 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLLMate: A Multimodal LLM for Weather and Climate Events Forecasting
Sep 27, 2024
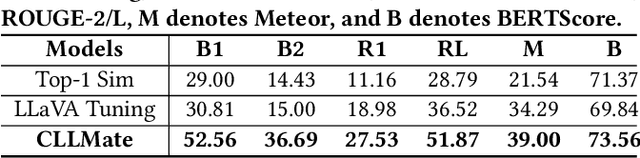

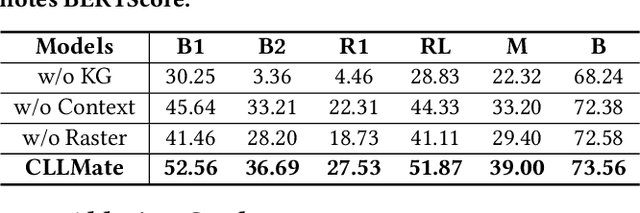
Forecasting weather and climate events is crucial for making appropriate measures to mitigate environmental hazards and minimize associated losses. Previous research on environmental forecasting focuses on predicting numerical meteorological variables related to closed-set events rather than forecasting open-set events directly, which limits the comprehensiveness of event forecasting. We propose Weather and Climate Event Forecasting (WCEF), a new task that leverages meteorological raster data and textual event data to predict potential weather and climate events. However, due to difficulties in aligning multimodal data and the lack of sufficient supervised datasets, this task is challenging to accomplish. Therefore, we first propose a framework to align historical meteorological data with past weather and climate events using the large language model (LLM). In this framework, we construct a knowledge graph by using LLM to extract information about weather and climate events from a corpus of over 41k highly environment-focused news articles. Subsequently, we mapped these events with meteorological raster data, creating a supervised dataset, which is the largest and most novel for LLM tuning on the WCEF task. Finally, we introduced our aligned models, CLLMate (LLM for climate), a multimodal LLM to forecast weather and climate events using meteorological raster data. In evaluating CLLMate, we conducted extensive experiments. The results indicate that CLLMate surpasses both the baselines and other multimodal LLMs, showcasing the potential of utilizing LLM to align weather and climate events with meteorological data and highlighting the promising future for research on the WCEF task.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024



This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
Two-Factor Authentication Approach Based on Behavior Patterns for Defeating Puppet Attacks
Nov 17, 2023



Fingerprint traits are widely recognized for their unique qualities and security benefits. Despite their extensive use, fingerprint features can be vulnerable to puppet attacks, where attackers manipulate a reluctant but genuine user into completing the authentication process. Defending against such attacks is challenging due to the coexistence of a legitimate identity and an illegitimate intent. In this paper, we propose PUPGUARD, a solution designed to guard against puppet attacks. This method is based on user behavioral patterns, specifically, the user needs to press the capture device twice successively with different fingers during the authentication process. PUPGUARD leverages both the image features of fingerprints and the timing characteristics of the pressing intervals to establish two-factor authentication. More specifically, after extracting image features and timing characteristics, and performing feature selection on the image features, PUPGUARD fuses these two features into a one-dimensional feature vector, and feeds it into a one-class classifier to obtain the classification result. This two-factor authentication method emphasizes dynamic behavioral patterns during the authentication process, thereby enhancing security against puppet attacks. To assess PUPGUARD's effectiveness, we conducted experiments on datasets collected from 31 subjects, including image features and timing characteristics. Our experimental results demonstrate that PUPGUARD achieves an impressive accuracy rate of 97.87% and a remarkably low false positive rate (FPR) of 1.89%. Furthermore, we conducted comparative experiments to validate the superiority of combining image features and timing characteristics within PUPGUARD for enhancing resistance against puppet attacks.
A large-scale multimodal dataset of human speech recognition
Mar 15, 2023



Nowadays, non-privacy small-scale motion detection has attracted an increasing amount of research in remote sensing in speech recognition. These new modalities are employed to enhance and restore speech information from speakers of multiple types of data. In this paper, we propose a dataset contains 7.5 GHz Channel Impulse Response (CIR) data from ultra-wideband (UWB) radars, 77-GHz frequency modulated continuous wave (FMCW) data from millimetre wave (mmWave) radar, and laser data. Meanwhile, a depth camera is adopted to record the landmarks of the subject's lip and voice. Approximately 400 minutes of annotated speech profiles are provided, which are collected from 20 participants speaking 5 vowels, 15 words and 16 sentences. The dataset has been validated and has potential for the research of lip reading and multimodal speech recognition.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022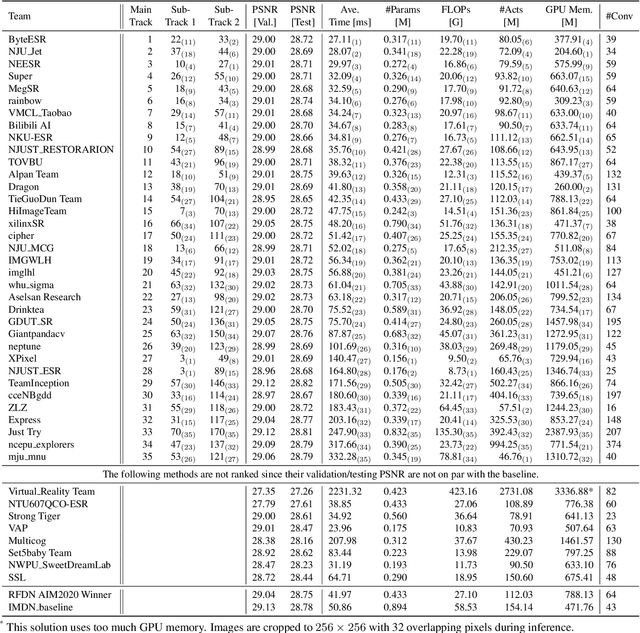
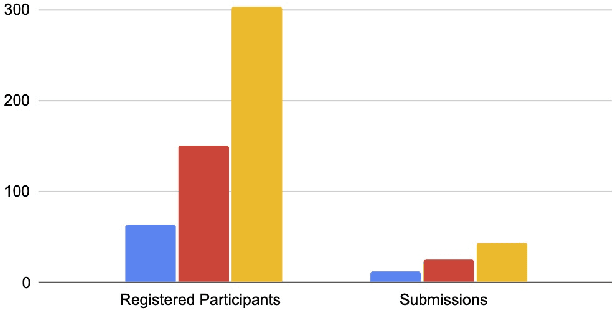
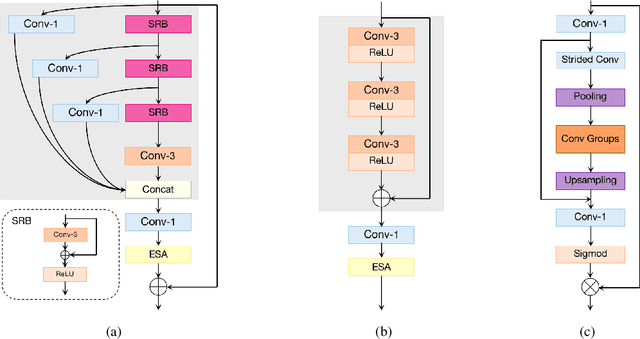
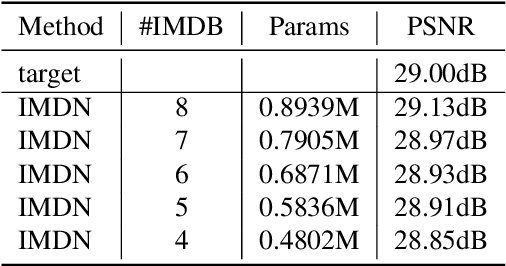
This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.