 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Distribution Alignment with Diversity-based Sampling
Oct 05, 2024Domain shifts are ubiquitous in machine learning, and can substantially degrade a model's performance when deployed to real-world data. To address this, distribution alignment methods aim to learn feature representations which are invariant across domains, by minimising the discrepancy between the distributions. However, the discrepancy estimates can be extremely noisy when training via stochastic gradient descent (SGD), and shifts in the relative proportions of different subgroups can lead to domain misalignments; these can both stifle the benefits of the method. This paper proposes to improve these estimates by inducing diversity in each sampled minibatch. This simultaneously balances the data and reduces the variance of the gradients, thereby enhancing the model's generalisation ability. We describe two options for diversity-based data samplers, based on the k-determinantal point process (k-DPP) and the k-means++ algorithm, which can function as drop-in replacements for a standard random sampler. On a real-world domain shift task of bioacoustic event detection, we show that both options 1) yield minibatches which are more representative of the full dataset; 2) reduce the distance estimation error between distributions, for a given sample size; and 3) improve out-of-distribution accuracy for two distribution alignment algorithms, as well as standard ERM.
Unsupervised Domain Adaptation Via Data Pruning
Sep 18, 2024



The removal of carefully-selected examples from training data has recently emerged as an effective way of improving the robustness of machine learning models. However, the best way to select these examples remains an open question. In this paper, we consider the problem from the perspective of unsupervised domain adaptation (UDA). We propose AdaPrune, a method for UDA whereby training examples are removed to attempt to align the training distribution to that of the target data. By adopting the maximum mean discrepancy (MMD) as the criterion for alignment, the problem can be neatly formulated and solved as an integer quadratic program. We evaluate our approach on a real-world domain shift task of bioacoustic event detection. As a method for UDA, we show that AdaPrune outperforms related techniques, and is complementary to other UDA algorithms such as CORAL. Our analysis of the relationship between the MMD and model accuracy, along with t-SNE plots, validate the proposed method as a principled and well-founded way of performing data pruning.
Clustering-Based Validation Splits for Domain Generalisation
May 29, 2024This paper considers the problem of model selection under domain shift. In this setting, it is proposed that a high maximum mean discrepancy (MMD) between the training and validation sets increases the generalisability of selected models. A data splitting algorithm based on kernel k-means clustering, which maximises this objective, is presented. The algorithm leverages linear programming to control the size, label, and (optionally) group distributions of the splits, and comes with convergence guarantees. The technique consistently outperforms alternative splitting strategies across a range of datasets and training algorithms, for both domain generalisation (DG) and unsupervised domain adaptation (UDA) tasks. Analysis also shows the MMD between the training and validation sets to be strongly rank-correlated ($\rho=0.63$) with test domain accuracy, further substantiating the validity of this approach.
Interactive Ant Colony Optimisation (iACO) for Early Lifecycle Software Design
Jun 23, 2014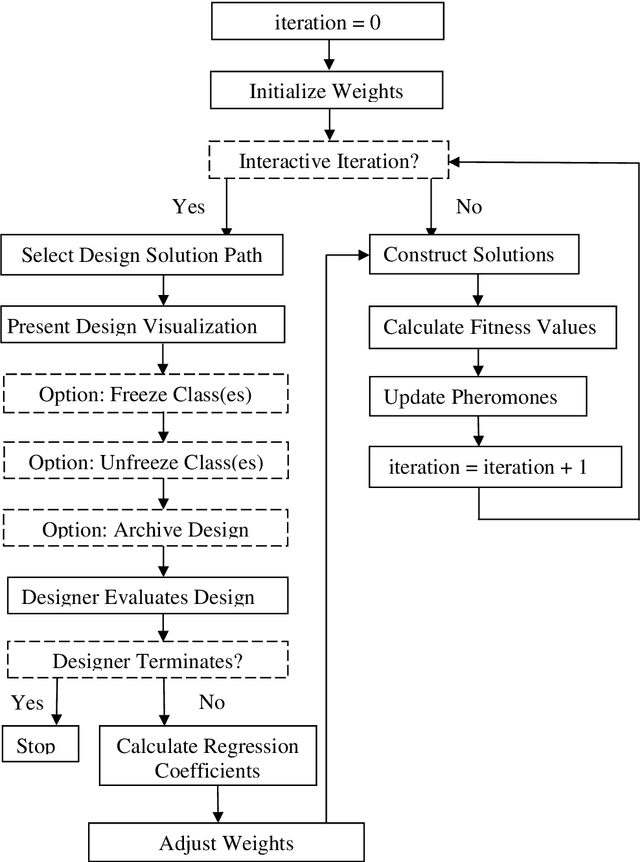
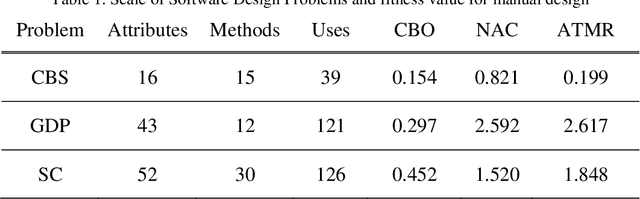

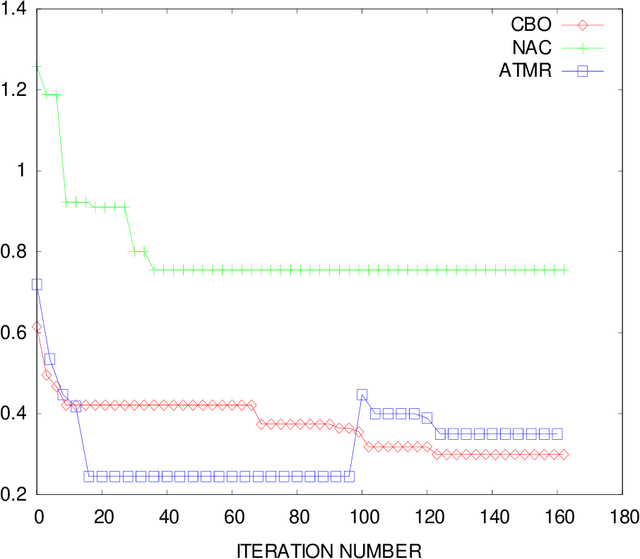
Software design is crucial to successful software development, yet is a demanding multi-objective problem for software engineers. In an attempt to assist the software designer, interactive (i.e. human in-the-loop) meta-heuristic search techniques such as evolutionary computing have been applied and show promising results. Recent investigations have also shown that Ant Colony Optimization (ACO) can outperform evolutionary computing as a potential search engine for interactive software design. With a limited computational budget, ACO produces superior candidate design solutions in a smaller number of iterations. Building on these findings, we propose a novel interactive ACO (iACO) approach to assist the designer in early lifecycle software design, in which the search is steered jointly by subjective designer evaluation as well as machine fitness functions relating the structural integrity and surrogate elegance of software designs. Results show that iACO is speedy, responsive and highly effective in enabling interactive, dynamic multi-objective search in early lifecycle software design. Study participants rate the iACO search experience as compelling. Results of machine learning of fitness measure weightings indicate that software design elegance does indeed play a significant role in designer evaluation of candidate software design. We conclude that the evenness of the number of attributes and methods among classes (NAC) is a significant surrogate elegance measure, which in turn suggests that this evenness of distribution, when combined with structural integrity, is an implicit but crucial component of effective early lifecycle software design.
Building Better Nurse Scheduling Algorithms
Mar 20, 2008
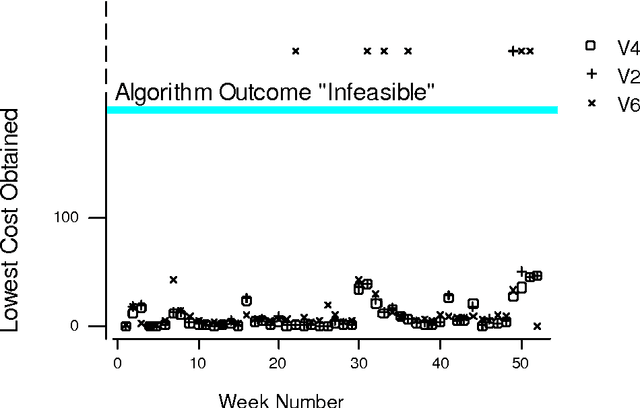
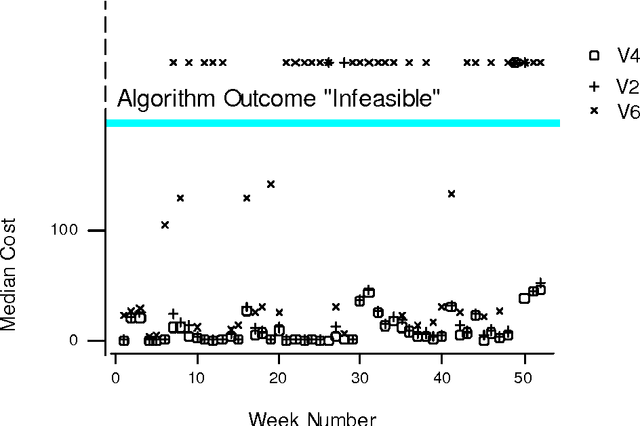
The aim of this research is twofold: Firstly, to model and solve a complex nurse scheduling problem with an integer programming formulation and evolutionary algorithms. Secondly, to detail a novel statistical method of comparing and hence building better scheduling algorithms by identifying successful algorithm modifications. The comparison method captures the results of algorithms in a single figure that can then be compared using traditional statistical techniques. Thus, the proposed method of comparing algorithms is an objective procedure designed to assist in the process of improving an algorithm. This is achieved even when some results are non-numeric or missing due to infeasibility. The final algorithm outperforms all previous evolutionary algorithms, which relied on human expertise for modification.