 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal sizing of a holdout set for safe predictive model updating
Feb 17, 2022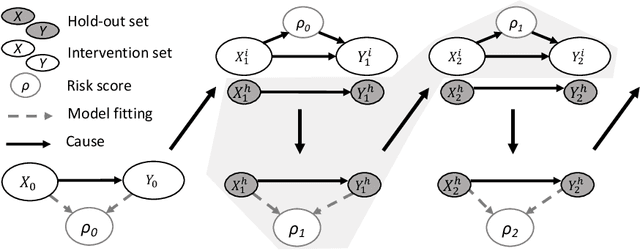
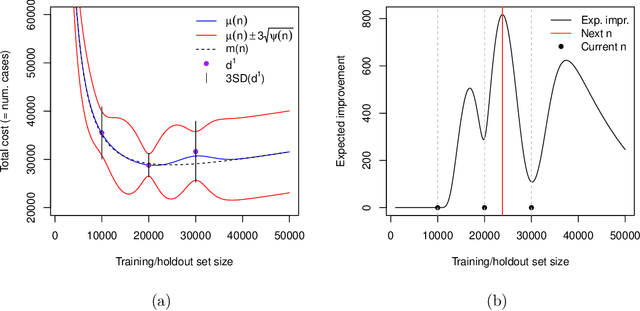
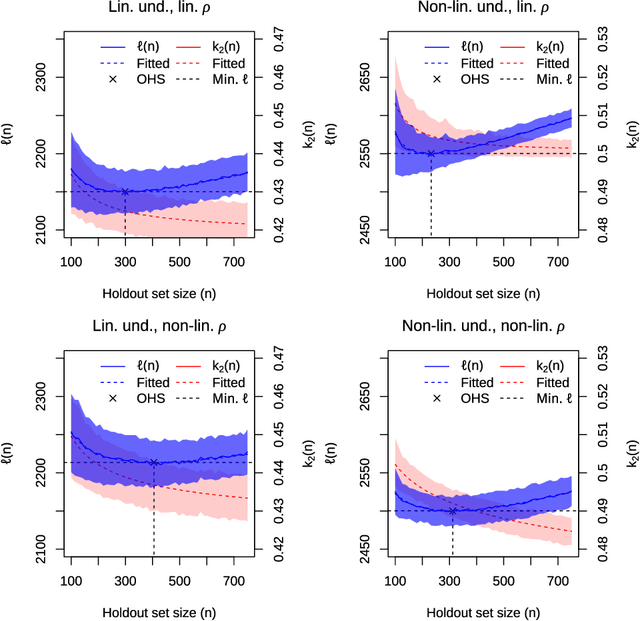
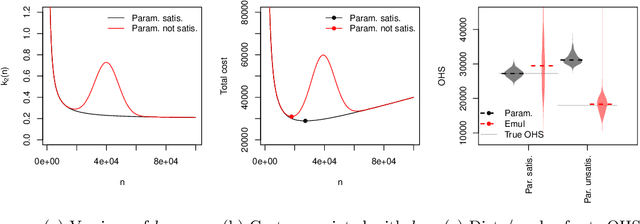
Risk models in medical statistics and healthcare machine learning are increasingly used to guide clinical or other interventions. Should a model be updated after a guided intervention, it may lead to its own failure at making accurate predictions. The use of a `holdout set' -- a subset of the population that does not receive interventions guided by the model -- has been proposed to prevent this. Since patients in the holdout set do not benefit from risk predictions, the chosen size must trade off maximising model performance whilst minimising the number of held out patients. By defining a general loss function, we prove the existence and uniqueness of an optimal holdout set size, and introduce parametric and semi-parametric algorithms for its estimation. We demonstrate their use on a recent risk score for pre-eclampsia. Based on these results, we argue that a holdout set is a safe, viable and easily implemented solution to the model update problem.
Model updating after interventions paradoxically introduces bias
Oct 22, 2020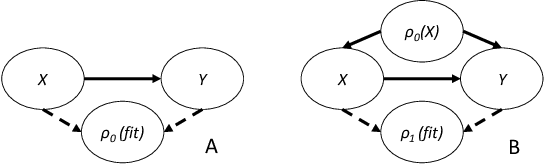
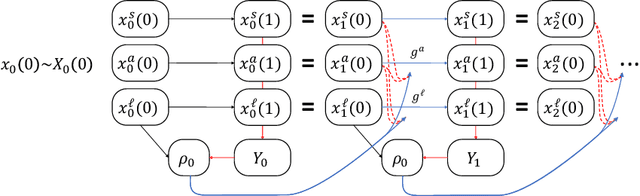
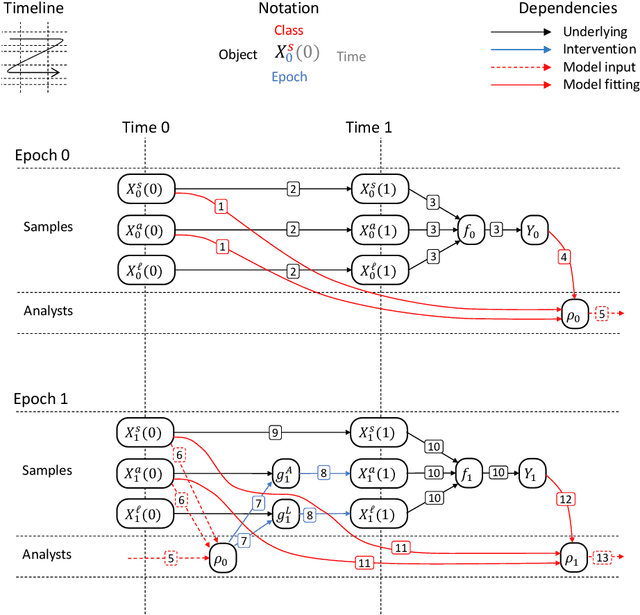
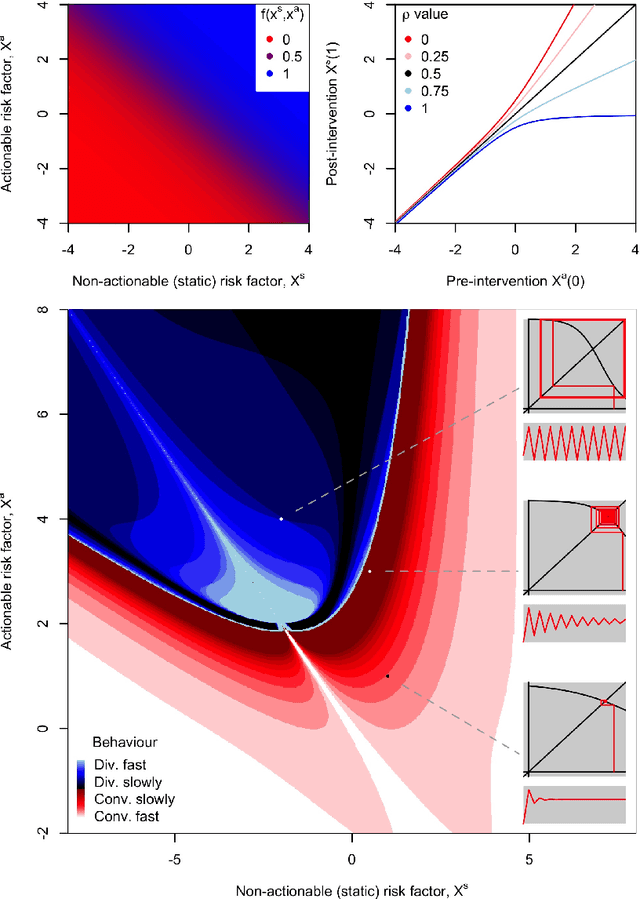
Machine learning is increasingly being used to generate prediction models for use in a number of real-world settings, from credit risk assessment to clinical decision support. Recent discussions have highlighted potential problems in the updating of a predictive score for a binary outcome when an existing predictive score forms part of the standard workflow, driving interventions. In this setting, the existing score induces an additional causative pathway which leads to miscalibration when the original score is replaced. We propose a general causal framework to describe and address this problem, and demonstrate an equivalent formulation as a partially observed Markov decision process. We use this model to demonstrate the impact of such `naive updating' when performed repeatedly. Namely, we show that successive predictive scores may converge to a point where they predict their own effect, or may eventually oscillate between two values, and we argue that neither outcome is desirable. Furthermore, we demonstrate that even if model-fitting procedures improve, actual performance may worsen. We complement these findings with a discussion of several potential routes to overcome these problems.