 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Relevance: On the Relationship Between Retrieval and RAG Information Coverage
Mar 11, 2026Retrieval-augmented generation (RAG) systems combine document retrieval with a generative model to address complex information seeking tasks like report generation. While the relationship between retrieval quality and generation effectiveness seems intuitive, it has not been systematically studied. We investigate whether upstream retrieval metrics can serve as reliable early indicators of the final generated response's information coverage. Through experiments across two text RAG benchmarks (TREC NeuCLIR 2024 and TREC RAG 2024) and one multimodal benchmark (WikiVideo), we analyze 15 text retrieval stacks and 10 multimodal retrieval stacks across four RAG pipelines and multiple evaluation frameworks (Auto-ARGUE and MiRAGE). Our findings demonstrate strong correlations between coverage-based retrieval metrics and nugget coverage in generated responses at both topic and system levels. This relationship holds most strongly when retrieval objectives align with generation goals, though more complex iterative RAG pipelines can partially decouple generation quality from retrieval effectiveness. These findings provide empirical support for using retrieval metrics as proxies for RAG performance.
Supporting Humans in Evaluating AI Summaries of Legal Depositions
Jan 21, 2026While large language models (LLMs) are increasingly used to summarize long documents, this trend poses significant challenges in the legal domain, where the factual accuracy of deposition summaries is crucial. Nugget-based methods have been shown to be extremely helpful for the automated evaluation of summarization approaches. In this work, we translate these methods to the user side and explore how nuggets could directly assist end users. Although prior systems have demonstrated the promise of nugget-based evaluation, its potential to support end users remains underexplored. Focusing on the legal domain, we present a prototype that leverages a factual nugget-based approach to support legal professionals in two concrete scenarios: (1) determining which of two summaries is better, and (2) manually improving an automatically generated summary.
Insider Knowledge: How Much Can RAG Systems Gain from Evaluation Secrets?
Jan 19, 2026RAG systems are increasingly evaluated and optimized using LLM judges, an approach that is rapidly becoming the dominant paradigm for system assessment. Nugget-based approaches in particular are now embedded not only in evaluation frameworks but also in the architectures of RAG systems themselves. While this integration can lead to genuine improvements, it also creates a risk of faulty measurements due to circularity. In this paper, we investigate this risk through comparative experiments with nugget-based RAG systems, including Ginger and Crucible, against strong baselines such as GPT-Researcher. By deliberately modifying Crucible to generate outputs optimized for an LLM judge, we show that near-perfect evaluation scores can be achieved when elements of the evaluation - such as prompt templates or gold nuggets - are leaked or can be predicted. Our results highlight the importance of blind evaluation settings and methodological diversity to guard against mistaking metric overfitting for genuine system progress.
Incorporating Q&A Nuggets into Retrieval-Augmented Generation
Jan 19, 2026RAGE systems integrate ideas from automatic evaluation (E) into Retrieval-augmented Generation (RAG). As one such example, we present Crucible, a Nugget-Augmented Generation System that preserves explicit citation provenance by constructing a bank of Q&A nuggets from retrieved documents and uses them to guide extraction, selection, and report generation. Reasoning on nuggets avoids repeated information through clear and interpretable Q&A semantics - instead of opaque cluster abstractions - while maintaining citation provenance throughout the entire generation process. Evaluated on the TREC NeuCLIR 2024 collection, our Crucible system substantially outperforms Ginger, a recent nugget-based RAG system, in nugget recall, density, and citation grounding.
UNH at CheckThat! 2025: Fine-tuning Vs Prompting in Claim Extraction
Sep 08, 2025We participate in CheckThat! Task 2 English and explore various methods of prompting and in-context learning, including few-shot prompting and fine-tuning with different LLM families, with the goal of extracting check-worthy claims from social media passages. Our best METEOR score is achieved by fine-tuning a FLAN-T5 model. However, we observe that higher-quality claims can sometimes be extracted using other methods, even when their METEOR scores are lower.
LLM-Evaluation Tropes: Perspectives on the Validity of LLM-Evaluations
Apr 27, 2025Large Language Models (LLMs) are increasingly used to evaluate information retrieval (IR) systems, generating relevance judgments traditionally made by human assessors. Recent empirical studies suggest that LLM-based evaluations often align with human judgments, leading some to suggest that human judges may no longer be necessary, while others highlight concerns about judgment reliability, validity, and long-term impact. As IR systems begin incorporating LLM-generated signals, evaluation outcomes risk becoming self-reinforcing, potentially leading to misleading conclusions. This paper examines scenarios where LLM-evaluators may falsely indicate success, particularly when LLM-based judgments influence both system development and evaluation. We highlight key risks, including bias reinforcement, reproducibility challenges, and inconsistencies in assessment methodologies. To address these concerns, we propose tests to quantify adverse effects, guardrails, and a collaborative framework for constructing reusable test collections that integrate LLM judgments responsibly. By providing perspectives from academia and industry, this work aims to establish best practices for the principled use of LLMs in IR evaluation.
LLM-based relevance assessment still can't replace human relevance assessment
Dec 22, 2024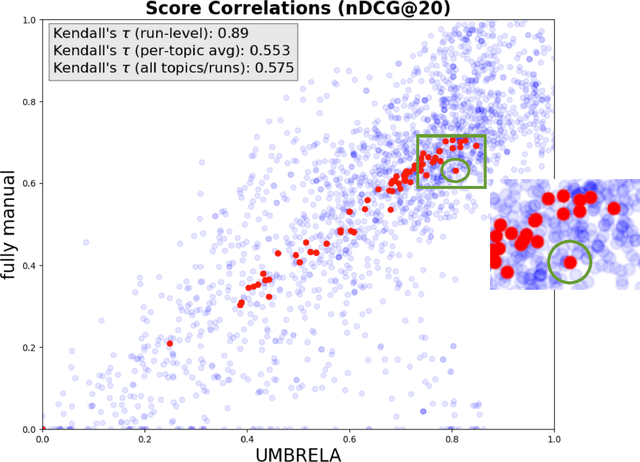
The use of large language models (LLMs) for relevance assessment in information retrieval has gained significant attention, with recent studies suggesting that LLM-based judgments provide comparable evaluations to human judgments. Notably, based on TREC 2024 data, Upadhyay et al. make a bold claim that LLM-based relevance assessments, such as those generated by the UMBRELA system, can fully replace traditional human relevance assessments in TREC-style evaluations. This paper critically examines this claim, highlighting practical and theoretical limitations that undermine the validity of this conclusion. First, we question whether the evidence provided by Upadhyay et al. really supports their claim, particularly if a test collection is used asa benchmark for future improvements. Second, through a submission deliberately intended to do so, we demonstrate the ease with which automatic evaluation metrics can be subverted, showing that systems designed to exploit these evaluations can achieve artificially high scores. Theoretical challenges -- such as the inherent narcissism of LLMs, the risk of overfitting to LLM-based metrics, and the potential degradation of future LLM performance -- must be addressed before LLM-based relevance assessments can be considered a viable replacement for human judgments.
Best in Tau@LLMJudge: Criteria-Based Relevance Evaluation with Llama3
Oct 17, 2024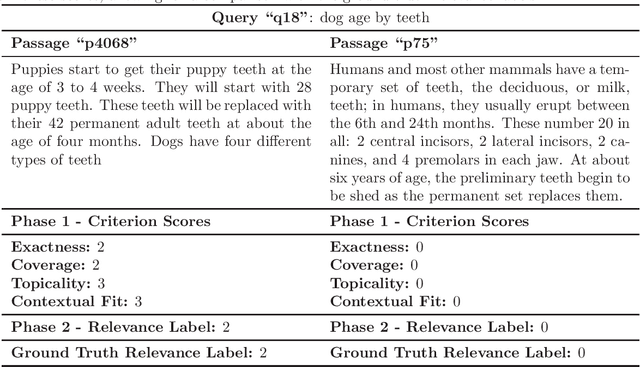



Traditional evaluation of information retrieval (IR) systems relies on human-annotated relevance labels, which can be both biased and costly at scale. In this context, large language models (LLMs) offer an alternative by allowing us to directly prompt them to assign relevance labels for passages associated with each query. In this study, we explore alternative methods to directly prompt LLMs for assigned relevance labels, by exploring two hypotheses: Hypothesis 1 assumes that it is helpful to break down "relevance" into specific criteria - exactness, coverage, topicality, and contextual fit. We explore different approaches that prompt large language models (LLMs) to obtain criteria-level grades for all passages, and we consider various ways to aggregate criteria-level grades into a relevance label. Hypothesis 2 assumes that differences in linguistic style between queries and passages may negatively impact the automatic relevance label prediction. We explore whether improvements can be achieved by first synthesizing a summary of the passage in the linguistic style of a query, and then using this summary in place of the passage to assess its relevance. We include an empirical evaluation of our approaches based on data from the LLMJudge challenge run in Summer 2024, where our "Four Prompts" approach obtained the highest scores in Kendall's tau.
A Workbench for Autograding Retrieve/Generate Systems
May 21, 2024



This resource paper addresses the challenge of evaluating Information Retrieval (IR) systems in the era of autoregressive Large Language Models (LLMs). Traditional methods relying on passage-level judgments are no longer effective due to the diversity of responses generated by LLM-based systems. We provide a workbench to explore several alternative evaluation approaches to judge the relevance of a system's response that incorporate LLMs: 1. Asking an LLM whether the response is relevant; 2. Asking the LLM which set of nuggets (i.e., relevant key facts) is covered in the response; 3. Asking the LLM to answer a set of exam questions with the response. This workbench aims to facilitate the development of new, reusable test collections. Researchers can manually refine sets of nuggets and exam questions, observing their impact on system evaluation and leaderboard rankings. Resource available at https://github.com/TREMA-UNH/autograding-workbench
An Exam-based Evaluation Approach Beyond Traditional Relevance Judgments
Feb 01, 2024Current IR evaluation is based on relevance judgments, created either manually or automatically, with decisions outsourced to Large Language Models (LLMs). We offer an alternative paradigm, that never relies on relevance judgments in any form. Instead, a text is defined as relevant if it contains information that enables the answering of key questions. We use this idea to design the EXAM Answerability Metric to evaluate information retrieval/generation systems for their ability to provide topically relevant information. We envision the role of a human judge to edit and define an exam question bank that will test for the presence of relevant information in text. We support this step by generating an initial set of exam questions. In the next phase, an LLM-based question answering system will automatically grade system responses by tracking which exam questions are answerable with which system responses. We propose two evaluation measures, the recall-oriented EXAM Cover metric, and the precision-oriented EXAM Qrels metric, the latter which can be implemented with trec_eval. This paradigm not only allows for the expansion of the exam question set post-hoc but also facilitates the ongoing evaluation of future information systems, whether they focus on retrieval, generation, or both.