 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECBD: Evidence-Centered Benchmark Design for NLP
Paper and Code
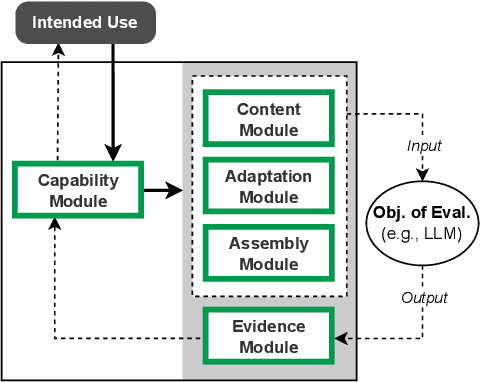
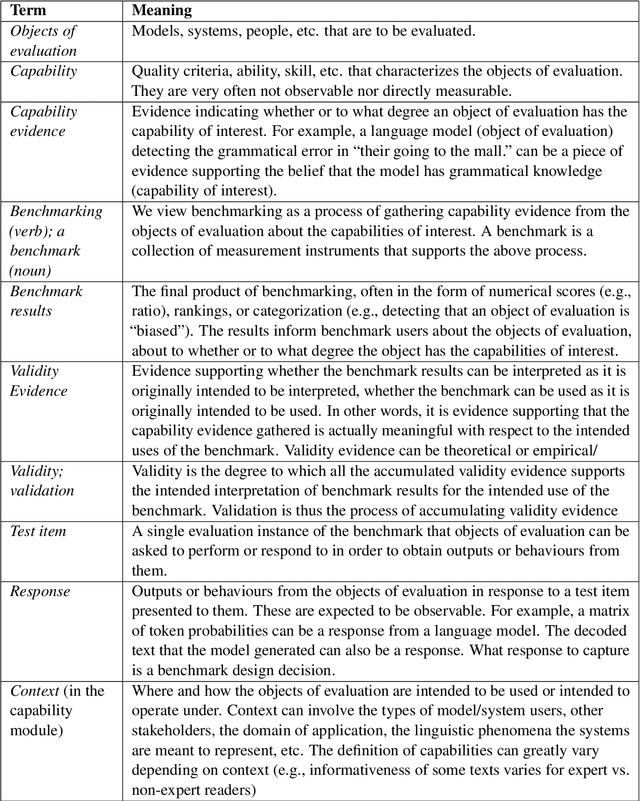

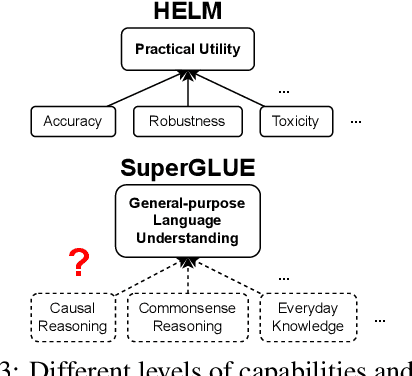
Benchmarking is seen as critical to assessing progress in NLP. However, creating a benchmark involves many design decisions (e.g., which datasets to include, which metrics to use) that often rely on tacit, untested assumptions about what the benchmark is intended to measure or is actually measuring. There is currently no principled way of analyzing these decisions and how they impact the validity of the benchmark's measurements. To address this gap, we draw on evidence-centered design in educational assessments and propose Evidence-Centered Benchmark Design (ECBD), a framework which formalizes the benchmark design process into five modules. ECBD specifies the role each module plays in helping practitioners collect evidence about capabilities of interest. Specifically, each module requires benchmark designers to describe, justify, and support benchmark design choices -- e.g., clearly specifying the capabilities the benchmark aims to measure or how evidence about those capabilities is collected from model responses. To demonstrate the use of ECBD, we conduct case studies with three benchmarks: BoolQ, SuperGLUE, and HELM. Our analysis reveals common trends in benchmark design and documentation that could threaten the validity of benchmarks' measurements.