 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRAIMATTER Green Paper: Recommendations for disclosure control of trained Machine Learning (ML) models from Trusted Research Environments (TREs)
Nov 03, 2022



TREs are widely, and increasingly used to support statistical analysis of sensitive data across a range of sectors (e.g., health, police, tax and education) as they enable secure and transparent research whilst protecting data confidentiality. There is an increasing desire from academia and industry to train AI models in TREs. The field of AI is developing quickly with applications including spotting human errors, streamlining processes, task automation and decision support. These complex AI models require more information to describe and reproduce, increasing the possibility that sensitive personal data can be inferred from such descriptions. TREs do not have mature processes and controls against these risks. This is a complex topic, and it is unreasonable to expect all TREs to be aware of all risks or that TRE researchers have addressed these risks in AI-specific training. GRAIMATTER has developed a draft set of usable recommendations for TREs to guard against the additional risks when disclosing trained AI models from TREs. The development of these recommendations has been funded by the GRAIMATTER UKRI DARE UK sprint research project. This version of our recommendations was published at the end of the project in September 2022. During the course of the project, we have identified many areas for future investigations to expand and test these recommendations in practice. Therefore, we expect that this document will evolve over time.
Machine Learning Models Disclosure from Trusted Research Environments (TRE), Challenges and Opportunities
Nov 10, 2021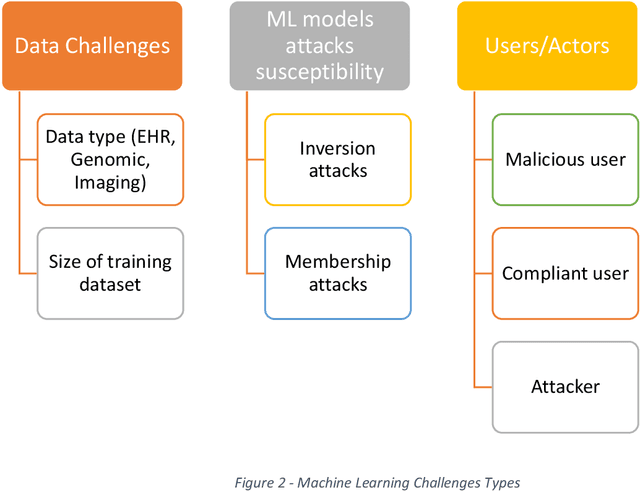
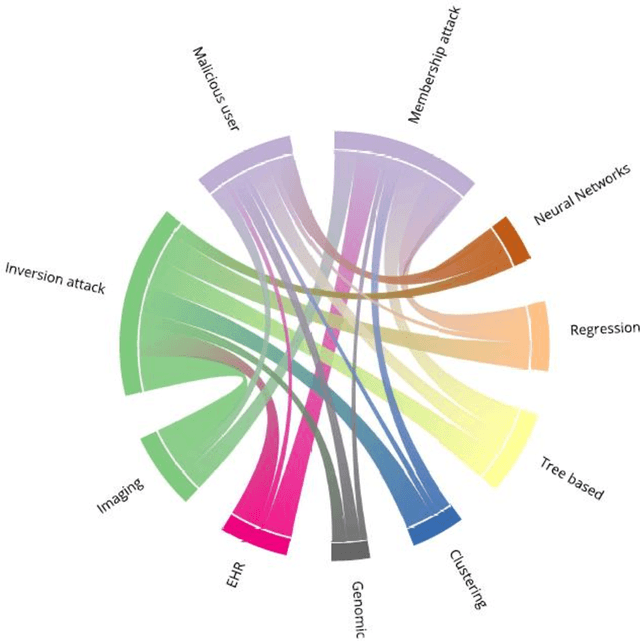
Trusted Research environments (TRE)s are safe and secure environments in which researchers can access sensitive data. With the growth and diversity of medical data such as Electronic Health Records (EHR), Medical Imaging and Genomic data, there is an increase in the use of Artificial Intelligence (AI) in general and the subfield of Machine Learning (ML) in particular in the healthcare domain. This generates the desire to disclose new types of outputs from TREs, such as trained machine learning models. Although specific guidelines and policies exists for statistical disclosure controls in TREs, they do not satisfactorily cover these new types of output request. In this paper, we define some of the challenges around the application and disclosure of machine learning for healthcare within TREs. We describe various vulnerabilities the introduction of AI brings to TREs. We also provide an introduction to the different types and levels of risks associated with the disclosure of trained ML models. We finally describe the new research opportunities in developing and adapting policies and tools for safely disclosing machine learning outputs from TREs.