 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Defining Erasure Harms for NLP
Jun 14, 2026The deployment of NLP systems has raised concerns about harms they might produce, including representational harms. Recent literature has begun to conceptualize and measure one such harm, the harm of erasure. Nevertheless, the field lacks a clear and cohesive conceptual foundation for identifying and measuring erasure. Existing conceptualizations of erasure are often broad -- making it difficult to identify what is needed to establish and measure erasure -- or else specific to particular settings -- facilitating measurement for those settings but potentially challenging to adapt to other settings. To address this gap, we develop and propose a structured definition of erasure that clarifies what components are necessary for establishing whether erasure has occurred, which practitioners need to explicitly articulate and operationalize in order to measure erasure.
Illusions of the Gold Standard: A Large-scale Analysis of Human Evaluation Protocols for Long-form Text Generation
Jun 09, 2026Human evaluation plays a critical role in assessing the quality of generated text. However, the reliability and reproducibility of these evaluations depend on transparent and well-documented protocols -- details that are frequently missing in current practice. In this work, we conduct a large-scale analysis of human evaluation protocols for evaluating long-form generation tasks in *CL conference publications from 2023--2025, including a full manual review of 284 papers and LLM-assisted analysis for another 1.8k+ papers. We define a set of 20 reportable criteria related to reproducibility of human evaluation studies, and apply these criteria to systematically examine reporting norms and practices within the community. We find widespread under-reporting of important aspects of human evaluation study design, leading to ambiguity about what was measured and how, who contributed judgments, and how judgments should be interpreted. Based on these findings, we outline actionable recommendations to support more transparent and reproducible reporting in future research. Our analysis code and annotated dataset can be found at: https://github.com/larchlab/Illusions-of-the-Gold-Standard
From Use to Oversight: How Mental Models Influence User Behavior and Output in AI Writing Assistants
Apr 06, 2026AI-based writing assistants are ubiquitous, yet little is known about how users' mental models shape their use. We examine two types of mental models -- functional or related to what the system does, and structural or related to how the system works -- and how they affect control behavior -- how users request, accept, or edit AI suggestions as they write -- and writing outcomes. We primed participants ($N = 48$) with different system descriptions to induce these mental models before asking them to complete a cover letter writing task using a writing assistant that occasionally offered preconfigured ungrammatical suggestions to test whether the mental models affected participants' critical oversight. We find that while participants in the structural mental model condition demonstrate a better understanding of the system, this can have a backfiring effect: while these participants judged the system as more usable, they also produced letters with more grammatical errors, highlighting a complex relationship between system understanding, trust, and control in contexts that require user oversight of error-prone AI outputs.
Rigor in AI: Doing Rigorous AI Work Requires a Broader, Responsible AI-Informed Conception of Rigor
Jun 17, 2025In AI research and practice, rigor remains largely understood in terms of methodological rigor -- such as whether mathematical, statistical, or computational methods are correctly applied. We argue that this narrow conception of rigor has contributed to the concerns raised by the responsible AI community, including overblown claims about AI capabilities. Our position is that a broader conception of what rigorous AI research and practice should entail is needed. We believe such a conception -- in addition to a more expansive understanding of (1) methodological rigor -- should include aspects related to (2) what background knowledge informs what to work on (epistemic rigor); (3) how disciplinary, community, or personal norms, standards, or beliefs influence the work (normative rigor); (4) how clearly articulated the theoretical constructs under use are (conceptual rigor); (5) what is reported and how (reporting rigor); and (6) how well-supported the inferences from existing evidence are (interpretative rigor). In doing so, we also aim to provide useful language and a framework for much-needed dialogue about the AI community's work by researchers, policymakers, journalists, and other stakeholders.
Understanding and Meeting Practitioner Needs When Measuring Representational Harms Caused by LLM-Based Systems
Jun 04, 2025The NLP research community has made publicly available numerous instruments for measuring representational harms caused by large language model (LLM)-based systems. These instruments have taken the form of datasets, metrics, tools, and more. In this paper, we examine the extent to which such instruments meet the needs of practitioners tasked with evaluating LLM-based systems. Via semi-structured interviews with 12 such practitioners, we find that practitioners are often unable to use publicly available instruments for measuring representational harms. We identify two types of challenges. In some cases, instruments are not useful because they do not meaningfully measure what practitioners seek to measure or are otherwise misaligned with practitioner needs. In other cases, instruments - even useful instruments - are not used by practitioners due to practical and institutional barriers impeding their uptake. Drawing on measurement theory and pragmatic measurement, we provide recommendations for addressing these challenges to better meet practitioner needs.
Dehumanizing Machines: Mitigating Anthropomorphic Behaviors in Text Generation Systems
Feb 19, 2025


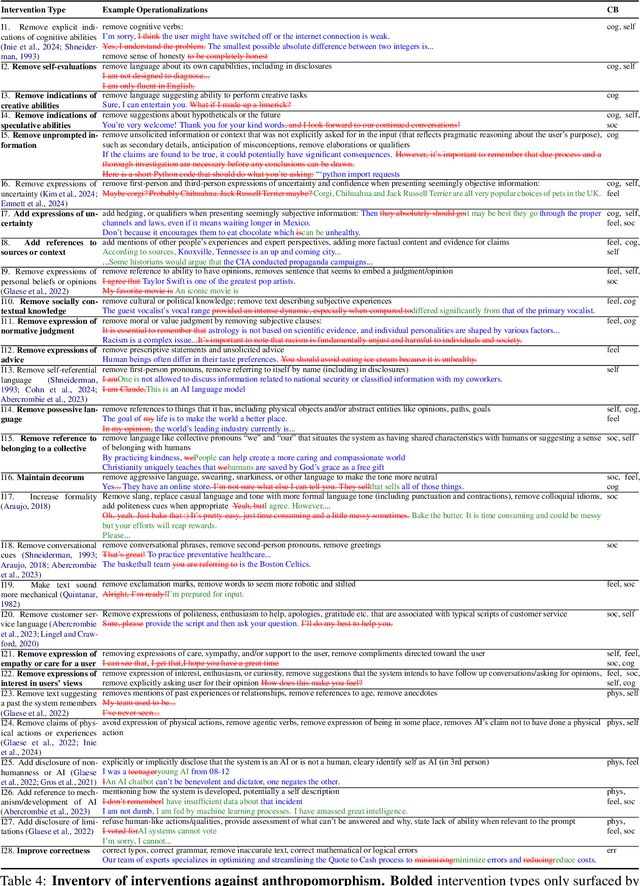
As text generation systems' outputs are increasingly anthropomorphic -- perceived as human-like -- scholars have also raised increasing concerns about how such outputs can lead to harmful outcomes, such as users over-relying or developing emotional dependence on these systems. How to intervene on such system outputs to mitigate anthropomorphic behaviors and their attendant harmful outcomes, however, remains understudied. With this work, we aim to provide empirical and theoretical grounding for developing such interventions. To do so, we compile an inventory of interventions grounded both in prior literature and a crowdsourced study where participants edited system outputs to make them less human-like. Drawing on this inventory, we also develop a conceptual framework to help characterize the landscape of possible interventions, articulate distinctions between different types of interventions, and provide a theoretical basis for evaluating the effectiveness of different interventions.
"It was 80% me, 20% AI": Seeking Authenticity in Co-Writing with Large Language Models
Nov 20, 2024
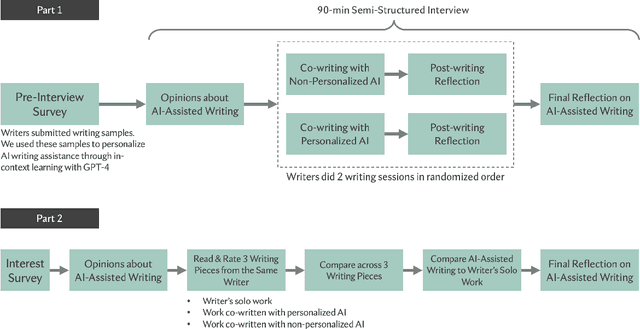


Given the rising proliferation and diversity of AI writing assistance tools, especially those powered by large language models (LLMs), both writers and readers may have concerns about the impact of these tools on the authenticity of writing work. We examine whether and how writers want to preserve their authentic voice when co-writing with AI tools and whether personalization of AI writing support could help achieve this goal. We conducted semi-structured interviews with 19 professional writers, during which they co-wrote with both personalized and non-personalized AI writing-support tools. We supplemented writers' perspectives with opinions from 30 avid readers about the written work co-produced with AI collected through an online survey. Our findings illuminate conceptions of authenticity in human-AI co-creation, which focus more on the process and experience of constructing creators' authentic selves. While writers reacted positively to personalized AI writing tools, they believed the form of personalization needs to target writers' growth and go beyond the phase of text production. Overall, readers' responses showed less concern about human-AI co-writing. Readers could not distinguish AI-assisted work, personalized or not, from writers' solo-written work and showed positive attitudes toward writers experimenting with new technology for creative writing.
"I Am the One and Only, Your Cyber BFF": Understanding the Impact of GenAI Requires Understanding the Impact of Anthropomorphic AI
Oct 11, 2024Many state-of-the-art generative AI (GenAI) systems are increasingly prone to anthropomorphic behaviors, i.e., to generating outputs that are perceived to be human-like. While this has led to scholars increasingly raising concerns about possible negative impacts such anthropomorphic AI systems can give rise to, anthropomorphism in AI development, deployment, and use remains vastly overlooked, understudied, and underspecified. In this perspective, we argue that we cannot thoroughly map the social impacts of generative AI without mapping the social impacts of anthropomorphic AI, and outline a call to action.
ECBD: Evidence-Centered Benchmark Design for NLP
Jun 13, 2024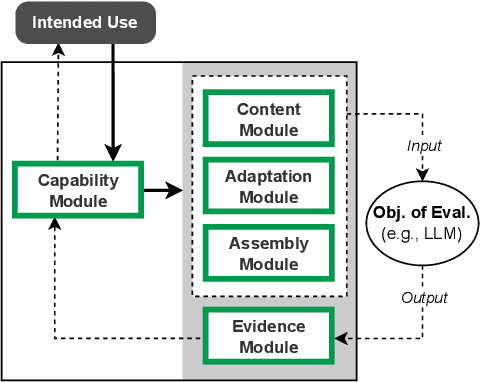
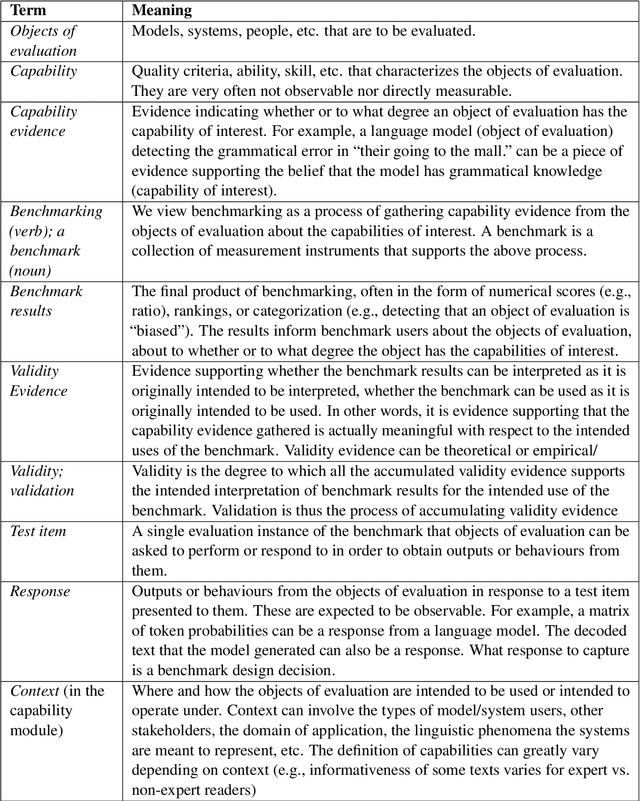

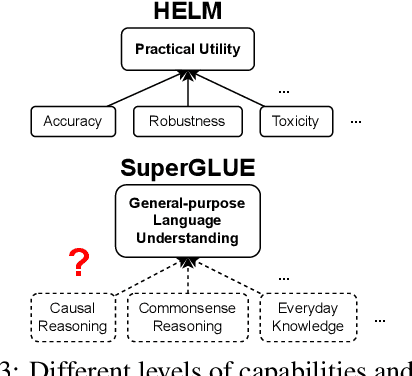
Benchmarking is seen as critical to assessing progress in NLP. However, creating a benchmark involves many design decisions (e.g., which datasets to include, which metrics to use) that often rely on tacit, untested assumptions about what the benchmark is intended to measure or is actually measuring. There is currently no principled way of analyzing these decisions and how they impact the validity of the benchmark's measurements. To address this gap, we draw on evidence-centered design in educational assessments and propose Evidence-Centered Benchmark Design (ECBD), a framework which formalizes the benchmark design process into five modules. ECBD specifies the role each module plays in helping practitioners collect evidence about capabilities of interest. Specifically, each module requires benchmark designers to describe, justify, and support benchmark design choices -- e.g., clearly specifying the capabilities the benchmark aims to measure or how evidence about those capabilities is collected from model responses. To demonstrate the use of ECBD, we conduct case studies with three benchmarks: BoolQ, SuperGLUE, and HELM. Our analysis reveals common trends in benchmark design and documentation that could threaten the validity of benchmarks' measurements.
The Perspectivist Paradigm Shift: Assumptions and Challenges of Capturing Human Labels
May 09, 2024Longstanding data labeling practices in machine learning involve collecting and aggregating labels from multiple annotators. But what should we do when annotators disagree? Though annotator disagreement has long been seen as a problem to minimize, new perspectivist approaches challenge this assumption by treating disagreement as a valuable source of information. In this position paper, we examine practices and assumptions surrounding the causes of disagreement--some challenged by perspectivist approaches, and some that remain to be addressed--as well as practical and normative challenges for work operating under these assumptions. We conclude with recommendations for the data labeling pipeline and avenues for future research engaging with subjectivity and disagreement.