 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoing Personal LAPS: LLM-Augmented Dialogue Construction for Personalized Multi-Session Conversational Search
May 06, 2024The future of conversational agents will provide users with personalized information responses. However, a significant challenge in developing models is the lack of large-scale dialogue datasets that span multiple sessions and reflect real-world user preferences. Previous approaches rely on experts in a wizard-of-oz setup that is difficult to scale, particularly for personalized tasks. Our method, LAPS, addresses this by using large language models (LLMs) to guide a single human worker in generating personalized dialogues. This method has proven to speed up the creation process and improve quality. LAPS can collect large-scale, human-written, multi-session, and multi-domain conversations, including extracting user preferences. When compared to existing datasets, LAPS-produced conversations are as natural and diverse as expert-created ones, which stays in contrast with fully synthetic methods. The collected dataset is suited to train preference extraction and personalized response generation. Our results show that responses generated explicitly using extracted preferences better match user's actual preferences, highlighting the value of using extracted preferences over simple dialogue history. Overall, LAPS introduces a new method to leverage LLMs to create realistic personalized conversational data more efficiently and effectively than previous methods.
Open Assistant Toolkit -- version 2
Mar 01, 2024



We present the second version of the Open Assistant Toolkit (OAT-v2), an open-source task-oriented conversational system for composing generative neural models. OAT-v2 is a scalable and flexible assistant platform supporting multiple domains and modalities of user interaction. It splits processing a user utterance into modular system components, including submodules such as action code generation, multimodal content retrieval, and knowledge-augmented response generation. Developed over multiple years of the Alexa TaskBot challenge, OAT-v2 is a proven system that enables scalable and robust experimentation in experimental and real-world deployment. OAT-v2 provides open models and software for research and commercial applications to enable the future of multimodal virtual assistants across diverse applications and types of rich interaction.
mmSense: Detecting Concealed Weapons with a Miniature Radar Sensor
Feb 28, 2023



For widespread adoption, public security and surveillance systems must be accurate, portable, compact, and real-time, without impeding the privacy of the individuals being observed. Current systems broadly fall into two categories -- image-based which are accurate, but lack privacy, and RF signal-based, which preserve privacy but lack portability, compactness and accuracy. Our paper proposes mmSense, an end-to-end portable miniaturised real-time system that can accurately detect the presence of concealed metallic objects on persons in a discrete, privacy-preserving modality. mmSense features millimeter wave radar technology, provided by Google's Soli sensor for its data acquisition, and TransDope, our real-time neural network, capable of processing a single radar data frame in 19 ms. mmSense achieves high recognition rates on a diverse set of challenging scenes while running on standard laptop hardware, demonstrating a significant advancement towards creating portable, cost-effective real-time radar based surveillance systems.
Forward and Inverse models in HCI:Physical simulation and deep learning for inferring 3D finger pose
Sep 07, 2021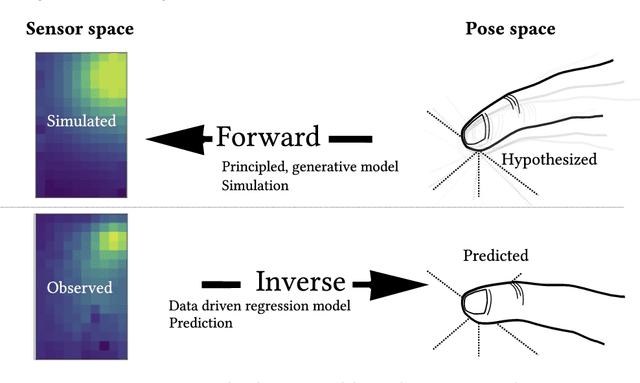


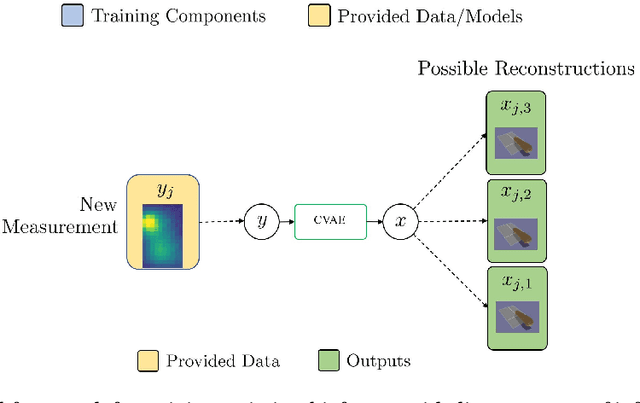
We outline the role of forward and inverse modelling approaches in the design of human--computer interaction systems. Causal, forward models tend to be easier to specify and simulate, but HCI requires solutions of the inverse problem. We infer finger 3D position $(x,y,z)$ and pose (pitch and yaw) on a mobile device using capacitive sensors which can sense the finger up to 5cm above the screen. We use machine learning to develop data-driven models to infer position, pose and sensor readings, based on training data from: 1. data generated by robots, 2. data from electrostatic simulators 3. human-generated data. Machine learned emulation is used to accelerate the electrostatic simulation performance by a factor of millions. We combine a Conditional Variational Autoencoder with domain expertise/models experimentally collected data. We compare forward and inverse model approaches to direct inference of finger pose. The combination gives the most accurate reported results on inferring 3D position and pose with a capacitive sensor on a mobile device.