 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest in Tau@LLMJudge: Criteria-Based Relevance Evaluation with Llama3
Paper and Code
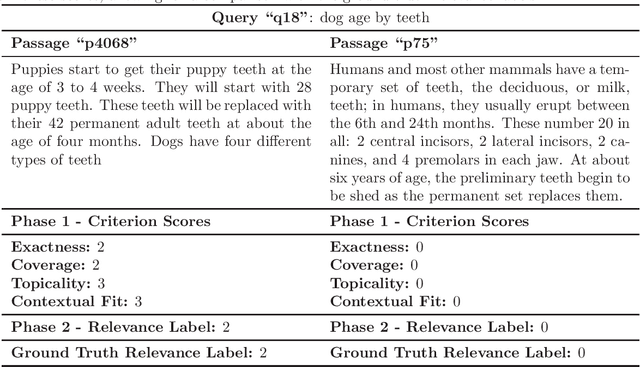



Traditional evaluation of information retrieval (IR) systems relies on human-annotated relevance labels, which can be both biased and costly at scale. In this context, large language models (LLMs) offer an alternative by allowing us to directly prompt them to assign relevance labels for passages associated with each query. In this study, we explore alternative methods to directly prompt LLMs for assigned relevance labels, by exploring two hypotheses: Hypothesis 1 assumes that it is helpful to break down "relevance" into specific criteria - exactness, coverage, topicality, and contextual fit. We explore different approaches that prompt large language models (LLMs) to obtain criteria-level grades for all passages, and we consider various ways to aggregate criteria-level grades into a relevance label. Hypothesis 2 assumes that differences in linguistic style between queries and passages may negatively impact the automatic relevance label prediction. We explore whether improvements can be achieved by first synthesizing a summary of the passage in the linguistic style of a query, and then using this summary in place of the passage to assess its relevance. We include an empirical evaluation of our approaches based on data from the LLMJudge challenge run in Summer 2024, where our "Four Prompts" approach obtained the highest scores in Kendall's tau.