 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Informed Neural Optimal Control for Precision Immobilization Technique in Emergency Scenarios
Apr 07, 2026Precision Immobilization Technique (PIT) is a potentially effective intervention maneuver for emergency out-of-control vehicle, but its automation is challenged by highly nonlinear collision dynamics, strict safety constraints, and real-time computation requirements. This work presents a PIT-oriented neural optimal-control framework built around PicoPINN (Planning-Informed Compact Physics-Informed Neural Network), a compact physics-informed surrogate obtained through knowledge distillation, hierarchical parameter clustering, and relation-matrix-based parameter reconstruction. A hierarchical neural-OCP (Optimal Control Problem) architecture is then developed, in which an upper virtual decision layer generates PIT decision packages under scenario constraints and a lower coupled-MPC (Model Predictive Control) layer executes interaction-aware control. To evaluate the framework, we construct a PIT Scenario Dataset and conduct surrogate-model comparison, planning-structure ablation, and multi-fidelity assessment from simulation to scaled by-wire vehicle tests. In simulation, adding the upper planning layer improves PIT success rate from 63.8% to 76.7%, and PicoPINN reduces the original PINN parameter count from 8965 to 812 and achieves the smallest average heading error among the learned surrogates (0.112 rad). Scaled vehicle experiments are further used as evidence of control feasibility, with 3 of 4 low-speed controllable-contact PIT trials achieving successful yaw reversal.
GLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
Analyzing Model Misspecification in Quantitative MRI: Application to Perfusion ASL
Feb 10, 2026Quantitative MRI (qMRI) involves parameter estimation governed by an explicit signal model. However, these models are often confounded and difficult to validate in vivo. A model is misspecified when the assumed signal model differs from the true data-generating process. Under misspecification, the variance of any unbiased estimator is lower-bounded by the misspecified Cramer-Rao bound (MCRB), and maximum-likelihood estimates (MLE) may exhibit bias and inconsistency. Based on these principles, we assess misspecification in qMRI using two tests: (i) examining whether empirical MCRB asymptotically approaches the CRB as repeated measurements increase; (ii) comparing MLE estimates from two equal-sized subsets and evaluating whether their empirical variance aligns with theoretical CRB predictions. We demonstrate the framework using arterial spin labeling (ASL) as an illustrative example. Our result shows the commonly used ASL signal model appears to be specified in the brain and moderately misspecified in the kidney. The proposed framework offers a general, theoretically grounded approach for assessing model validity in quantitative MRI.
CLLMate: A Multimodal LLM for Weather and Climate Events Forecasting
Sep 27, 2024
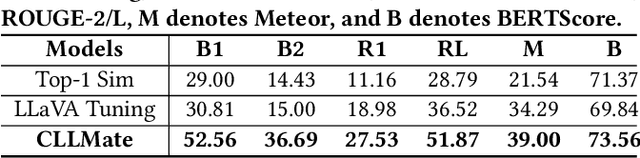

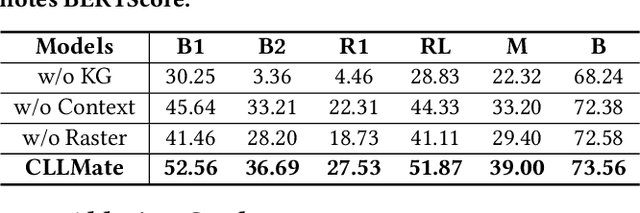
Forecasting weather and climate events is crucial for making appropriate measures to mitigate environmental hazards and minimize associated losses. Previous research on environmental forecasting focuses on predicting numerical meteorological variables related to closed-set events rather than forecasting open-set events directly, which limits the comprehensiveness of event forecasting. We propose Weather and Climate Event Forecasting (WCEF), a new task that leverages meteorological raster data and textual event data to predict potential weather and climate events. However, due to difficulties in aligning multimodal data and the lack of sufficient supervised datasets, this task is challenging to accomplish. Therefore, we first propose a framework to align historical meteorological data with past weather and climate events using the large language model (LLM). In this framework, we construct a knowledge graph by using LLM to extract information about weather and climate events from a corpus of over 41k highly environment-focused news articles. Subsequently, we mapped these events with meteorological raster data, creating a supervised dataset, which is the largest and most novel for LLM tuning on the WCEF task. Finally, we introduced our aligned models, CLLMate (LLM for climate), a multimodal LLM to forecast weather and climate events using meteorological raster data. In evaluating CLLMate, we conducted extensive experiments. The results indicate that CLLMate surpasses both the baselines and other multimodal LLMs, showcasing the potential of utilizing LLM to align weather and climate events with meteorological data and highlighting the promising future for research on the WCEF task.
StuGPTViz: A Visual Analytics Approach to Understand Student-ChatGPT Interactions
Jul 17, 2024



The integration of Large Language Models (LLMs), especially ChatGPT, into education is poised to revolutionize students' learning experiences by introducing innovative conversational learning methodologies. To empower students to fully leverage the capabilities of ChatGPT in educational scenarios, understanding students' interaction patterns with ChatGPT is crucial for instructors. However, this endeavor is challenging due to the absence of datasets focused on student-ChatGPT conversations and the complexities in identifying and analyzing the evolutional interaction patterns within conversations. To address these challenges, we collected conversational data from 48 students interacting with ChatGPT in a master's level data visualization course over one semester. We then developed a coding scheme, grounded in the literature on cognitive levels and thematic analysis, to categorize students' interaction patterns with ChatGPT. Furthermore, we present a visual analytics system, StuGPTViz, that tracks and compares temporal patterns in student prompts and the quality of ChatGPT's responses at multiple scales, revealing significant pedagogical insights for instructors. We validated the system's effectiveness through expert interviews with six data visualization instructors and three case studies. The results confirmed StuGPTViz's capacity to enhance educators' insights into the pedagogical value of ChatGPT. We also discussed the potential research opportunities of applying visual analytics in education and developing AI-driven personalized learning solutions.
Accelerating Representation Learning with View-Consistent Dynamics in Data-Efficient Reinforcement Learning
Jan 18, 2022



Learning informative representations from image-based observations is of fundamental concern in deep Reinforcement Learning (RL). However, data-inefficiency remains a significant barrier to this objective. To overcome this obstacle, we propose to accelerate state representation learning by enforcing view-consistency on the dynamics. Firstly, we introduce a formalism of Multi-view Markov Decision Process (MMDP) that incorporates multiple views of the state. Following the structure of MMDP, our method, View-Consistent Dynamics (VCD), learns state representations by training a view-consistent dynamics model in the latent space, where views are generated by applying data augmentation to states. Empirical evaluation on DeepMind Control Suite and Atari-100k demonstrates VCD to be the SoTA data-efficient algorithm on visual control tasks.
Denoised Internal Models: a Brain-Inspired Autoencoder against Adversarial Attacks
Nov 21, 2021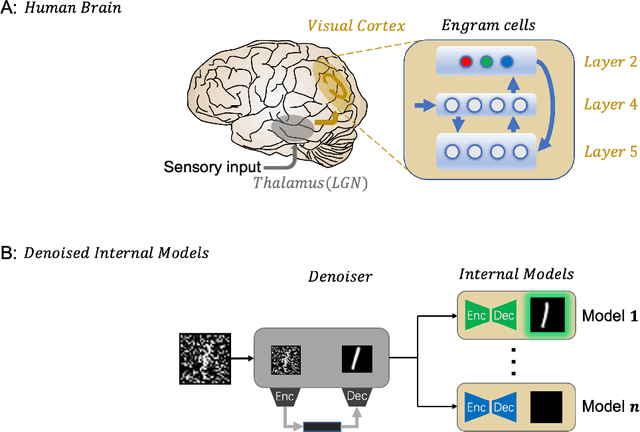
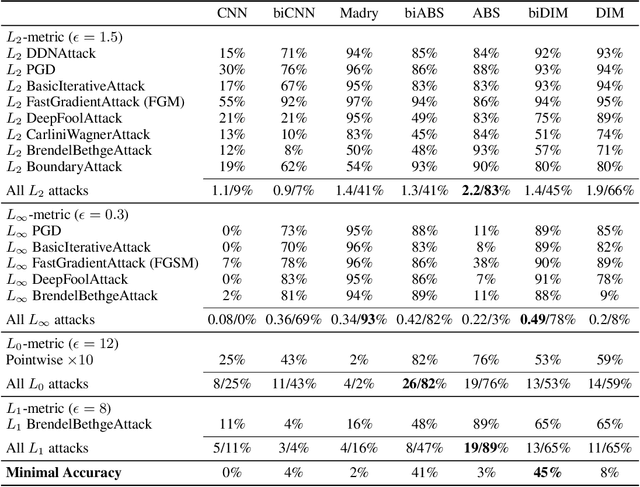
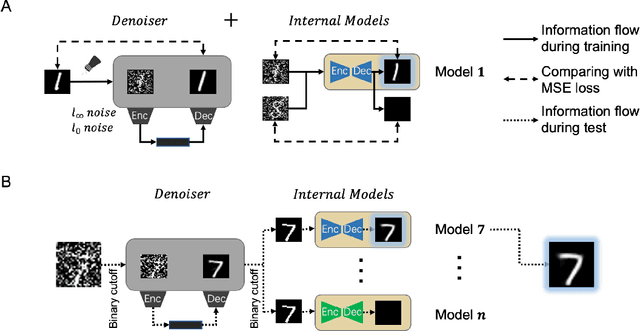
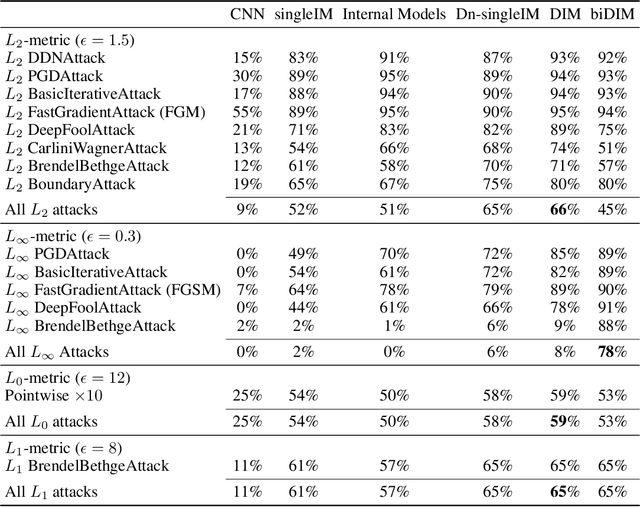
Despite its great success, deep learning severely suffers from robustness; that is, deep neural networks are very vulnerable to adversarial attacks, even the simplest ones. Inspired by recent advances in brain science, we propose the Denoised Internal Models (DIM), a novel generative autoencoder-based model to tackle this challenge. Simulating the pipeline in the human brain for visual signal processing, DIM adopts a two-stage approach. In the first stage, DIM uses a denoiser to reduce the noise and the dimensions of inputs, reflecting the information pre-processing in the thalamus. Inspired from the sparse coding of memory-related traces in the primary visual cortex, the second stage produces a set of internal models, one for each category. We evaluate DIM over 42 adversarial attacks, showing that DIM effectively defenses against all the attacks and outperforms the SOTA on the overall robustness.
EventAnchor: Reducing Human Interactions in Event Annotation of Racket Sports Videos
Jan 14, 2021

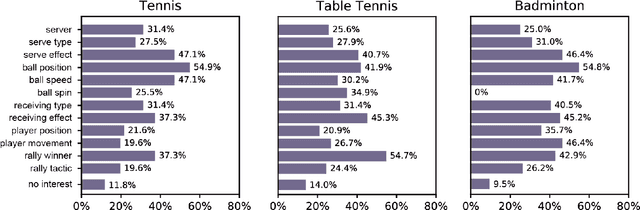
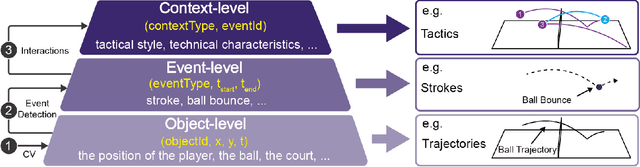
The popularity of racket sports (e.g., tennis and table tennis) leads to high demands for data analysis, such as notational analysis, on player performance. While sports videos offer many benefits for such analysis, retrieving accurate information from sports videos could be challenging. In this paper, we propose EventAnchor, a data analysis framework to facilitate interactive annotation of racket sports video with the support of computer vision algorithms. Our approach uses machine learning models in computer vision to help users acquire essential events from videos (e.g., serve, the ball bouncing on the court) and offers users a set of interactive tools for data annotation. An evaluation study on a table tennis annotation system built on this framework shows significant improvement of user performances in simple annotation tasks on objects of interest and complex annotation tasks requiring domain knowledge.
Parallel ensemble methods for causal direction inference
Jun 05, 2020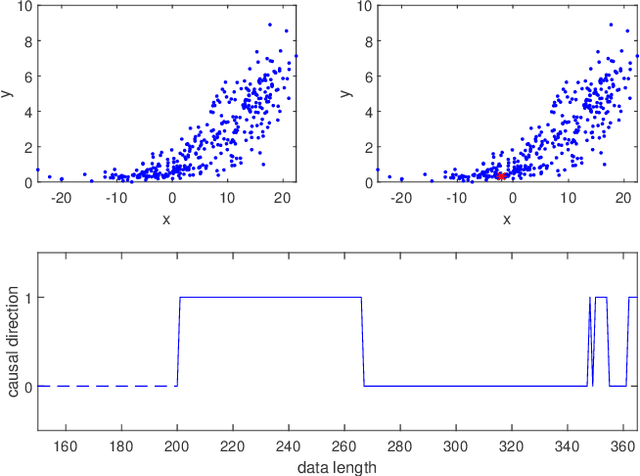
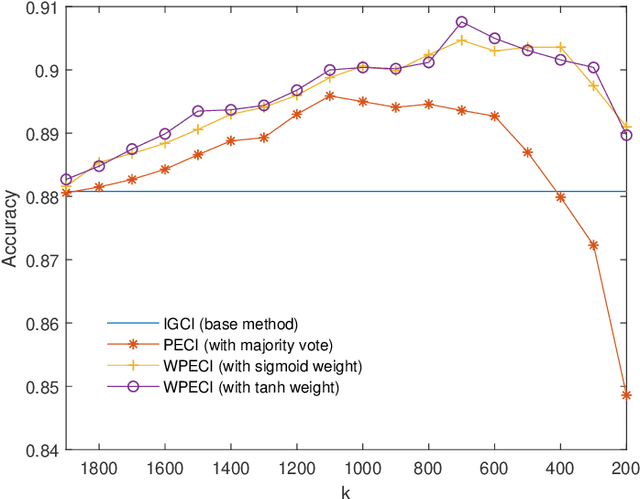
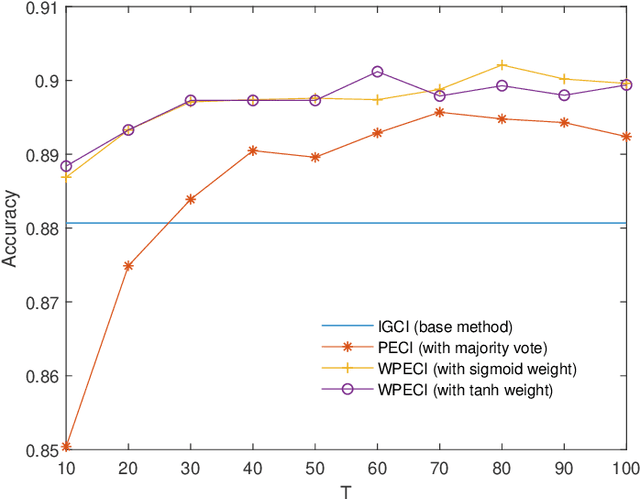
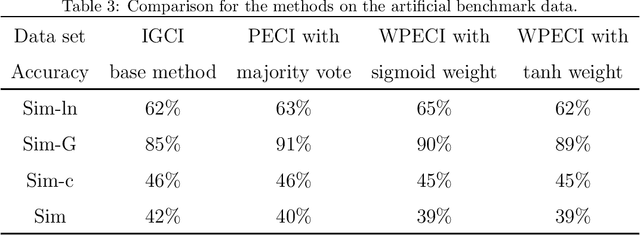
Inferring the causal direction between two variables from their observation data is one of the most fundamental and challenging topics in data science. A causal direction inference algorithm maps the observation data into a binary value which represents either x causes y or y causes x. The nature of these algorithms makes the results unstable with the change of data points. Therefore the accuracy of the causal direction inference can be improved significantly by using parallel ensemble frameworks. In this paper, new causal direction inference algorithms based on several ways of parallel ensemble are proposed. Theoretical analyses on accuracy rates are given. Experiments are done on both of the artificial data sets and the real world data sets. The accuracy performances of the methods and their computational efficiencies in parallel computing environment are demonstrated.
Fully Automatic Liver Attenuation Estimation Combing CNN Segmentation and Morphological Operations
Jun 29, 2019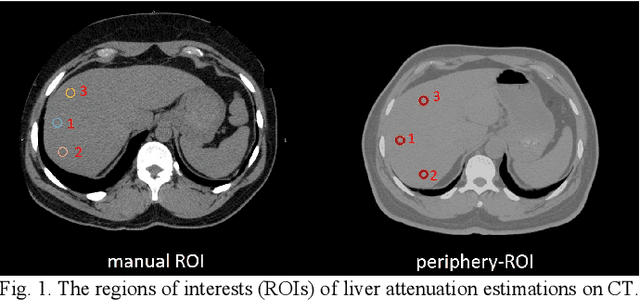
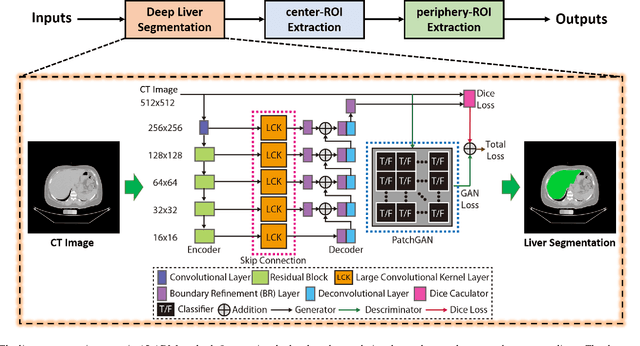
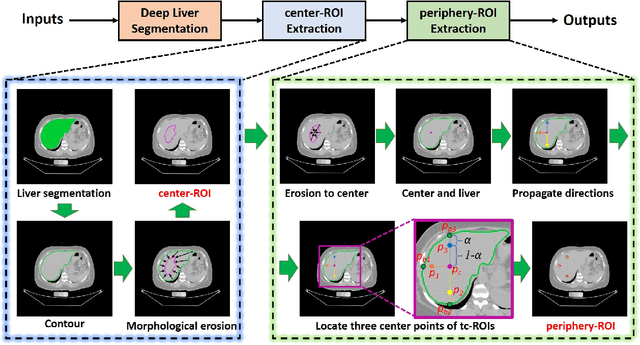
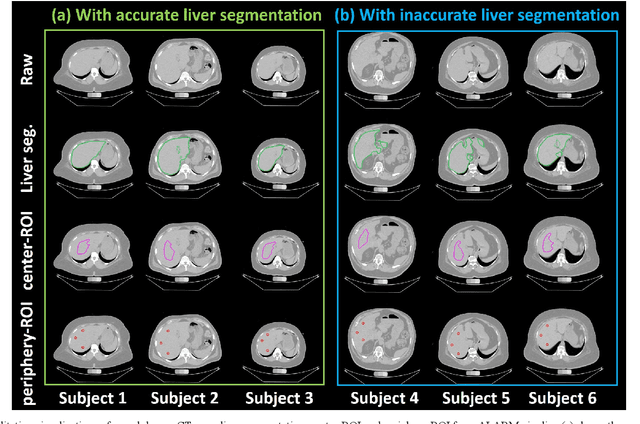
Manually tracing regions of interest (ROIs) within the liver is the de facto standard method for measuring liver attenuation on computed tomography (CT) in diagnosing nonalcoholic fatty liver disease (NAFLD). However, manual tracing is resource intensive. To address these limitations and to expand the availability of a quantitative CT measure of hepatic steatosis, we propose the automatic liver attenuation ROI-based measurement (ALARM) method for automated liver attenuation estimation. The ALARM method consists of two major stages: (1) deep convolutional neural network (DCNN)-based liver segmentation and (2) automated ROI extraction. First, liver segmentation was achieved using our previously developed SS-Net. Then, a single central ROI (center-ROI) and three circles ROI (periphery-ROI) were computed based on liver segmentation and morphological operations. The ALARM method is available as an open source Docker container (https://github.com/MASILab/ALARM).246 subjects with 738 abdomen CT scans from the African American-Diabetes Heart Study (AA-DHS) were used for external validation (testing), independent from the training and validation cohort (100 clinically acquired CT abdominal scans).