 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA hierarchical approach for assessing the vulnerability of tree-based classification models to membership inference attack
Feb 13, 2025Machine learning models can inadvertently expose confidential properties of their training data, making them vulnerable to membership inference attacks (MIA). While numerous evaluation methods exist, many require computationally expensive processes, such as training multiple shadow models. This article presents two new complementary approaches for efficiently identifying vulnerable tree-based models: an ante-hoc analysis of hyperparameter choices and a post-hoc examination of trained model structure. While these new methods cannot certify whether a model is safe from MIA, they provide practitioners with a means to significantly reduce the number of models that need to undergo expensive MIA assessment through a hierarchical filtering approach. More specifically, it is shown that the rank order of disclosure risk for different hyperparameter combinations remains consistent across datasets, enabling the development of simple, human-interpretable rules for identifying relatively high-risk models before training. While this ante-hoc analysis cannot determine absolute safety since this also depends on the specific dataset, it allows the elimination of unnecessarily risky configurations during hyperparameter tuning. Additionally, computationally inexpensive structural metrics serve as indicators of MIA vulnerability, providing a second filtering stage to identify risky models after training but before conducting expensive attacks. Empirical results show that hyperparameter-based risk prediction rules can achieve high accuracy in predicting the most at risk combinations of hyperparameters across different tree-based model types, while requiring no model training. Moreover, target model accuracy is not seen to correlate with privacy risk, suggesting opportunities to optimise model configurations for both performance and privacy.
Safe machine learning model release from Trusted Research Environments: The AI-SDC package
Dec 06, 2022We present AI-SDC, an integrated suite of open source Python tools to facilitate Statistical Disclosure Control (SDC) of Machine Learning (ML) models trained on confidential data prior to public release. AI-SDC combines (i) a SafeModel package that extends commonly used ML models to provide ante-hoc SDC by assessing the vulnerability of disclosure posed by the training regime; and (ii) an Attacks package that provides post-hoc SDC by rigorously assessing the empirical disclosure risk of a model through a variety of simulated attacks after training. The AI-SDC code and documentation are available under an MIT license at https://github.com/AI-SDC/AI-SDC.
ACRO: A multi-language toolkit for supporting Automated Checking of Research Outputs
Dec 06, 2022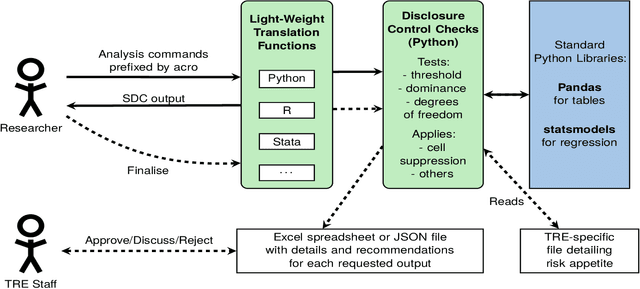
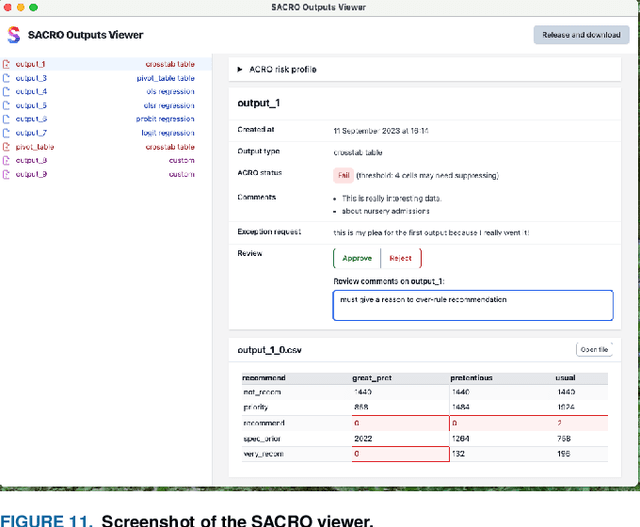
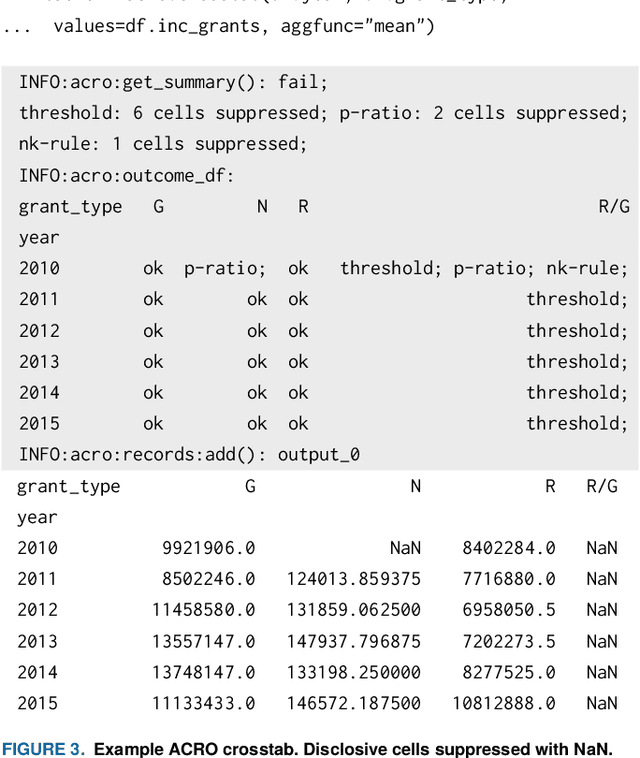
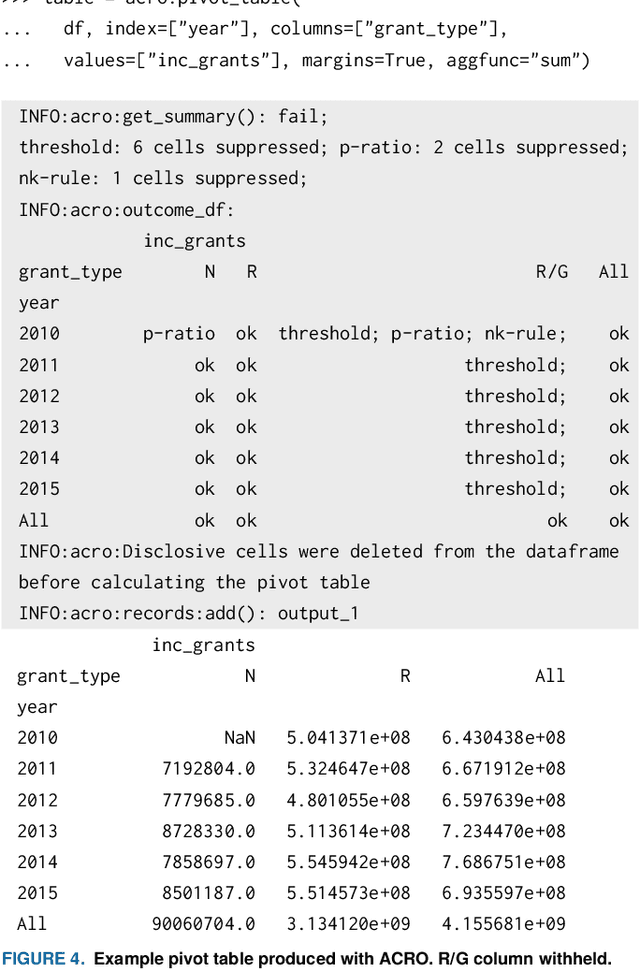
This paper discusses the development of an open source tool ACRO, (Automatic Checking of Research Outputs) to assist researchers and data governance teams by distinguishing between: research output that is safe to publish; output that requires further analysis; and output that cannot be published because it creates substantial risk of disclosing private data. ACRO extends the functionality and accessibility of a previous prototype by providing a light-weight 'skin' that sits over well-known analysis tools, and enables access in a variety of programming languages researchers might use. This adds functionality to (i) identify potentially disclosive outputs against a range of commonly used disclosure tests; (ii) suppress outputs where required; (iii) report reasons for suppression; and (iv) produce simple summary documents Trusted Research Environment (TRE) staff can use to streamline their workflow. The ACRO code and documentation are available under an MIT license at https://github.com/AI-SDC/ACRO
GRAIMATTER Green Paper: Recommendations for disclosure control of trained Machine Learning (ML) models from Trusted Research Environments (TREs)
Nov 03, 2022



TREs are widely, and increasingly used to support statistical analysis of sensitive data across a range of sectors (e.g., health, police, tax and education) as they enable secure and transparent research whilst protecting data confidentiality. There is an increasing desire from academia and industry to train AI models in TREs. The field of AI is developing quickly with applications including spotting human errors, streamlining processes, task automation and decision support. These complex AI models require more information to describe and reproduce, increasing the possibility that sensitive personal data can be inferred from such descriptions. TREs do not have mature processes and controls against these risks. This is a complex topic, and it is unreasonable to expect all TREs to be aware of all risks or that TRE researchers have addressed these risks in AI-specific training. GRAIMATTER has developed a draft set of usable recommendations for TREs to guard against the additional risks when disclosing trained AI models from TREs. The development of these recommendations has been funded by the GRAIMATTER UKRI DARE UK sprint research project. This version of our recommendations was published at the end of the project in September 2022. During the course of the project, we have identified many areas for future investigations to expand and test these recommendations in practice. Therefore, we expect that this document will evolve over time.
Machine Learning Models Disclosure from Trusted Research Environments (TRE), Challenges and Opportunities
Nov 10, 2021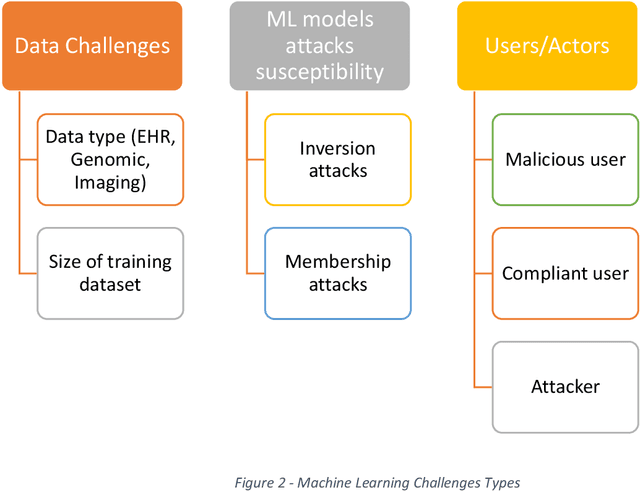
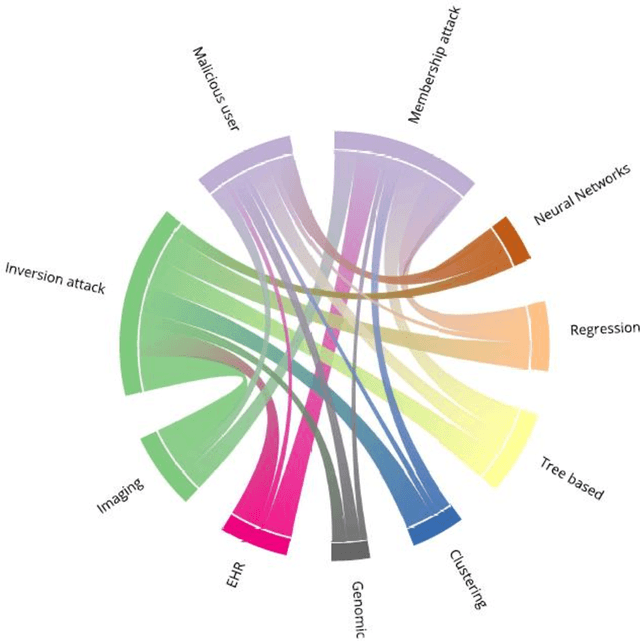
Trusted Research environments (TRE)s are safe and secure environments in which researchers can access sensitive data. With the growth and diversity of medical data such as Electronic Health Records (EHR), Medical Imaging and Genomic data, there is an increase in the use of Artificial Intelligence (AI) in general and the subfield of Machine Learning (ML) in particular in the healthcare domain. This generates the desire to disclose new types of outputs from TREs, such as trained machine learning models. Although specific guidelines and policies exists for statistical disclosure controls in TREs, they do not satisfactorily cover these new types of output request. In this paper, we define some of the challenges around the application and disclosure of machine learning for healthcare within TREs. We describe various vulnerabilities the introduction of AI brings to TREs. We also provide an introduction to the different types and levels of risks associated with the disclosure of trained ML models. We finally describe the new research opportunities in developing and adapting policies and tools for safely disclosing machine learning outputs from TREs.
Protein Structured Reservoir computing for Spike-based Pattern Recognition
Aug 07, 2020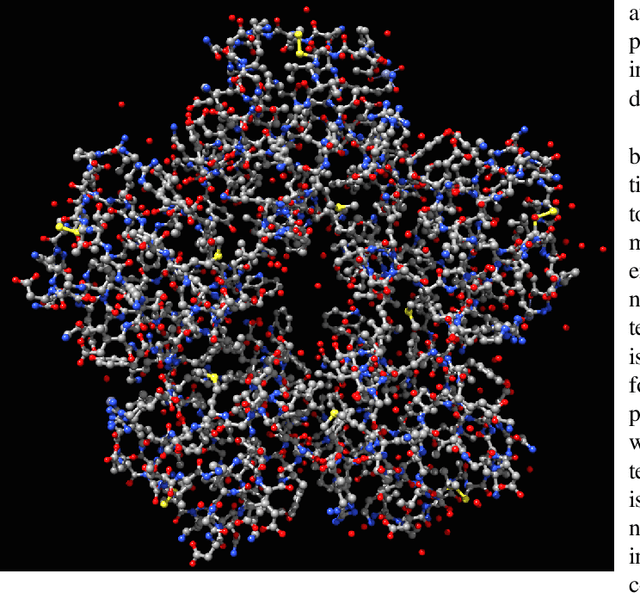
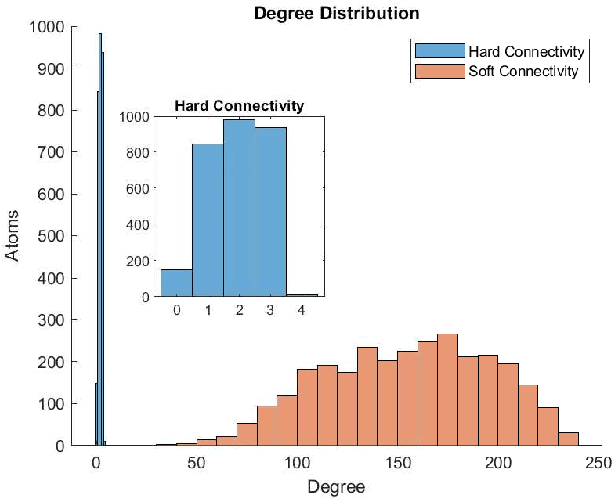

Nowadays we witness a miniaturisation trend in the semiconductor industry backed up by groundbreaking discoveries and designs in nanoscale characterisation and fabrication. To facilitate the trend and produce ever smaller, faster and cheaper computing devices, the size of nanoelectronic devices is now reaching the scale of atoms or molecules - a technical goal undoubtedly demanding for novel devices. Following the trend, we explore an unconventional route of implementing a reservoir computing on a single protein molecule and introduce neuromorphic connectivity with a small-world networking property. We have chosen Izhikevich spiking neurons as elementary processors, corresponding to the atoms of verotoxin protein, and its molecule as a 'hardware' architecture of the communication networks connecting the processors. We apply on a single readout layer various training methods in a supervised fashion to investigate whether the molecular structured Reservoir Computing (RC) system is capable to deal with machine learning benchmarks. We start with the Remote Supervised Method, based on Spike-Timing-Dependent-Plasticity, and carry on with linear regression and scaled conjugate gradient back-propagation training methods. The RC network is evaluated as a proof-of-concept on the handwritten digit images from the MNIST dataset and demonstrates acceptable classification accuracy in comparison with other similar approaches.
Evolutionary n-level Hypergraph Partitioning with Adaptive Coarsening
Oct 08, 2018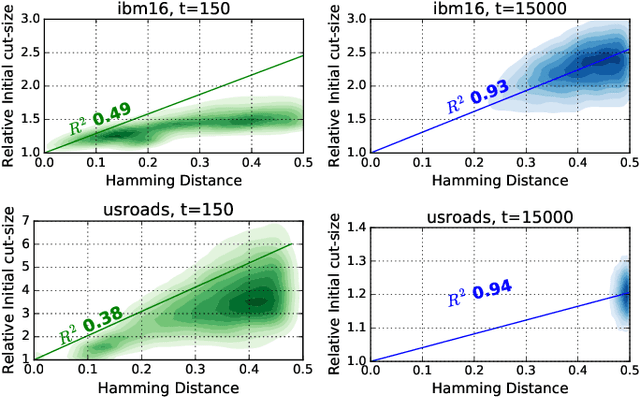
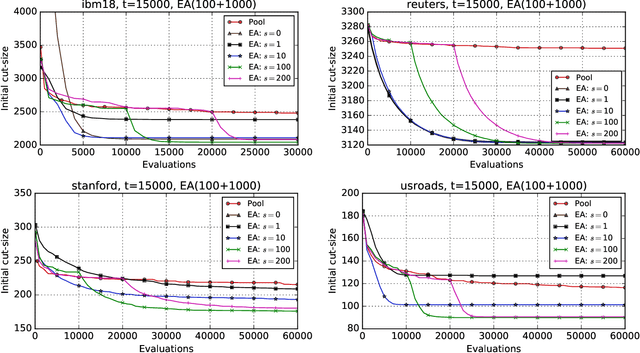
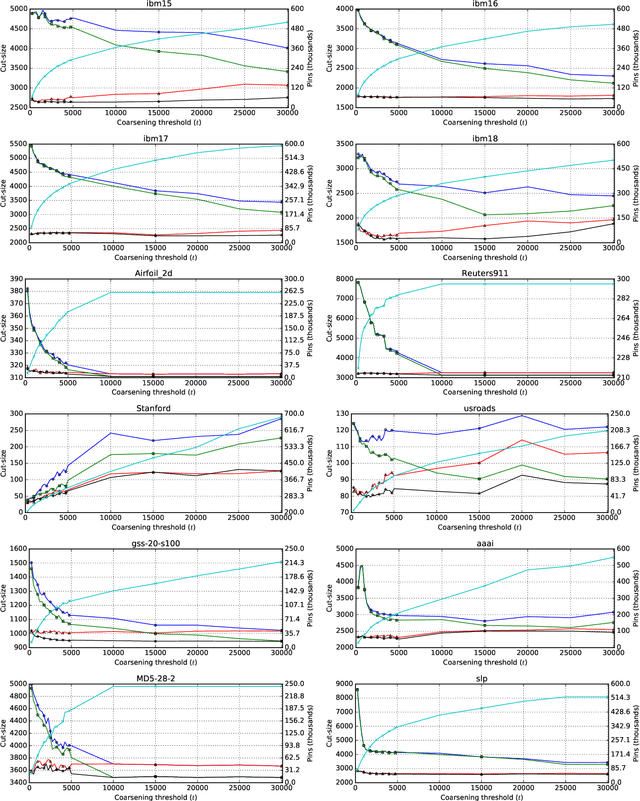
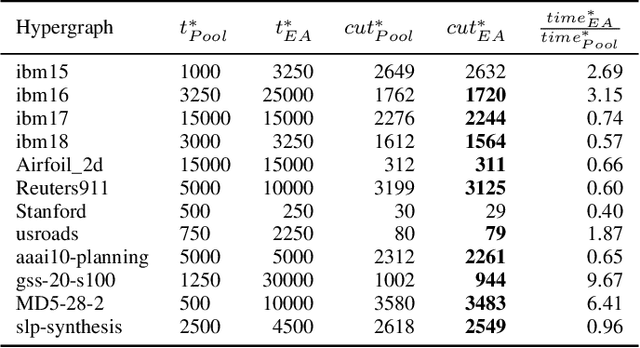
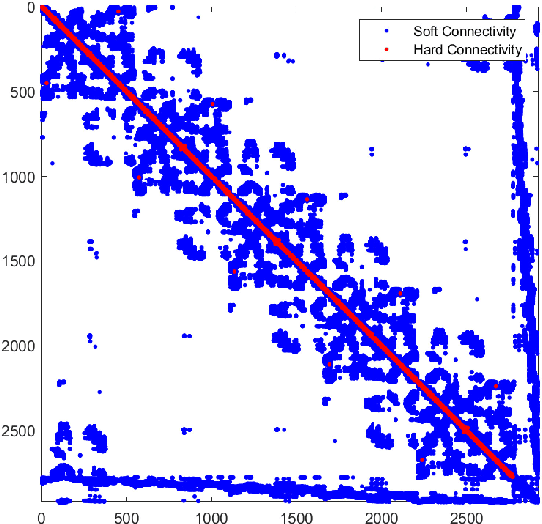
Hypergraph partitioning is an NP-hard problem that occurs in many computer science applications where it is necessary to reduce large problems into a number of smaller, computationally tractable sub-problems. Current techniques use a multilevel approach wherein an initial partitioning is performed after compressing the hypergraph to a predetermined level. This level is typically chosen to produce very coarse hypergraphs in which heuristic algorithms are fast and effective. This article presents a novel memetic algorithm which remains effective on larger initial hypergraphs. This enables the exploitation of information that can be lost during coarsening and results in improved final solution quality. We use this algorithm to present an empirical analysis of the space of possible initial hypergraphs in terms of its searchability at different levels of coarsening. We find that the best results arise at coarsening levels unique to each hypergraph. Based on this, we introduce an adaptive scheme that stops coarsening when the rate of information loss in a hypergraph becomes non-linear and show that this produces further improvements. The results show that we have identified a valuable role for evolutionary algorithms within the current state-of-the-art hypergraph partitioning framework.
Interactive Ant Colony Optimisation (iACO) for Early Lifecycle Software Design
Jun 23, 2014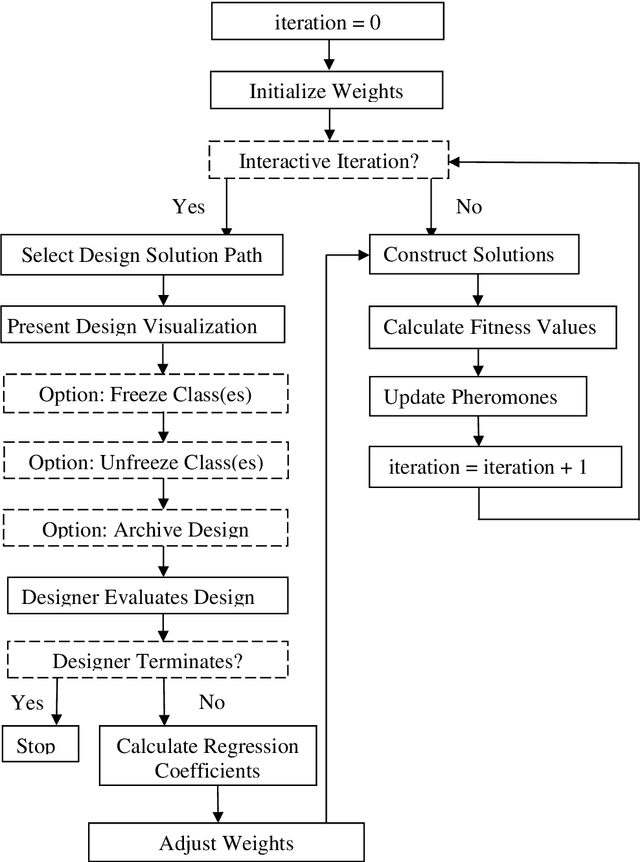
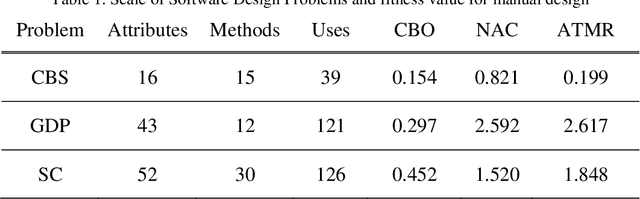

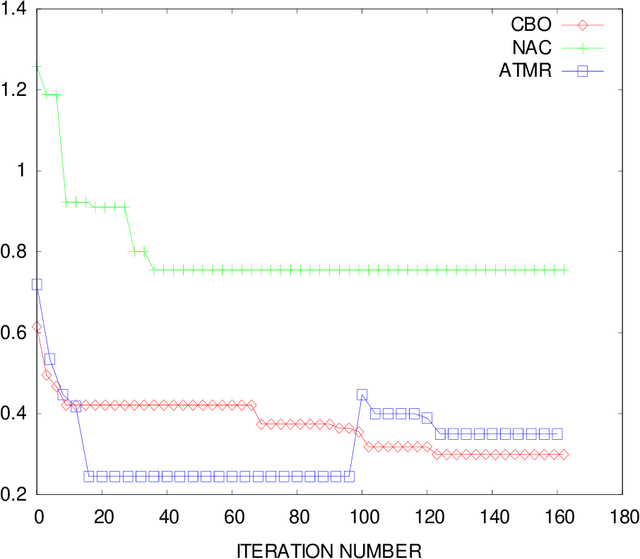
Software design is crucial to successful software development, yet is a demanding multi-objective problem for software engineers. In an attempt to assist the software designer, interactive (i.e. human in-the-loop) meta-heuristic search techniques such as evolutionary computing have been applied and show promising results. Recent investigations have also shown that Ant Colony Optimization (ACO) can outperform evolutionary computing as a potential search engine for interactive software design. With a limited computational budget, ACO produces superior candidate design solutions in a smaller number of iterations. Building on these findings, we propose a novel interactive ACO (iACO) approach to assist the designer in early lifecycle software design, in which the search is steered jointly by subjective designer evaluation as well as machine fitness functions relating the structural integrity and surrogate elegance of software designs. Results show that iACO is speedy, responsive and highly effective in enabling interactive, dynamic multi-objective search in early lifecycle software design. Study participants rate the iACO search experience as compelling. Results of machine learning of fitness measure weightings indicate that software design elegance does indeed play a significant role in designer evaluation of candidate software design. We conclude that the evenness of the number of attributes and methods among classes (NAC) is a significant surrogate elegance measure, which in turn suggests that this evenness of distribution, when combined with structural integrity, is an implicit but crucial component of effective early lifecycle software design.