 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-Rankers as Relevance Judges
Jan 08, 2026Using large language models (LLMs) to predict relevance judgments has shown promising results. Most studies treat this task as a distinct research line, e.g., focusing on prompt design for predicting relevance labels given a query and passage. However, predicting relevance judgments is essentially a form of relevance prediction, a problem extensively studied in tasks such as re-ranking. Despite this potential overlap, little research has explored reusing or adapting established re-ranking methods to predict relevance judgments, leading to potential resource waste and redundant development. To bridge this gap, we reproduce re-rankers in a re-ranker-as-relevance-judge setup. We design two adaptation strategies: (i) using binary tokens (e.g., "true" and "false") generated by a re-ranker as direct judgments, and (ii) converting continuous re-ranking scores into binary labels via thresholding. We perform extensive experiments on TREC-DL 2019 to 2023 with 8 re-rankers from 3 families, ranging from 220M to 32B, and analyse the evaluation bias exhibited by re-ranker-based judges. Results show that re-ranker-based relevance judges, under both strategies, can outperform UMBRELA, a state-of-the-art LLM-based relevance judge, in around 40% to 50% of the cases; they also exhibit strong self-preference towards their own and same-family re-rankers, as well as cross-family bias.
LLM-Evaluation Tropes: Perspectives on the Validity of LLM-Evaluations
Apr 27, 2025Large Language Models (LLMs) are increasingly used to evaluate information retrieval (IR) systems, generating relevance judgments traditionally made by human assessors. Recent empirical studies suggest that LLM-based evaluations often align with human judgments, leading some to suggest that human judges may no longer be necessary, while others highlight concerns about judgment reliability, validity, and long-term impact. As IR systems begin incorporating LLM-generated signals, evaluation outcomes risk becoming self-reinforcing, potentially leading to misleading conclusions. This paper examines scenarios where LLM-evaluators may falsely indicate success, particularly when LLM-based judgments influence both system development and evaluation. We highlight key risks, including bias reinforcement, reproducibility challenges, and inconsistencies in assessment methodologies. To address these concerns, we propose tests to quantify adverse effects, guardrails, and a collaborative framework for constructing reusable test collections that integrate LLM judgments responsibly. By providing perspectives from academia and industry, this work aims to establish best practices for the principled use of LLMs in IR evaluation.
DyVo: Dynamic Vocabularies for Learned Sparse Retrieval with Entities
Oct 10, 2024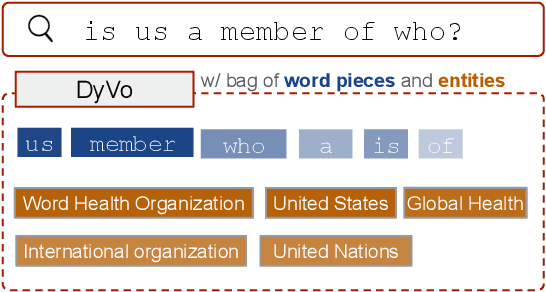
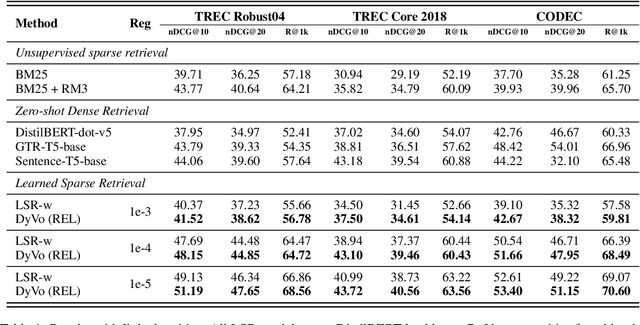
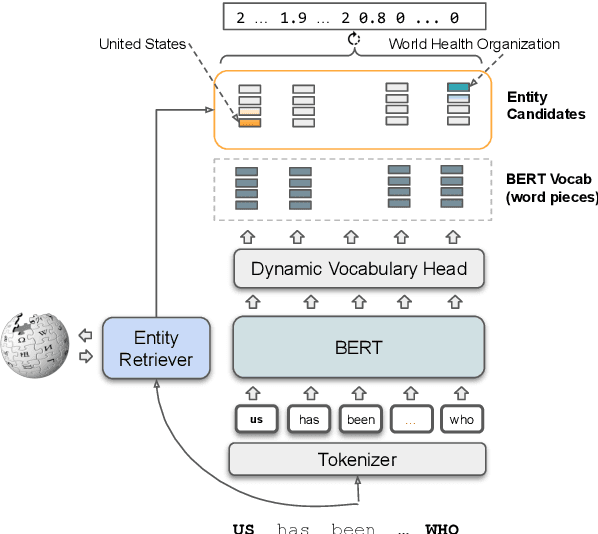

Learned Sparse Retrieval (LSR) models use vocabularies from pre-trained transformers, which often split entities into nonsensical fragments. Splitting entities can reduce retrieval accuracy and limits the model's ability to incorporate up-to-date world knowledge not included in the training data. In this work, we enhance the LSR vocabulary with Wikipedia concepts and entities, enabling the model to resolve ambiguities more effectively and stay current with evolving knowledge. Central to our approach is a Dynamic Vocabulary (DyVo) head, which leverages existing entity embeddings and an entity retrieval component that identifies entities relevant to a query or document. We use the DyVo head to generate entity weights, which are then merged with word piece weights to create joint representations for efficient indexing and retrieval using an inverted index. In experiments across three entity-rich document ranking datasets, the resulting DyVo model substantially outperforms state-of-the-art baselines.
* https://github.com/thongnt99/DyVo
Doing Personal LAPS: LLM-Augmented Dialogue Construction for Personalized Multi-Session Conversational Search
May 06, 2024The future of conversational agents will provide users with personalized information responses. However, a significant challenge in developing models is the lack of large-scale dialogue datasets that span multiple sessions and reflect real-world user preferences. Previous approaches rely on experts in a wizard-of-oz setup that is difficult to scale, particularly for personalized tasks. Our method, LAPS, addresses this by using large language models (LLMs) to guide a single human worker in generating personalized dialogues. This method has proven to speed up the creation process and improve quality. LAPS can collect large-scale, human-written, multi-session, and multi-domain conversations, including extracting user preferences. When compared to existing datasets, LAPS-produced conversations are as natural and diverse as expert-created ones, which stays in contrast with fully synthetic methods. The collected dataset is suited to train preference extraction and personalized response generation. Our results show that responses generated explicitly using extracted preferences better match user's actual preferences, highlighting the value of using extracted preferences over simple dialogue history. Overall, LAPS introduces a new method to leverage LLMs to create realistic personalized conversational data more efficiently and effectively than previous methods.
DREQ: Document Re-Ranking Using Entity-based Query Understanding
Jan 11, 2024While entity-oriented neural IR models have advanced significantly, they often overlook a key nuance: the varying degrees of influence individual entities within a document have on its overall relevance. Addressing this gap, we present DREQ, an entity-oriented dense document re-ranking model. Uniquely, we emphasize the query-relevant entities within a document's representation while simultaneously attenuating the less relevant ones, thus obtaining a query-specific entity-centric document representation. We then combine this entity-centric document representation with the text-centric representation of the document to obtain a "hybrid" representation of the document. We learn a relevance score for the document using this hybrid representation. Using four large-scale benchmarks, we show that DREQ outperforms state-of-the-art neural and non-neural re-ranking methods, highlighting the effectiveness of our entity-oriented representation approach.
Conversational Information Seeking
Jan 21, 2022Conversational information seeking (CIS) is concerned with a sequence of interactions between one or more users and an information system. Interactions in CIS are primarily based on natural language dialogue, while they may include other types of interactions, such as click, touch, and body gestures. This monograph provides a thorough overview of CIS definitions, applications, interactions, interfaces, design, implementation, and evaluation. This monograph views CIS applications as including conversational search, conversational question answering, and conversational recommendation. Our aim is to provide an overview of past research related to CIS, introduce the current state-of-the-art in CIS, highlight the challenges still being faced in the community. and suggest future directions.
ConvAI3: Generating Clarifying Questions for Open-Domain Dialogue Systems (ClariQ)
Sep 23, 2020
This document presents a detailed description of the challenge on clarifying questions for dialogue systems (ClariQ). The challenge is organized as part of the Conversational AI challenge series (ConvAI3) at Search Oriented Conversational AI (SCAI) EMNLP workshop in 2020. The main aim of the conversational systems is to return an appropriate answer in response to the user requests. However, some user requests might be ambiguous. In IR settings such a situation is handled mainly thought the diversification of the search result page. It is however much more challenging in dialogue settings with limited bandwidth. Therefore, in this challenge, we provide a common evaluation framework to evaluate mixed-initiative conversations. Participants are asked to rank clarifying questions in an information-seeking conversations. The challenge is organized in two stages where in Stage 1 we evaluate the submissions in an offline setting and single-turn conversations. Top participants of Stage 1 get the chance to have their model tested by human annotators.