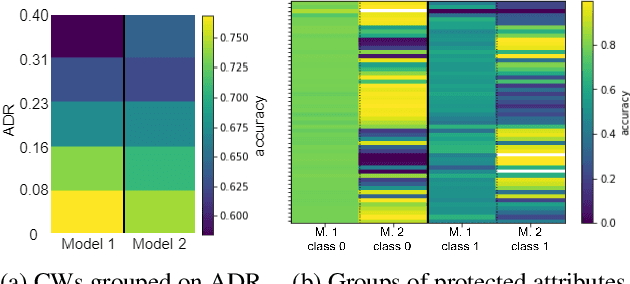
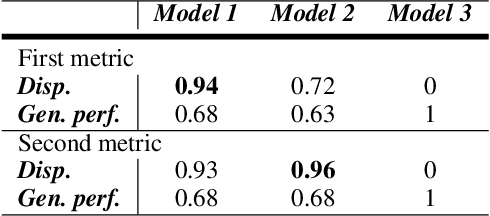
Machine Learning (ML) is increasingly applied in real-life scenarios, raising concerns about bias in automatic decision making. We focus on bias as a notion of opinion exclusion, that stems from the direct application of traditional ML pipelines to infer subjective properties. We argue that such ML systems should be evaluated with subjectivity and bias in mind. Considering the lack of evaluation standards yet to create evaluation benchmarks, we propose an initial list of specifications to define prior to creating evaluation datasets, in order to later accurately evaluate the biases. With the example of a sentence toxicity inference system, we illustrate how the specifications support the analysis of biases related to subjectivity. We highlight difficulties in instantiating these specifications and list future work for the crowdsourcing community to help the creation of appropriate evaluation datasets.
Unfairness towards subjective opinions in Machine Learning
Nov 06, 2019
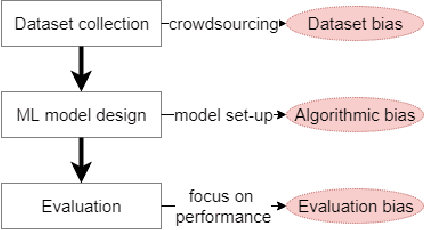
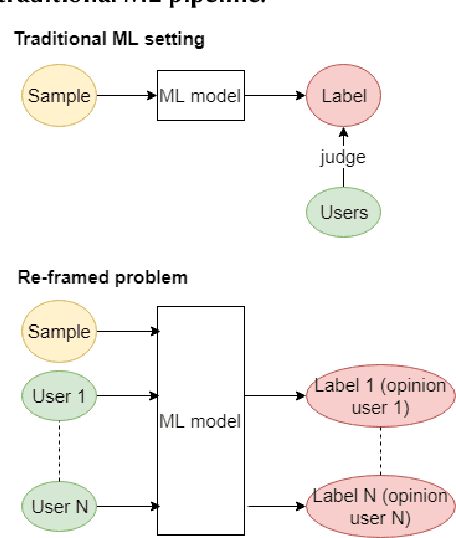
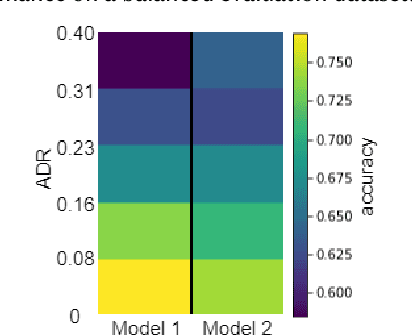
Despite the high interest for Machine Learning (ML) in academia and industry, many issues related to the application of ML to real-life problems are yet to be addressed. Here we put forward one limitation which arises from a lack of adaptation of ML models and datasets to specific applications. We formalise a new notion of unfairness as exclusion of opinions. We propose ways to quantify this unfairness, and aid understanding its causes through visualisation. These insights into the functioning of ML-based systems hint at methods to mitigate unfairness.