 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMUSE: Adaptive Model Updating using a Simulated Environment
Dec 13, 2024

Prediction models frequently face the challenge of concept drift, in which the underlying data distribution changes over time, weakening performance. Examples can include models which predict loan default, or those used in healthcare contexts. Typical management strategies involve regular model updates or updates triggered by concept drift detection. However, these simple policies do not necessarily balance the cost of model updating with improved classifier performance. We present AMUSE (Adaptive Model Updating using a Simulated Environment), a novel method leveraging reinforcement learning trained within a simulated data generating environment, to determine update timings for classifiers. The optimal updating policy depends on the current data generating process and ongoing drift process. Our key idea is that we can train an arbitrarily complex model updating policy by creating a training environment in which possible episodes of drift are simulated by a parametric model, which represents expectations of possible drift patterns. As a result, AMUSE proactively recommends updates based on estimated performance improvements, learning a policy that balances maintaining model performance with minimizing update costs. Empirical results confirm the effectiveness of AMUSE in simulated data.
Ethical considerations of use of hold-out sets in clinical prediction model management
Jun 05, 2024Clinical prediction models are statistical or machine learning models used to quantify the risk of a certain health outcome using patient data. These can then inform potential interventions on patients, causing an effect called performative prediction: predictions inform interventions which influence the outcome they were trying to predict, leading to a potential underestimation of risk in some patients if a model is updated on this data. One suggested resolution to this is the use of hold-out sets, in which a set of patients do not receive model derived risk scores, such that a model can be safely retrained. We present an overview of clinical and research ethics regarding potential implementation of hold-out sets for clinical prediction models in health settings. We focus on the ethical principles of beneficence, non-maleficence, autonomy and justice. We also discuss informed consent, clinical equipoise, and truth-telling. We present illustrative cases of potential hold-out set implementations and discuss statistical issues arising from different hold-out set sampling methods. We also discuss differences between hold-out sets and randomised control trials, in terms of ethics and statistical issues. Finally, we give practical recommendations for researchers interested in the use hold-out sets for clinical prediction models.
Safe machine learning model release from Trusted Research Environments: The AI-SDC package
Dec 06, 2022We present AI-SDC, an integrated suite of open source Python tools to facilitate Statistical Disclosure Control (SDC) of Machine Learning (ML) models trained on confidential data prior to public release. AI-SDC combines (i) a SafeModel package that extends commonly used ML models to provide ante-hoc SDC by assessing the vulnerability of disclosure posed by the training regime; and (ii) an Attacks package that provides post-hoc SDC by rigorously assessing the empirical disclosure risk of a model through a variety of simulated attacks after training. The AI-SDC code and documentation are available under an MIT license at https://github.com/AI-SDC/AI-SDC.
GRAIMATTER Green Paper: Recommendations for disclosure control of trained Machine Learning (ML) models from Trusted Research Environments (TREs)
Nov 03, 2022



TREs are widely, and increasingly used to support statistical analysis of sensitive data across a range of sectors (e.g., health, police, tax and education) as they enable secure and transparent research whilst protecting data confidentiality. There is an increasing desire from academia and industry to train AI models in TREs. The field of AI is developing quickly with applications including spotting human errors, streamlining processes, task automation and decision support. These complex AI models require more information to describe and reproduce, increasing the possibility that sensitive personal data can be inferred from such descriptions. TREs do not have mature processes and controls against these risks. This is a complex topic, and it is unreasonable to expect all TREs to be aware of all risks or that TRE researchers have addressed these risks in AI-specific training. GRAIMATTER has developed a draft set of usable recommendations for TREs to guard against the additional risks when disclosing trained AI models from TREs. The development of these recommendations has been funded by the GRAIMATTER UKRI DARE UK sprint research project. This version of our recommendations was published at the end of the project in September 2022. During the course of the project, we have identified many areas for future investigations to expand and test these recommendations in practice. Therefore, we expect that this document will evolve over time.
Optimal sizing of a holdout set for safe predictive model updating
Feb 17, 2022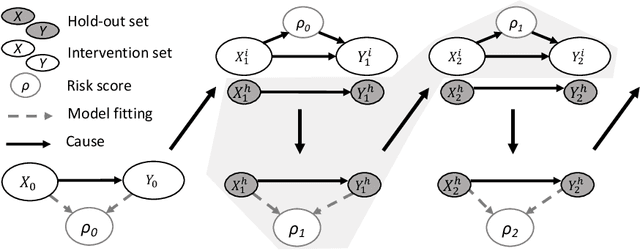
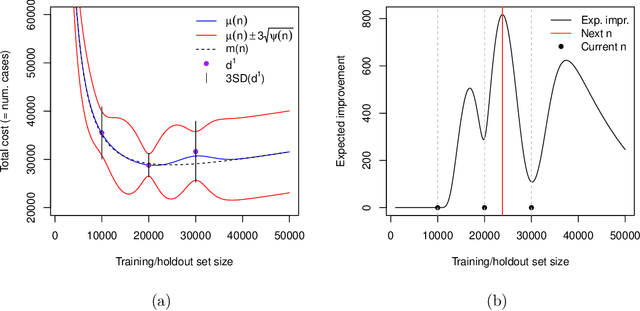
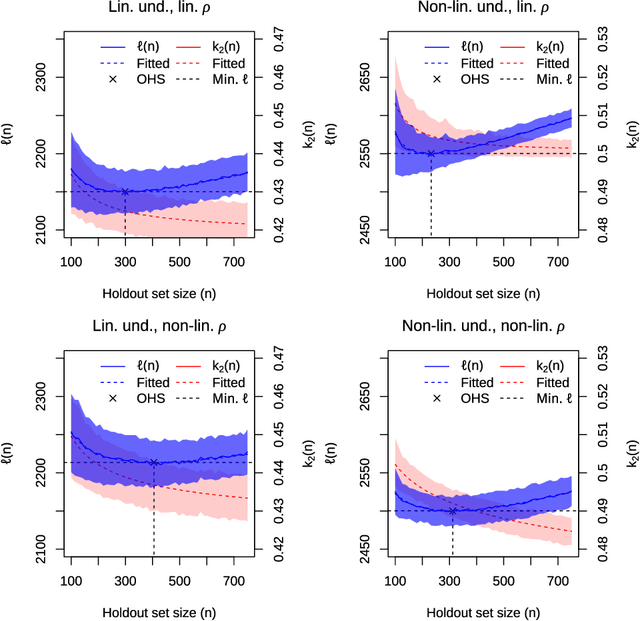
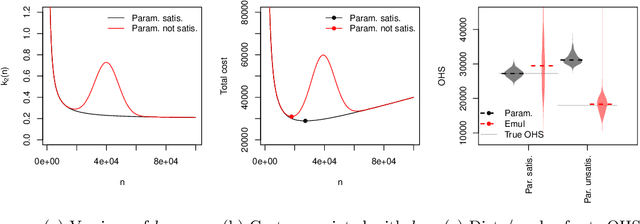
Risk models in medical statistics and healthcare machine learning are increasingly used to guide clinical or other interventions. Should a model be updated after a guided intervention, it may lead to its own failure at making accurate predictions. The use of a `holdout set' -- a subset of the population that does not receive interventions guided by the model -- has been proposed to prevent this. Since patients in the holdout set do not benefit from risk predictions, the chosen size must trade off maximising model performance whilst minimising the number of held out patients. By defining a general loss function, we prove the existence and uniqueness of an optimal holdout set size, and introduce parametric and semi-parametric algorithms for its estimation. We demonstrate their use on a recent risk score for pre-eclampsia. Based on these results, we argue that a holdout set is a safe, viable and easily implemented solution to the model update problem.
Model updating after interventions paradoxically introduces bias
Oct 22, 2020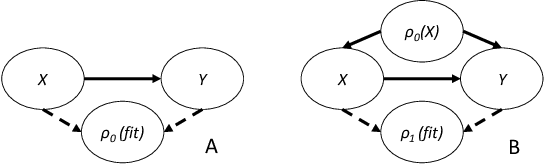
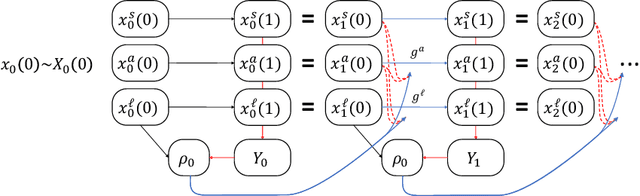
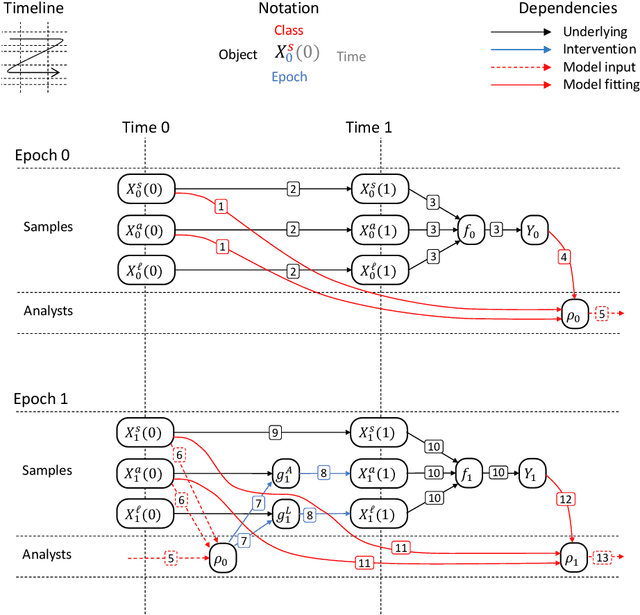
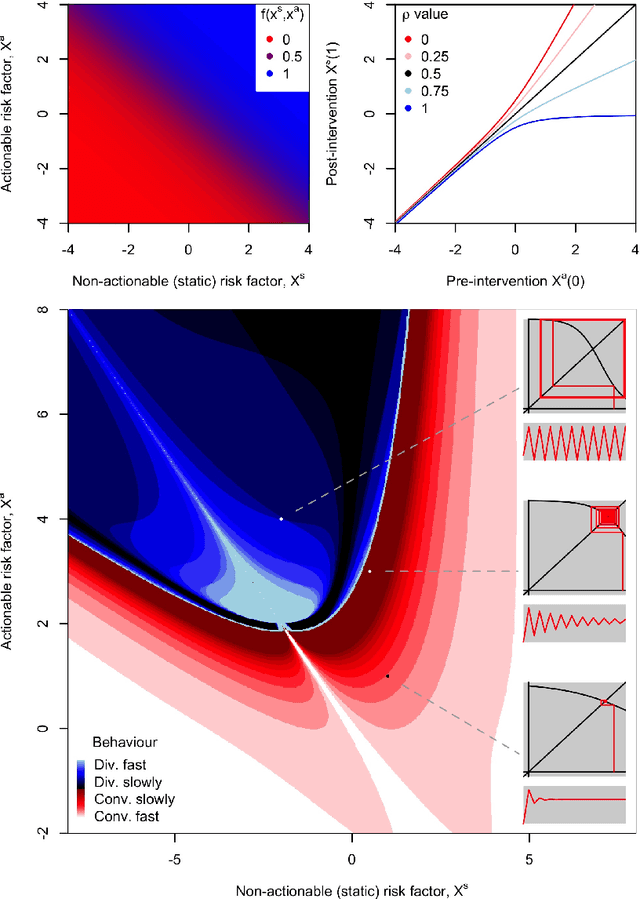
Machine learning is increasingly being used to generate prediction models for use in a number of real-world settings, from credit risk assessment to clinical decision support. Recent discussions have highlighted potential problems in the updating of a predictive score for a binary outcome when an existing predictive score forms part of the standard workflow, driving interventions. In this setting, the existing score induces an additional causative pathway which leads to miscalibration when the original score is replaced. We propose a general causal framework to describe and address this problem, and demonstrate an equivalent formulation as a partially observed Markov decision process. We use this model to demonstrate the impact of such `naive updating' when performed repeatedly. Namely, we show that successive predictive scores may converge to a point where they predict their own effect, or may eventually oscillate between two values, and we argue that neither outcome is desirable. Furthermore, we demonstrate that even if model-fitting procedures improve, actual performance may worsen. We complement these findings with a discussion of several potential routes to overcome these problems.