 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoguided Online Data Curation for Diffusion Model Training
Sep 18, 2025The costs of generative model compute rekindled promises and hopes for efficient data curation. In this work, we investigate whether recently developed autoguidance and online data selection methods can improve the time and sample efficiency of training generative diffusion models. We integrate joint example selection (JEST) and autoguidance into a unified code base for fast ablation and benchmarking. We evaluate combinations of data curation on a controlled 2-D synthetic data generation task as well as (3x64x64)-D image generation. Our comparisons are made at equal wall-clock time and equal number of samples, explicitly accounting for the overhead of selection. Across experiments, autoguidance consistently improves sample quality and diversity. Early AJEST (applying selection only at the beginning of training) can match or modestly exceed autoguidance alone in data efficiency on both tasks. However, its time overhead and added complexity make autoguidance or uniform random data selection preferable in most situations. These findings suggest that while targeted online selection can yield efficiency gains in early training, robust sample quality improvements are primarily driven by autoguidance. We discuss limitations and scope, and outline when data selection may be beneficial.
IGAF: Incremental Guided Attention Fusion for Depth Super-Resolution
Jan 03, 2025Accurate depth estimation is crucial for many fields, including robotics, navigation, and medical imaging. However, conventional depth sensors often produce low-resolution (LR) depth maps, making detailed scene perception challenging. To address this, enhancing LR depth maps to high-resolution (HR) ones has become essential, guided by HR-structured inputs like RGB or grayscale images. We propose a novel sensor fusion methodology for guided depth super-resolution (GDSR), a technique that combines LR depth maps with HR images to estimate detailed HR depth maps. Our key contribution is the Incremental guided attention fusion (IGAF) module, which effectively learns to fuse features from RGB images and LR depth maps, producing accurate HR depth maps. Using IGAF, we build a robust super-resolution model and evaluate it on multiple benchmark datasets. Our model achieves state-of-the-art results compared to all baseline models on the NYU v2 dataset for $\times 4$, $\times 8$, and $\times 16$ upsampling. It also outperforms all baselines in a zero-shot setting on the Middlebury, Lu, and RGB-D-D datasets. Code, environments, and models are available on GitHub.
AI-Enabled sensor fusion of time of flight imaging and mmwave for concealed metal detection
Aug 01, 2024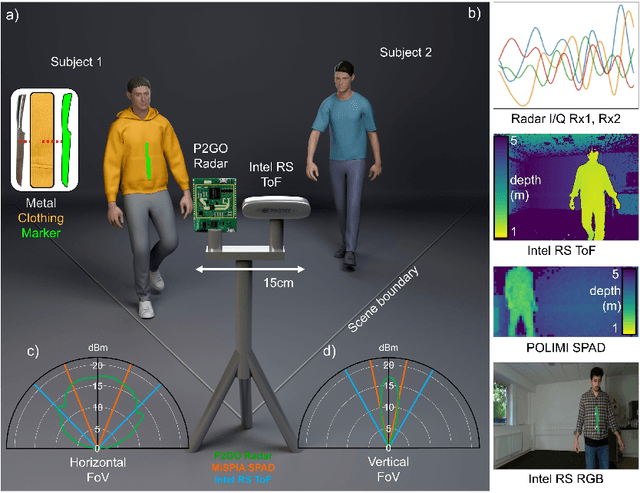
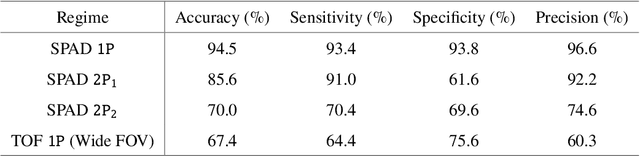
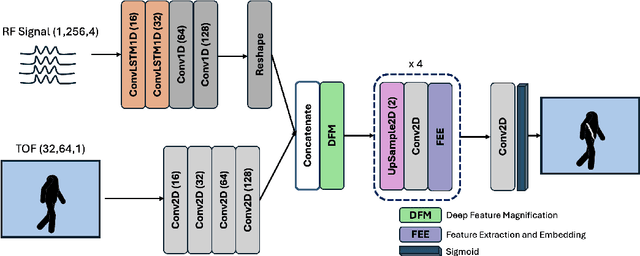

In the field of detection and ranging, multiple complementary sensing modalities may be used to enrich the information obtained from a dynamic scene. One application of this sensor fusion is in public security and surveillance, whose efficacy and privacy protection measures must be continually evaluated. We present a novel deployment of sensor fusion for the discrete detection of concealed metal objects on persons whilst preserving their privacy. This is achieved by coupling off-the-shelf mmWave radar and depth camera technology with a novel neural network architecture that processes the radar signals using convolutional Long Short-term Memory (LSTM) blocks and the depth signal, using convolutional operations. The combined latent features are then magnified using a deep feature magnification to learn cross-modality dependencies in the data. We further propose a decoder, based on the feature extraction and embedding block, to learn an efficient upsampling of the latent space to learn the location of the concealed object in the spatial domain through radar feature guidance. We demonstrate the detection of presence and inference of 3D location of concealed metal objects with an accuracy of up to 95%, using a technique that is robust to multiple persons. This work provides a demonstration of the potential for cost effective and portable sensor fusion, with strong opportunities for further development.
Is One GPU Enough? Pushing Image Generation at Higher-Resolutions with Foundation Models
Jun 12, 2024



In this work, we introduce Pixelsmith, a zero-shot text-to-image generative framework to sample images at higher resolutions with a single GPU. We are the first to show that it is possible to scale the output of a pre-trained diffusion model by a factor of 1000, opening the road for gigapixel image generation at no additional cost. Our cascading method uses the image generated at the lowest resolution as a baseline to sample at higher resolutions. For the guidance, we introduce the Slider, a tunable mechanism that fuses the overall structure contained in the first-generated image with enhanced fine details. At each inference step, we denoise patches rather than the entire latent space, minimizing memory demands such that a single GPU can handle the process, regardless of the image's resolution. Our experimental results show that Pixelsmith not only achieves higher quality and diversity compared to existing techniques, but also reduces sampling time and artifacts. The code for our work is available at https://github.com/Thanos-DB/Pixelsmith.
Single-sample image-fusion upsampling of fluorescence lifetime images
Apr 19, 2024Fluorescence lifetime imaging microscopy (FLIM) provides detailed information about molecular interactions and biological processes. A major bottleneck for FLIM is image resolution at high acquisition speeds, due to the engineering and signal-processing limitations of time-resolved imaging technology. Here we present single-sample image-fusion upsampling (SiSIFUS), a data-fusion approach to computational FLIM super-resolution that combines measurements from a low-resolution time-resolved detector (that measures photon arrival time) and a high-resolution camera (that measures intensity only). To solve this otherwise ill-posed inverse retrieval problem, we introduce statistically informed priors that encode local and global dependencies between the two single-sample measurements. This bypasses the risk of out-of-distribution hallucination as in traditional data-driven approaches and delivers enhanced images compared for example to standard bilinear interpolation. The general approach laid out by SiSIFUS can be applied to other image super-resolution problems where two different datasets are available.
GLFNET: Global-Local (frequency) Filter Networks for efficient medical image segmentation
Mar 01, 2024



We propose a novel transformer-style architecture called Global-Local Filter Network (GLFNet) for medical image segmentation and demonstrate its state-of-the-art performance. We replace the self-attention mechanism with a combination of global-local filter blocks to optimize model efficiency. The global filters extract features from the whole feature map whereas the local filters are being adaptively created as 4x4 patches of the same feature map and add restricted scale information. In particular, the feature extraction takes place in the frequency domain rather than the commonly used spatial (image) domain to facilitate faster computations. The fusion of information from both spatial and frequency spaces creates an efficient model with regards to complexity, required data and performance. We test GLFNet on three benchmark datasets achieving state-of-the-art performance on all of them while being almost twice as efficient in terms of GFLOP operations.
Two-Factor Authentication Approach Based on Behavior Patterns for Defeating Puppet Attacks
Nov 17, 2023



Fingerprint traits are widely recognized for their unique qualities and security benefits. Despite their extensive use, fingerprint features can be vulnerable to puppet attacks, where attackers manipulate a reluctant but genuine user into completing the authentication process. Defending against such attacks is challenging due to the coexistence of a legitimate identity and an illegitimate intent. In this paper, we propose PUPGUARD, a solution designed to guard against puppet attacks. This method is based on user behavioral patterns, specifically, the user needs to press the capture device twice successively with different fingers during the authentication process. PUPGUARD leverages both the image features of fingerprints and the timing characteristics of the pressing intervals to establish two-factor authentication. More specifically, after extracting image features and timing characteristics, and performing feature selection on the image features, PUPGUARD fuses these two features into a one-dimensional feature vector, and feeds it into a one-class classifier to obtain the classification result. This two-factor authentication method emphasizes dynamic behavioral patterns during the authentication process, thereby enhancing security against puppet attacks. To assess PUPGUARD's effectiveness, we conducted experiments on datasets collected from 31 subjects, including image features and timing characteristics. Our experimental results demonstrate that PUPGUARD achieves an impressive accuracy rate of 97.87% and a remarkably low false positive rate (FPR) of 1.89%. Furthermore, we conducted comparative experiments to validate the superiority of combining image features and timing characteristics within PUPGUARD for enhancing resistance against puppet attacks.
A large-scale multimodal dataset of human speech recognition
Mar 15, 2023



Nowadays, non-privacy small-scale motion detection has attracted an increasing amount of research in remote sensing in speech recognition. These new modalities are employed to enhance and restore speech information from speakers of multiple types of data. In this paper, we propose a dataset contains 7.5 GHz Channel Impulse Response (CIR) data from ultra-wideband (UWB) radars, 77-GHz frequency modulated continuous wave (FMCW) data from millimetre wave (mmWave) radar, and laser data. Meanwhile, a depth camera is adopted to record the landmarks of the subject's lip and voice. Approximately 400 minutes of annotated speech profiles are provided, which are collected from 20 participants speaking 5 vowels, 15 words and 16 sentences. The dataset has been validated and has potential for the research of lip reading and multimodal speech recognition.
mmSense: Detecting Concealed Weapons with a Miniature Radar Sensor
Feb 28, 2023



For widespread adoption, public security and surveillance systems must be accurate, portable, compact, and real-time, without impeding the privacy of the individuals being observed. Current systems broadly fall into two categories -- image-based which are accurate, but lack privacy, and RF signal-based, which preserve privacy but lack portability, compactness and accuracy. Our paper proposes mmSense, an end-to-end portable miniaturised real-time system that can accurately detect the presence of concealed metallic objects on persons in a discrete, privacy-preserving modality. mmSense features millimeter wave radar technology, provided by Google's Soli sensor for its data acquisition, and TransDope, our real-time neural network, capable of processing a single radar data frame in 19 ms. mmSense achieves high recognition rates on a diverse set of challenging scenes while running on standard laptop hardware, demonstrating a significant advancement towards creating portable, cost-effective real-time radar based surveillance systems.
Computational imaging with the human brain
Oct 07, 2022
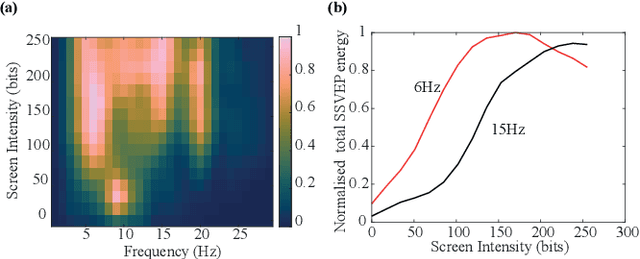


Brain-computer interfaces (BCIs) are enabling a range of new possibilities and routes for augmenting human capability. Here, we propose BCIs as a route towards forms of computation, i.e. computational imaging, that blend the brain with external silicon processing. We demonstrate ghost imaging of a hidden scene using the human visual system that is combined with an adaptive computational imaging scheme. This is achieved through a projection pattern `carving' technique that relies on real-time feedback from the brain to modify patterns at the light projector, thus enabling more efficient and higher resolution imaging. This brain-computer connectivity demonstrates a form of augmented human computation that could in the future extend the sensing range of human vision and provide new approaches to the study of the neurophysics of human perception. As an example, we illustrate a simple experiment whereby image reconstruction quality is affected by simultaneous conscious processing and readout of the perceived light intensities.