 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyVo: Dynamic Vocabularies for Learned Sparse Retrieval with Entities
Paper and Code
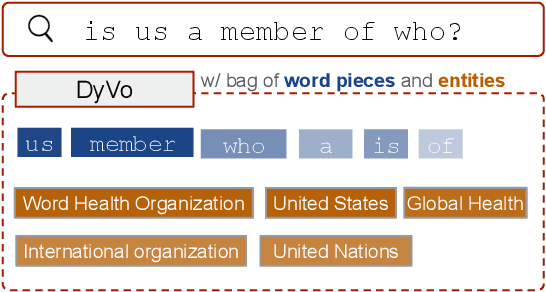
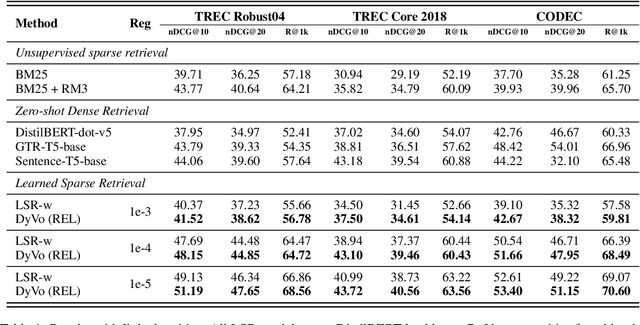
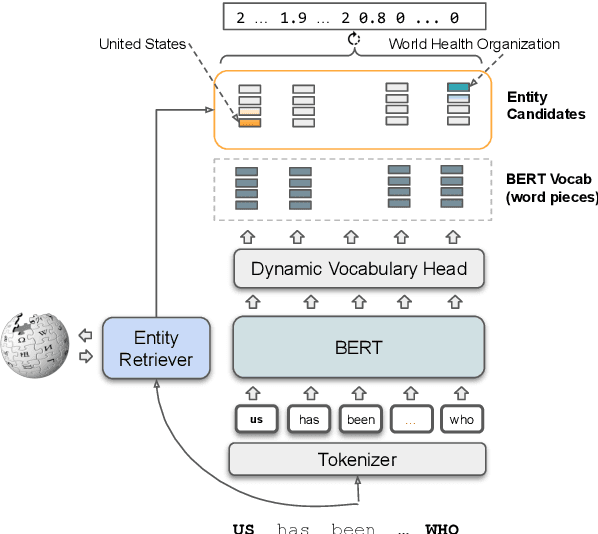

Learned Sparse Retrieval (LSR) models use vocabularies from pre-trained transformers, which often split entities into nonsensical fragments. Splitting entities can reduce retrieval accuracy and limits the model's ability to incorporate up-to-date world knowledge not included in the training data. In this work, we enhance the LSR vocabulary with Wikipedia concepts and entities, enabling the model to resolve ambiguities more effectively and stay current with evolving knowledge. Central to our approach is a Dynamic Vocabulary (DyVo) head, which leverages existing entity embeddings and an entity retrieval component that identifies entities relevant to a query or document. We use the DyVo head to generate entity weights, which are then merged with word piece weights to create joint representations for efficient indexing and retrieval using an inverted index. In experiments across three entity-rich document ranking datasets, the resulting DyVo model substantially outperforms state-of-the-art baselines.