 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple yet Effective Graph Distillation via Clustering
May 27, 2025Despite plentiful successes achieved by graph representation learning in various domains, the training of graph neural networks (GNNs) still remains tenaciously challenging due to the tremendous computational overhead needed for sizable graphs in practice. Recently, graph data distillation (GDD), which seeks to distill large graphs into compact and informative ones, has emerged as a promising technique to enable efficient GNN training. However, most existing GDD works rely on heuristics that align model gradients or representation distributions on condensed and original graphs, leading to compromised result quality, expensive training for distilling large graphs, or both. Motivated by this, this paper presents an efficient and effective GDD approach, ClustGDD. Under the hood, ClustGDD resorts to synthesizing the condensed graph and node attributes through fast and theoretically-grounded clustering that minimizes the within-cluster sum of squares and maximizes the homophily on the original graph. The fundamental idea is inspired by our empirical and theoretical findings unveiling the connection between clustering and empirical condensation quality using Fr\'echet Inception Distance, a well-known quality metric for synthetic images. Furthermore, to mitigate the adverse effects caused by the homophily-based clustering, ClustGDD refines the nodal attributes of the condensed graph with a small augmentation learned via class-aware graph sampling and consistency loss. Our extensive experiments exhibit that GNNs trained over condensed graphs output by ClustGDD consistently achieve superior or comparable performance to state-of-the-art GDD methods in terms of node classification on five benchmark datasets, while being orders of magnitude faster.
Cost-Effective Label-free Node Classification with LLMs
Dec 16, 2024



Graph neural networks (GNNs) have emerged as go-to models for node classification in graph data due to their powerful abilities in fusing graph structures and attributes. However, such models strongly rely on adequate high-quality labeled data for training, which are expensive to acquire in practice. With the advent of large language models (LLMs), a promising way is to leverage their superb zero-shot capabilities and massive knowledge for node labeling. Despite promising results reported, this methodology either demands considerable queries to LLMs, or suffers from compromised performance caused by noisy labels produced by LLMs. To remedy these issues, this work presents Cella, an active self-training framework that integrates LLMs into GNNs in a cost-effective manner. The design recipe of Cella is to iteratively identify small sets of "critical" samples using GNNs and extract informative pseudo-labels for them with both LLMs and GNNs as additional supervision signals to enhance model training. Particularly, Cella includes three major components: (i) an effective active node selection strategy for initial annotations; (ii) a judicious sample selection scheme to sift out the "critical" nodes based on label disharmonicity and entropy; and (iii) a label refinement module combining LLMs and GNNs with rewired topology. Our extensive experiments over five benchmark text-attributed graph datasets demonstrate that Cella significantly outperforms the state of the arts under the same query budget to LLMs in terms of label-free node classification. In particular, on the DBLP dataset with 14.3k nodes, Cella is able to achieve an 8.08% conspicuous improvement in accuracy over the state-of-the-art at a cost of less than one cent.
Efficient Topology-aware Data Augmentation for High-Degree Graph Neural Networks
Jun 11, 2024In recent years, graph neural networks (GNNs) have emerged as a potent tool for learning on graph-structured data and won fruitful successes in varied fields. The majority of GNNs follow the message-passing paradigm, where representations of each node are learned by recursively aggregating features of its neighbors. However, this mechanism brings severe over-smoothing and efficiency issues over high-degree graphs (HDGs), wherein most nodes have dozens (or even hundreds) of neighbors, such as social networks, transaction graphs, power grids, etc. Additionally, such graphs usually encompass rich and complex structure semantics, which are hard to capture merely by feature aggregations in GNNs. Motivated by the above limitations, we propose TADA, an efficient and effective front-mounted data augmentation framework for GNNs on HDGs. Under the hood, TADA includes two key modules: (i) feature expansion with structure embeddings, and (ii) topology- and attribute-aware graph sparsification. The former obtains augmented node features and enhanced model capacity by encoding the graph structure into high-quality structure embeddings with our highly-efficient sketching method. Further, by exploiting task-relevant features extracted from graph structures and attributes, the second module enables the accurate identification and reduction of numerous redundant/noisy edges from the input graph, thereby alleviating over-smoothing and facilitating faster feature aggregations over HDGs. Empirically, TADA considerably improves the predictive performance of mainstream GNN models on 8 real homophilic/heterophilic HDGs in terms of node classification, while achieving efficient training and inference processes.
Self-attention Dual Embedding for Graphs with Heterophily
May 28, 2023Graph Neural Networks (GNNs) have been highly successful for the node classification task. GNNs typically assume graphs are homophilic, i.e. neighboring nodes are likely to belong to the same class. However, a number of real-world graphs are heterophilic, and this leads to much lower classification accuracy using standard GNNs. In this work, we design a novel GNN which is effective for both heterophilic and homophilic graphs. Our work is based on three main observations. First, we show that node features and graph topology provide different amounts of informativeness in different graphs, and therefore they should be encoded independently and prioritized in an adaptive manner. Second, we show that allowing negative attention weights when propagating graph topology information improves accuracy. Finally, we show that asymmetric attention weights between nodes are helpful. We design a GNN which makes use of these observations through a novel self-attention mechanism. We evaluate our algorithm on real-world graphs containing thousands to millions of nodes and show that we achieve state-of-the-art results compared to existing GNNs. We also analyze the effectiveness of the main components of our design on different graphs.
Denoised Internal Models: a Brain-Inspired Autoencoder against Adversarial Attacks
Nov 21, 2021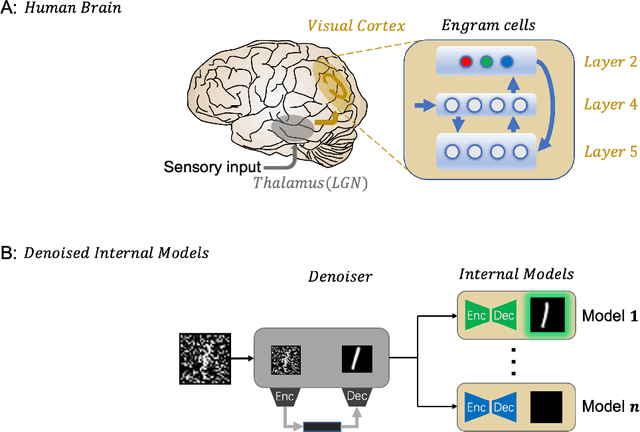
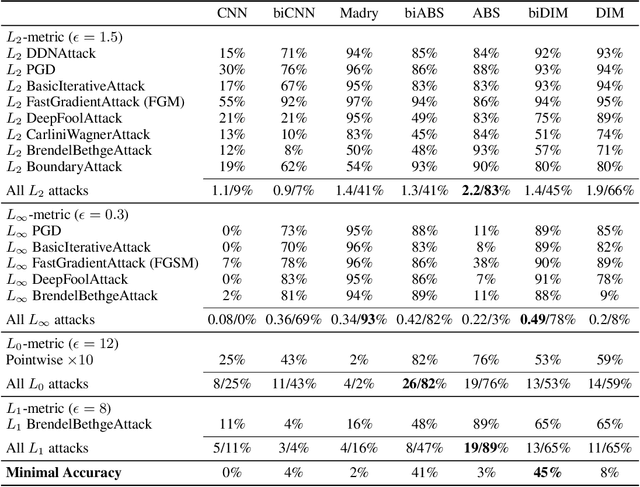
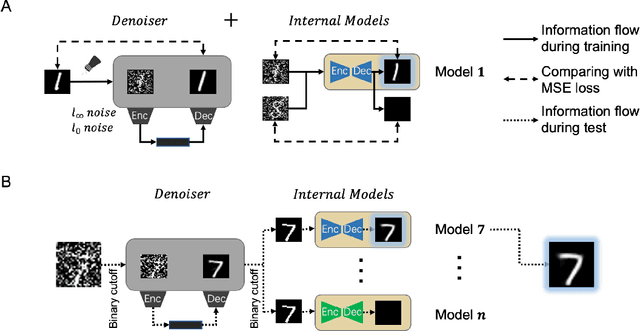
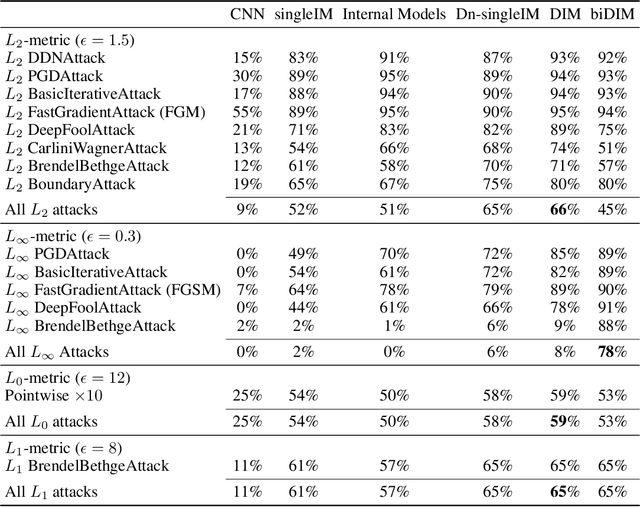
Despite its great success, deep learning severely suffers from robustness; that is, deep neural networks are very vulnerable to adversarial attacks, even the simplest ones. Inspired by recent advances in brain science, we propose the Denoised Internal Models (DIM), a novel generative autoencoder-based model to tackle this challenge. Simulating the pipeline in the human brain for visual signal processing, DIM adopts a two-stage approach. In the first stage, DIM uses a denoiser to reduce the noise and the dimensions of inputs, reflecting the information pre-processing in the thalamus. Inspired from the sparse coding of memory-related traces in the primary visual cortex, the second stage produces a set of internal models, one for each category. We evaluate DIM over 42 adversarial attacks, showing that DIM effectively defenses against all the attacks and outperforms the SOTA on the overall robustness.