 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe machine learning model release from Trusted Research Environments: The AI-SDC package
Dec 06, 2022We present AI-SDC, an integrated suite of open source Python tools to facilitate Statistical Disclosure Control (SDC) of Machine Learning (ML) models trained on confidential data prior to public release. AI-SDC combines (i) a SafeModel package that extends commonly used ML models to provide ante-hoc SDC by assessing the vulnerability of disclosure posed by the training regime; and (ii) an Attacks package that provides post-hoc SDC by rigorously assessing the empirical disclosure risk of a model through a variety of simulated attacks after training. The AI-SDC code and documentation are available under an MIT license at https://github.com/AI-SDC/AI-SDC.
GRAIMATTER Green Paper: Recommendations for disclosure control of trained Machine Learning (ML) models from Trusted Research Environments (TREs)
Nov 03, 2022



TREs are widely, and increasingly used to support statistical analysis of sensitive data across a range of sectors (e.g., health, police, tax and education) as they enable secure and transparent research whilst protecting data confidentiality. There is an increasing desire from academia and industry to train AI models in TREs. The field of AI is developing quickly with applications including spotting human errors, streamlining processes, task automation and decision support. These complex AI models require more information to describe and reproduce, increasing the possibility that sensitive personal data can be inferred from such descriptions. TREs do not have mature processes and controls against these risks. This is a complex topic, and it is unreasonable to expect all TREs to be aware of all risks or that TRE researchers have addressed these risks in AI-specific training. GRAIMATTER has developed a draft set of usable recommendations for TREs to guard against the additional risks when disclosing trained AI models from TREs. The development of these recommendations has been funded by the GRAIMATTER UKRI DARE UK sprint research project. This version of our recommendations was published at the end of the project in September 2022. During the course of the project, we have identified many areas for future investigations to expand and test these recommendations in practice. Therefore, we expect that this document will evolve over time.
Machine Learning Models Disclosure from Trusted Research Environments (TRE), Challenges and Opportunities
Nov 10, 2021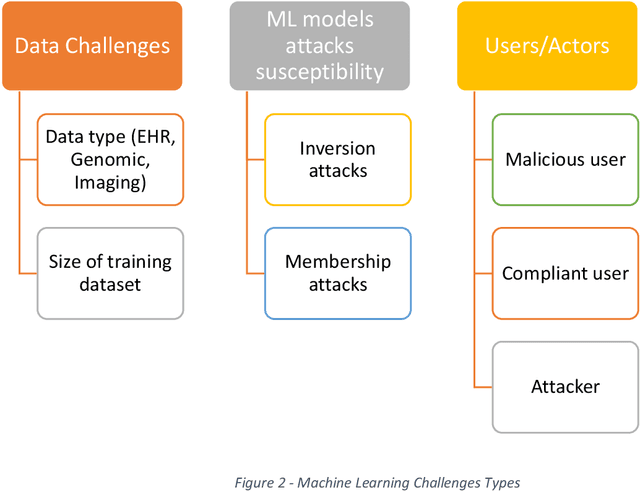
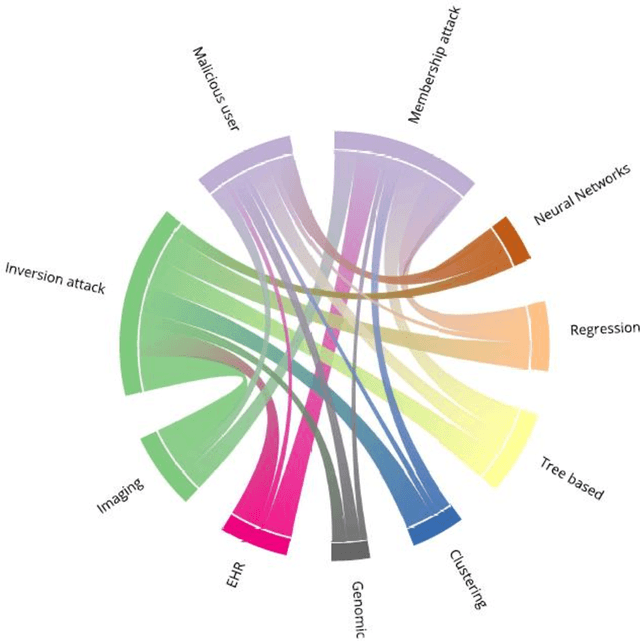
Trusted Research environments (TRE)s are safe and secure environments in which researchers can access sensitive data. With the growth and diversity of medical data such as Electronic Health Records (EHR), Medical Imaging and Genomic data, there is an increase in the use of Artificial Intelligence (AI) in general and the subfield of Machine Learning (ML) in particular in the healthcare domain. This generates the desire to disclose new types of outputs from TREs, such as trained machine learning models. Although specific guidelines and policies exists for statistical disclosure controls in TREs, they do not satisfactorily cover these new types of output request. In this paper, we define some of the challenges around the application and disclosure of machine learning for healthcare within TREs. We describe various vulnerabilities the introduction of AI brings to TREs. We also provide an introduction to the different types and levels of risks associated with the disclosure of trained ML models. We finally describe the new research opportunities in developing and adapting policies and tools for safely disclosing machine learning outputs from TREs.
Forward and Inverse models in HCI:Physical simulation and deep learning for inferring 3D finger pose
Sep 07, 2021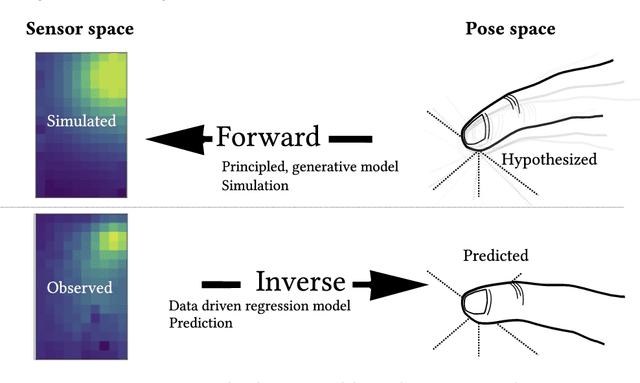


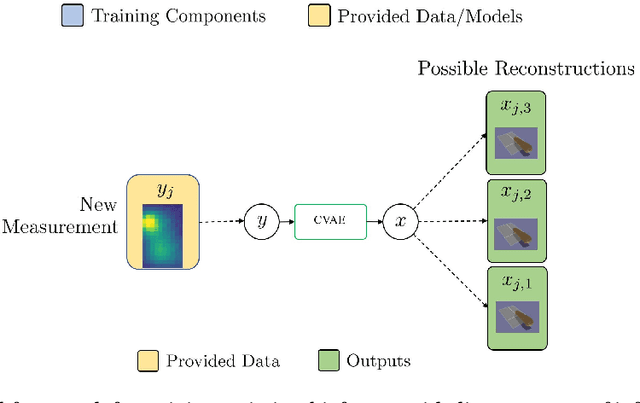
We outline the role of forward and inverse modelling approaches in the design of human--computer interaction systems. Causal, forward models tend to be easier to specify and simulate, but HCI requires solutions of the inverse problem. We infer finger 3D position $(x,y,z)$ and pose (pitch and yaw) on a mobile device using capacitive sensors which can sense the finger up to 5cm above the screen. We use machine learning to develop data-driven models to infer position, pose and sensor readings, based on training data from: 1. data generated by robots, 2. data from electrostatic simulators 3. human-generated data. Machine learned emulation is used to accelerate the electrostatic simulation performance by a factor of millions. We combine a Conditional Variational Autoencoder with domain expertise/models experimentally collected data. We compare forward and inverse model approaches to direct inference of finger pose. The combination gives the most accurate reported results on inferring 3D position and pose with a capacitive sensor on a mobile device.
Single-Shot Clothing Category Recognition in Free-Configurations with Application to Autonomous Clothes Sorting
Jul 22, 2017
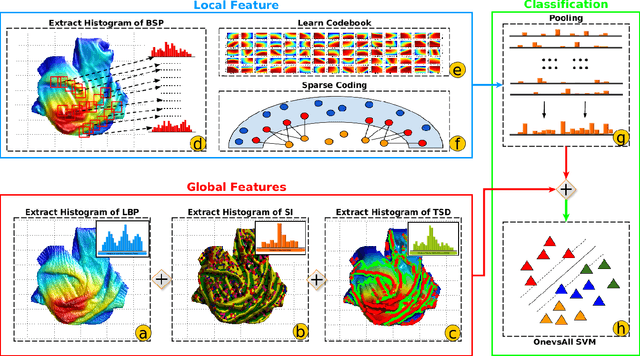


This paper proposes a single-shot approach for recognising clothing categories from 2.5D features. We propose two visual features, BSP (B-Spline Patch) and TSD (Topology Spatial Distances) for this task. The local BSP features are encoded by LLC (Locality-constrained Linear Coding) and fused with three different global features. Our visual feature is robust to deformable shapes and our approach is able to recognise the category of unknown clothing in unconstrained and random configurations. We integrated the category recognition pipeline with a stereo vision system, clothing instance detection, and dual-arm manipulators to achieve an autonomous sorting system. To verify the performance of our proposed method, we build a high-resolution RGBD clothing dataset of 50 clothing items of 5 categories sampled in random configurations (a total of 2,100 clothing samples). Experimental results show that our approach is able to reach 83.2\% accuracy while classifying clothing items which were previously unseen during training. This advances beyond the previous state-of-the-art by 36.2\%. Finally, we evaluate the proposed approach in an autonomous robot sorting system, in which the robot recognises a clothing item from an unconstrained pile, grasps it, and sorts it into a box according to its category. Our proposed sorting system achieves reasonable sorting success rates with single-shot perception.
Robot Vision Architecture for Autonomous Clothes Manipulation
Oct 18, 2016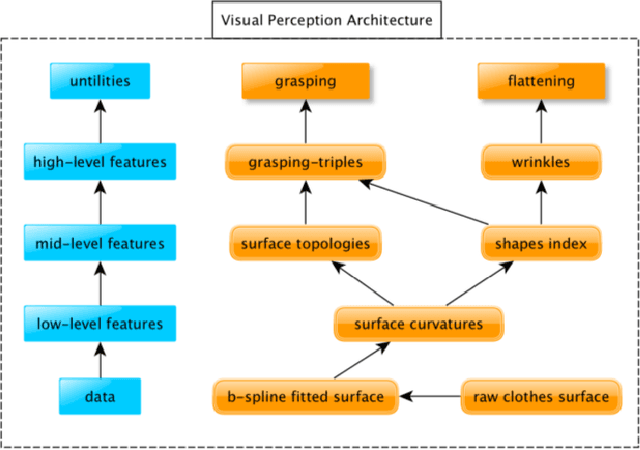



This paper presents a novel robot vision architecture for perceiving generic 3D clothes configurations. Our architecture is hierarchically structured, starting from low-level curvatures, across mid-level geometric shapes \& topology descriptions; and finally approaching high-level semantic surface structure descriptions. We demonstrate our robot vision architecture in a customised dual-arm industrial robot with our self-designed, off-the-self stereo vision system, carrying out autonomous grasping and dual-arm flattening. It is worth noting that the proposed dual-arm flattening approach is unique among the state-of-the-art robot autonomous system, which is the major contribution of this paper. The experimental results show that the proposed dual-arm flattening using stereo vision system remarkably outperforms the single-arm flattening and widely-cited Kinect-based sensing system for dexterous manipulation tasks. In addition, the proposed grasping approach achieves satisfactory performance on grasping various kind of garments, verifying the capability of proposed visual perception architecture to be adapted to more than one clothing manipulation tasks.