 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple yet Effective Graph Distillation via Clustering
May 27, 2025Despite plentiful successes achieved by graph representation learning in various domains, the training of graph neural networks (GNNs) still remains tenaciously challenging due to the tremendous computational overhead needed for sizable graphs in practice. Recently, graph data distillation (GDD), which seeks to distill large graphs into compact and informative ones, has emerged as a promising technique to enable efficient GNN training. However, most existing GDD works rely on heuristics that align model gradients or representation distributions on condensed and original graphs, leading to compromised result quality, expensive training for distilling large graphs, or both. Motivated by this, this paper presents an efficient and effective GDD approach, ClustGDD. Under the hood, ClustGDD resorts to synthesizing the condensed graph and node attributes through fast and theoretically-grounded clustering that minimizes the within-cluster sum of squares and maximizes the homophily on the original graph. The fundamental idea is inspired by our empirical and theoretical findings unveiling the connection between clustering and empirical condensation quality using Fr\'echet Inception Distance, a well-known quality metric for synthetic images. Furthermore, to mitigate the adverse effects caused by the homophily-based clustering, ClustGDD refines the nodal attributes of the condensed graph with a small augmentation learned via class-aware graph sampling and consistency loss. Our extensive experiments exhibit that GNNs trained over condensed graphs output by ClustGDD consistently achieve superior or comparable performance to state-of-the-art GDD methods in terms of node classification on five benchmark datasets, while being orders of magnitude faster.
Cost-Effective Text Clustering with Large Language Models
Apr 22, 2025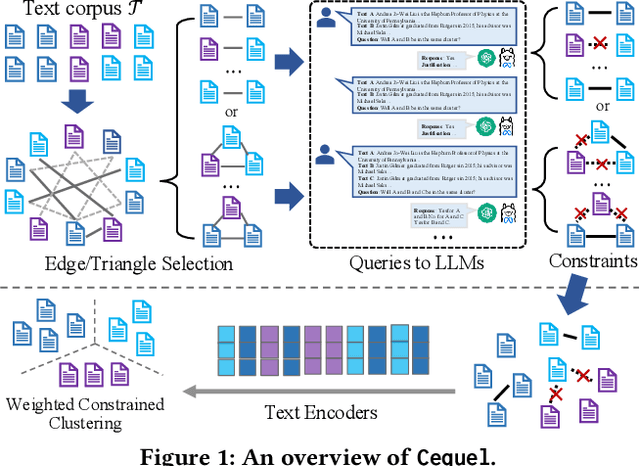

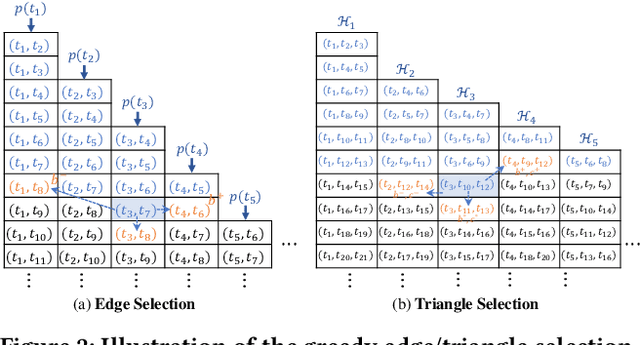
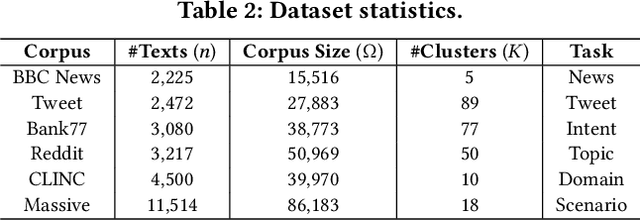
Text clustering aims to automatically partition a collection of text documents into distinct clusters based on linguistic features. In the literature, this task is usually framed as metric clustering based on text embeddings from pre-trained encoders or a graph clustering problem upon pairwise similarities from an oracle, e.g., a large ML model. Recently, large language models (LLMs) bring significant advancement in this field by offering contextualized text embeddings and highly accurate similarity scores, but meanwhile, present grand challenges to cope with substantial computational and/or financial overhead caused by numerous API-based queries or inference calls to the models. In response, this paper proposes TECL, a cost-effective framework that taps into the feedback from LLMs for accurate text clustering within a limited budget of queries to LLMs. Under the hood, TECL adopts our EdgeLLM or TriangleLLM to construct must-link/cannot-link constraints for text pairs, and further leverages such constraints as supervision signals input to our weighted constrained clustering approach to generate clusters. Particularly, EdgeLLM (resp. TriangleLLM) enables the identification of informative text pairs (resp. triplets) for querying LLMs via well-thought-out greedy algorithms and accurate extraction of pairwise constraints through carefully-crafted prompting techniques. Our experiments on multiple benchmark datasets exhibit that TECL consistently and considerably outperforms existing solutions in unsupervised text clustering under the same query cost for LLMs.
Cost-Effective Label-free Node Classification with LLMs
Dec 16, 2024



Graph neural networks (GNNs) have emerged as go-to models for node classification in graph data due to their powerful abilities in fusing graph structures and attributes. However, such models strongly rely on adequate high-quality labeled data for training, which are expensive to acquire in practice. With the advent of large language models (LLMs), a promising way is to leverage their superb zero-shot capabilities and massive knowledge for node labeling. Despite promising results reported, this methodology either demands considerable queries to LLMs, or suffers from compromised performance caused by noisy labels produced by LLMs. To remedy these issues, this work presents Cella, an active self-training framework that integrates LLMs into GNNs in a cost-effective manner. The design recipe of Cella is to iteratively identify small sets of "critical" samples using GNNs and extract informative pseudo-labels for them with both LLMs and GNNs as additional supervision signals to enhance model training. Particularly, Cella includes three major components: (i) an effective active node selection strategy for initial annotations; (ii) a judicious sample selection scheme to sift out the "critical" nodes based on label disharmonicity and entropy; and (iii) a label refinement module combining LLMs and GNNs with rewired topology. Our extensive experiments over five benchmark text-attributed graph datasets demonstrate that Cella significantly outperforms the state of the arts under the same query budget to LLMs in terms of label-free node classification. In particular, on the DBLP dataset with 14.3k nodes, Cella is able to achieve an 8.08% conspicuous improvement in accuracy over the state-of-the-art at a cost of less than one cent.
Intelligent System for Automated Molecular Patent Infringement Assessment
Dec 10, 2024



Automated drug discovery offers significant potential for accelerating the development of novel therapeutics by substituting labor-intensive human workflows with machine-driven processes. However, a critical bottleneck persists in the inability of current automated frameworks to assess whether newly designed molecules infringe upon existing patents, posing significant legal and financial risks. We introduce PatentFinder, a novel tool-enhanced and multi-agent framework that accurately and comprehensively evaluates small molecules for patent infringement. It incorporates both heuristic and model-based tools tailored for decomposed subtasks, featuring: MarkushParser, which is capable of optical chemical structure recognition of molecular and Markush structures, and MarkushMatcher, which enhances large language models' ability to extract substituent groups from molecules accurately. On our benchmark dataset MolPatent-240, PatentFinder outperforms baseline approaches that rely solely on large language models, demonstrating a 13.8\% increase in F1-score and a 12\% rise in accuracy. Experimental results demonstrate that PatentFinder mitigates label bias to produce balanced predictions and autonomously generates detailed, interpretable patent infringement reports. This work not only addresses a pivotal challenge in automated drug discovery but also demonstrates the potential of decomposing complex scientific tasks into manageable subtasks for specialized, tool-augmented agents.
Self-attention Dual Embedding for Graphs with Heterophily
May 28, 2023Graph Neural Networks (GNNs) have been highly successful for the node classification task. GNNs typically assume graphs are homophilic, i.e. neighboring nodes are likely to belong to the same class. However, a number of real-world graphs are heterophilic, and this leads to much lower classification accuracy using standard GNNs. In this work, we design a novel GNN which is effective for both heterophilic and homophilic graphs. Our work is based on three main observations. First, we show that node features and graph topology provide different amounts of informativeness in different graphs, and therefore they should be encoded independently and prioritized in an adaptive manner. Second, we show that allowing negative attention weights when propagating graph topology information improves accuracy. Finally, we show that asymmetric attention weights between nodes are helpful. We design a GNN which makes use of these observations through a novel self-attention mechanism. We evaluate our algorithm on real-world graphs containing thousands to millions of nodes and show that we achieve state-of-the-art results compared to existing GNNs. We also analyze the effectiveness of the main components of our design on different graphs.