 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEthical considerations of use of hold-out sets in clinical prediction model management
Jun 05, 2024Clinical prediction models are statistical or machine learning models used to quantify the risk of a certain health outcome using patient data. These can then inform potential interventions on patients, causing an effect called performative prediction: predictions inform interventions which influence the outcome they were trying to predict, leading to a potential underestimation of risk in some patients if a model is updated on this data. One suggested resolution to this is the use of hold-out sets, in which a set of patients do not receive model derived risk scores, such that a model can be safely retrained. We present an overview of clinical and research ethics regarding potential implementation of hold-out sets for clinical prediction models in health settings. We focus on the ethical principles of beneficence, non-maleficence, autonomy and justice. We also discuss informed consent, clinical equipoise, and truth-telling. We present illustrative cases of potential hold-out set implementations and discuss statistical issues arising from different hold-out set sampling methods. We also discuss differences between hold-out sets and randomised control trials, in terms of ethics and statistical issues. Finally, we give practical recommendations for researchers interested in the use hold-out sets for clinical prediction models.
Model updating after interventions paradoxically introduces bias
Oct 22, 2020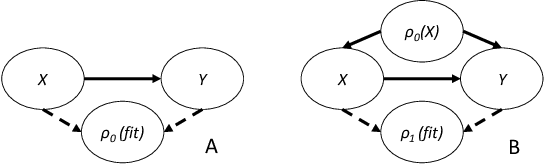
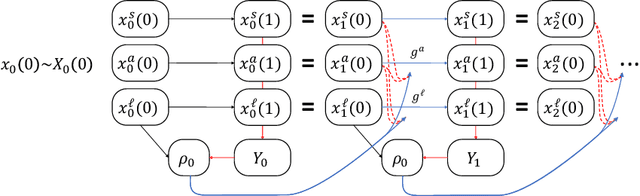
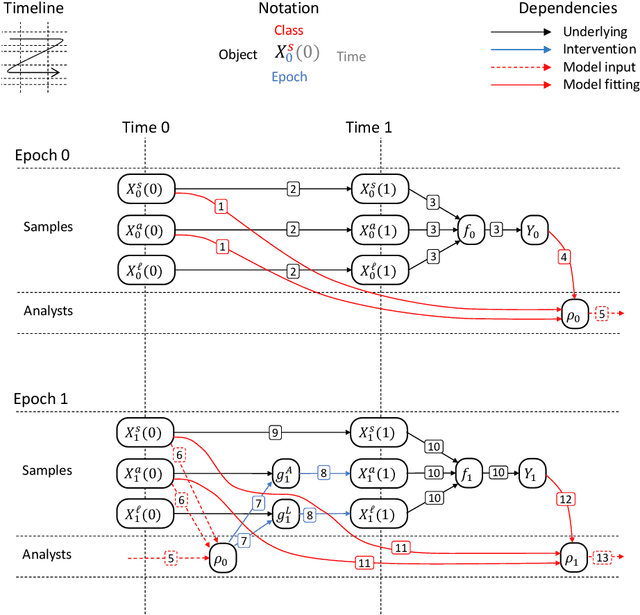
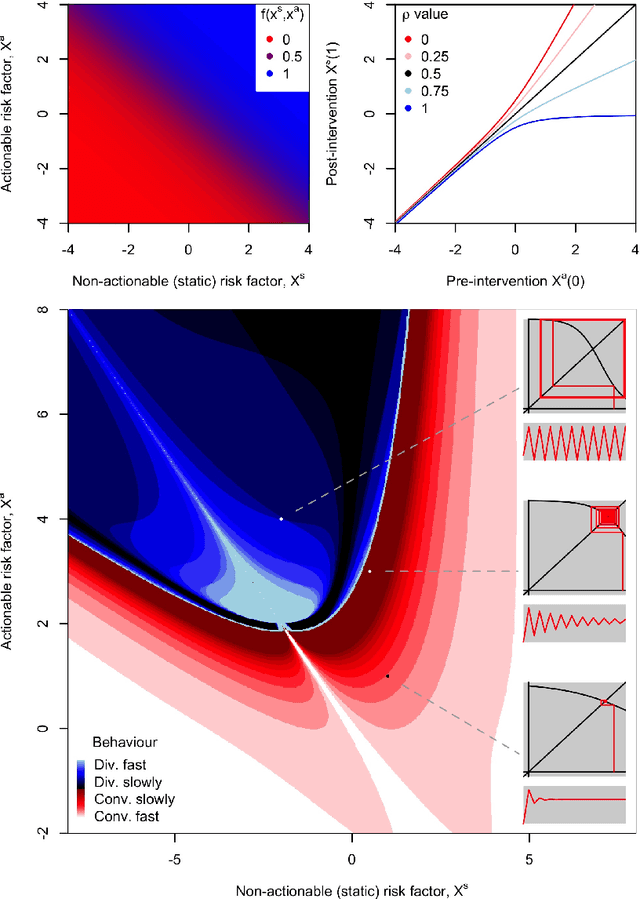
Machine learning is increasingly being used to generate prediction models for use in a number of real-world settings, from credit risk assessment to clinical decision support. Recent discussions have highlighted potential problems in the updating of a predictive score for a binary outcome when an existing predictive score forms part of the standard workflow, driving interventions. In this setting, the existing score induces an additional causative pathway which leads to miscalibration when the original score is replaced. We propose a general causal framework to describe and address this problem, and demonstrate an equivalent formulation as a partially observed Markov decision process. We use this model to demonstrate the impact of such `naive updating' when performed repeatedly. Namely, we show that successive predictive scores may converge to a point where they predict their own effect, or may eventually oscillate between two values, and we argue that neither outcome is desirable. Furthermore, we demonstrate that even if model-fitting procedures improve, actual performance may worsen. We complement these findings with a discussion of several potential routes to overcome these problems.