 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-efficient Federated Graph Classification via Generative Diffusion Modeling
Jan 22, 2026Graph Neural Networks (GNNs) unlock new ways of learning from graph-structured data, proving highly effective in capturing complex relationships and patterns. Federated GNNs (FGNNs) have emerged as a prominent distributed learning paradigm for training GNNs over decentralized data. However, FGNNs face two significant challenges: high communication overhead from multiple rounds of parameter exchanges and non-IID data characteristics across clients. To address these issues, we introduce CeFGC, a novel FGNN paradigm that facilitates efficient GNN training over non-IID data by limiting communication between the server and clients to three rounds only. The core idea of CeFGC is to leverage generative diffusion models to minimize direct client-server communication. Each client trains a generative diffusion model that captures its local graph distribution and shares this model with the server, which then redistributes it back to all clients. Using these generative models, clients generate synthetic graphs combined with their local graphs to train local GNN models. Finally, clients upload their model weights to the server for aggregation into a global GNN model. We theoretically analyze the I/O complexity of communication volume to show that CeFGC reduces to a constant of three communication rounds only. Extensive experiments on several real graph datasets demonstrate the effectiveness and efficiency of CeFGC against state-of-the-art competitors, reflecting our superior performance on non-IID graphs by aligning local and global model objectives and enriching the training set with diverse graphs.
Inference Attacks Against Graph Generative Diffusion Models
Jan 07, 2026Graph generative diffusion models have recently emerged as a powerful paradigm for generating complex graph structures, effectively capturing intricate dependencies and relationships within graph data. However, the privacy risks associated with these models remain largely unexplored. In this paper, we investigate information leakage in such models through three types of black-box inference attacks. First, we design a graph reconstruction attack, which can reconstruct graphs structurally similar to those training graphs from the generated graphs. Second, we propose a property inference attack to infer the properties of the training graphs, such as the average graph density and the distribution of densities, from the generated graphs. Third, we develop two membership inference attacks to determine whether a given graph is present in the training set. Extensive experiments on three different types of graph generative diffusion models and six real-world graphs demonstrate the effectiveness of these attacks, significantly outperforming the baseline approaches. Finally, we propose two defense mechanisms that mitigate these inference attacks and achieve a better trade-off between defense strength and target model utility than existing methods. Our code is available at https://zenodo.org/records/17946102.
Cost-Effective Text Clustering with Large Language Models
Apr 22, 2025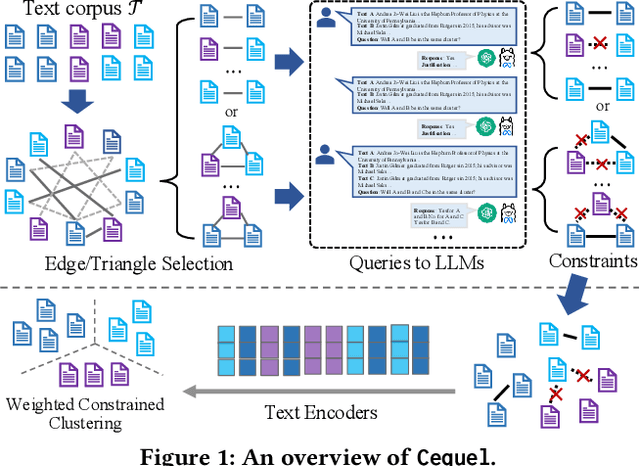

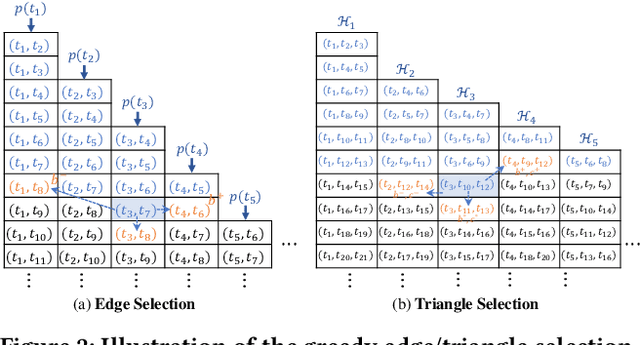
Text clustering aims to automatically partition a collection of text documents into distinct clusters based on linguistic features. In the literature, this task is usually framed as metric clustering based on text embeddings from pre-trained encoders or a graph clustering problem upon pairwise similarities from an oracle, e.g., a large ML model. Recently, large language models (LLMs) bring significant advancement in this field by offering contextualized text embeddings and highly accurate similarity scores, but meanwhile, present grand challenges to cope with substantial computational and/or financial overhead caused by numerous API-based queries or inference calls to the models. In response, this paper proposes TECL, a cost-effective framework that taps into the feedback from LLMs for accurate text clustering within a limited budget of queries to LLMs. Under the hood, TECL adopts our EdgeLLM or TriangleLLM to construct must-link/cannot-link constraints for text pairs, and further leverages such constraints as supervision signals input to our weighted constrained clustering approach to generate clusters. Particularly, EdgeLLM (resp. TriangleLLM) enables the identification of informative text pairs (resp. triplets) for querying LLMs via well-thought-out greedy algorithms and accurate extraction of pairwise constraints through carefully-crafted prompting techniques. Our experiments on multiple benchmark datasets exhibit that TECL consistently and considerably outperforms existing solutions in unsupervised text clustering under the same query cost for LLMs.
SAFT: Structure-aware Transformers for Textual Interaction Classification
Apr 07, 2025Textual interaction networks (TINs) are an omnipresent data structure used to model the interplay between users and items on e-commerce websites, social networks, etc., where each interaction is associated with a text description. Classifying such textual interactions (TIC) finds extensive use in detecting spam reviews in e-commerce, fraudulent transactions in finance, and so on. Existing TIC solutions either (i) fail to capture the rich text semantics due to the use of context-free text embeddings, and/or (ii) disregard the bipartite structure and node heterogeneity of TINs, leading to compromised TIC performance. In this work, we propose SAFT, a new architecture that integrates language- and graph-based modules for the effective fusion of textual and structural semantics in the representation learning of interactions. In particular, line graph attention (LGA)/gated attention units (GAUs) and pretrained language models (PLMs) are capitalized on to model the interaction-level and token-level signals, which are further coupled via the proxy token in an iterative and contextualized fashion. Additionally, an efficient and theoretically-grounded approach is developed to encode the local and global topology information pertaining to interactions into structural embeddings. The resulting embeddings not only inject the structural features underlying TINs into the textual interaction encoding but also facilitate the design of graph sampling strategies. Extensive empirical evaluations on multiple real TIN datasets demonstrate the superiority of SAFT over the state-of-the-art baselines in TIC accuracy.
AdvSGM: Differentially Private Graph Learning via Adversarial Skip-gram Model
Mar 27, 2025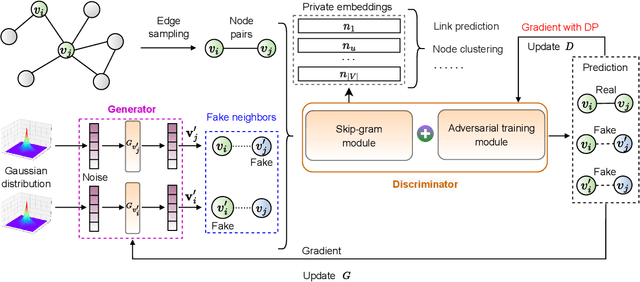
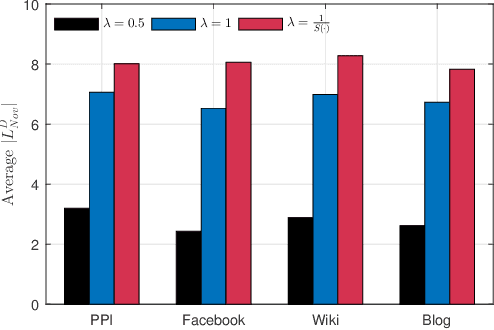
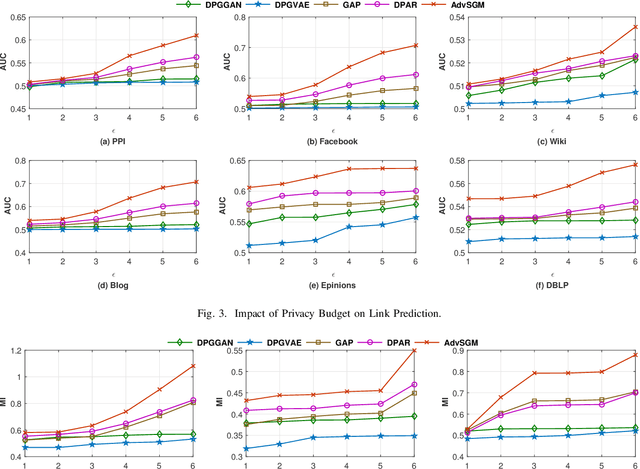
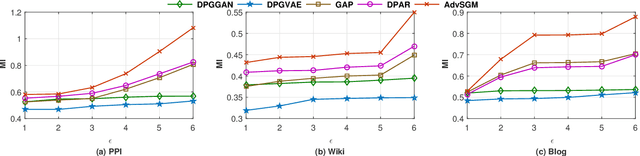
The skip-gram model (SGM), which employs a neural network to generate node vectors, serves as the basis for numerous popular graph embedding techniques. However, since the training datasets contain sensitive linkage information, the parameters of a released SGM may encode private information and pose significant privacy risks. Differential privacy (DP) is a rigorous standard for protecting individual privacy in data analysis. Nevertheless, when applying differential privacy to skip-gram in graphs, it becomes highly challenging due to the complex link relationships, which potentially result in high sensitivity and necessitate substantial noise injection. To tackle this challenge, we present AdvSGM, a differentially private skip-gram for graphs via adversarial training. Our core idea is to leverage adversarial training to privatize skip-gram while improving its utility. Towards this end, we develop a novel adversarial training module by devising two optimizable noise terms that correspond to the parameters of a skip-gram. By fine-tuning the weights between modules within AdvSGM, we can achieve differentially private gradient updates without additional noise injection. Extensive experimental results on six real-world graph datasets show that AdvSGM preserves high data utility across different downstream tasks.
Adaptive Local Clustering over Attributed Graphs
Mar 26, 2025Given a graph $G$ and a seed node $v_s$, the objective of local graph clustering (LGC) is to identify a subgraph $C_s \in G$ (a.k.a. local cluster) surrounding $v_s$ in time roughly linear with the size of $C_s$. This approach yields personalized clusters without needing to access the entire graph, which makes it highly suitable for numerous applications involving large graphs. However, most existing solutions merely rely on the topological connectivity between nodes in $G$, rendering them vulnerable to missing or noisy links that are commonly present in real-world graphs. To address this issue, this paper resorts to leveraging the complementary nature of graph topology and node attributes to enhance local clustering quality. To effectively exploit the attribute information, we first formulate the LGC as an estimation of the bidirectional diffusion distribution (BDD), which is specialized for capturing the multi-hop affinity between nodes in the presence of attributes. Furthermore, we propose LACA, an efficient and effective approach for LGC that achieves superb empirical performance on multiple real datasets while maintaining strong locality. The core components of LACA include (i) a fast and theoretically-grounded preprocessing technique for node attributes, (ii) an adaptive algorithm for diffusing any vectors over $G$ with rigorous theoretical guarantees and expedited convergence, and (iii) an effective three-step scheme for BDD approximation. Extensive experiments, comparing 17 competitors on 8 real datasets, show that LACA outperforms all competitors in terms of result quality measured against ground truth local clusters, while also being up to orders of magnitude faster. The code is available at https://github.com/HaoranZ99/alac.
A Sample-Level Evaluation and Generative Framework for Model Inversion Attacks
Feb 26, 2025Model Inversion (MI) attacks, which reconstruct the training dataset of neural networks, pose significant privacy concerns in machine learning. Recent MI attacks have managed to reconstruct realistic label-level private data, such as the general appearance of a target person from all training images labeled on him. Beyond label-level privacy, in this paper we show sample-level privacy, the private information of a single target sample, is also important but under-explored in the MI literature due to the limitations of existing evaluation metrics. To address this gap, this study introduces a novel metric tailored for training-sample analysis, namely, the Diversity and Distance Composite Score (DDCS), which evaluates the reconstruction fidelity of each training sample by encompassing various MI attack attributes. This, in turn, enhances the precision of sample-level privacy assessments. Leveraging DDCS as a new evaluative lens, we observe that many training samples remain resilient against even the most advanced MI attack. As such, we further propose a transfer learning framework that augments the generative capabilities of MI attackers through the integration of entropy loss and natural gradient descent. Extensive experiments verify the effectiveness of our framework on improving state-of-the-art MI attacks over various metrics including DDCS, coverage and FID. Finally, we demonstrate that DDCS can also be useful for MI defense, by identifying samples susceptible to MI attacks in an unsupervised manner.
Alignment-Aware Model Extraction Attacks on Large Language Models
Sep 04, 2024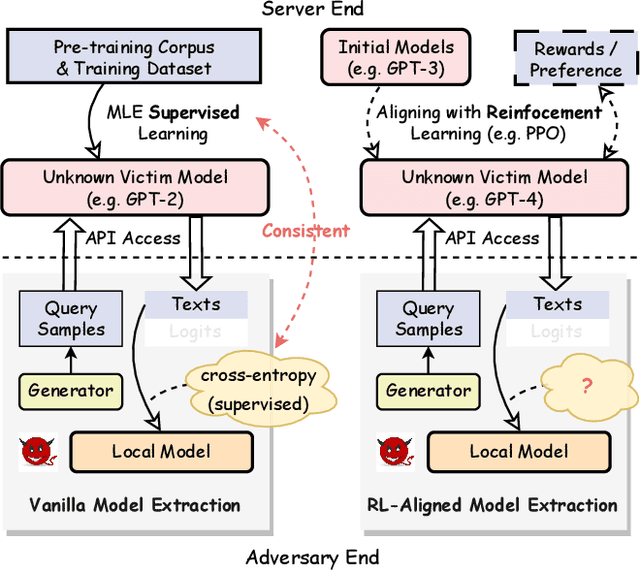
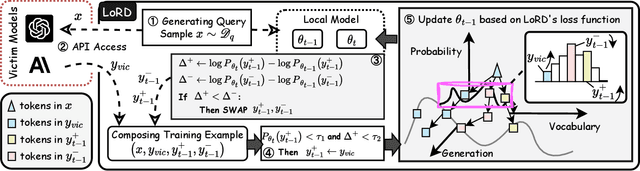
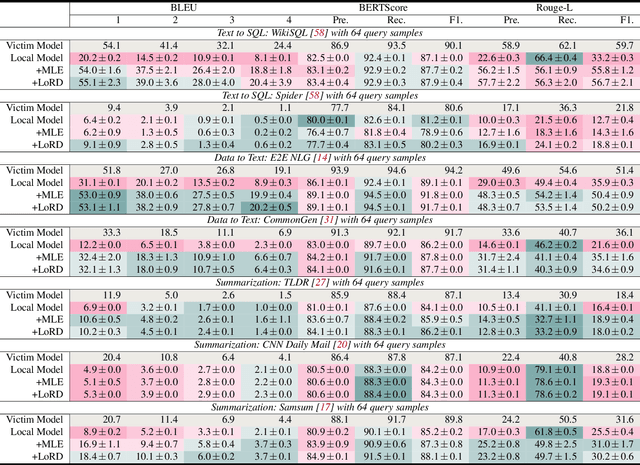
Model extraction attacks (MEAs) on large language models (LLMs) have received increasing research attention lately. Existing attack methods on LLMs inherit the extraction strategies from those designed for deep neural networks (DNNs) yet neglect the inconsistency of training tasks between MEA and LLMs' alignments. As such, they result in poor attack performances. To tackle this issue, we present Locality Reinforced Distillation (LoRD), a novel model extraction attack algorithm specifically for LLMs. In particular, we design a policy-gradient-style training task, which utilizes victim models' responses as a signal to guide the crafting of preference for the local model. Theoretical analysis has shown that i) LoRD's convergence procedure in MEAs is consistent with the alignments of LLMs, and ii) LoRD can reduce query complexity while mitigating watermark protection through exploration-based stealing. Extensive experiments on domain-specific extractions demonstrate the superiority of our method by examining the extraction of various state-of-the-art commercial LLMs.
Decoupling the Class Label and the Target Concept in Machine Unlearning
Jun 12, 2024



Machine unlearning as an emerging research topic for data regulations, aims to adjust a trained model to approximate a retrained one that excludes a portion of training data. Previous studies showed that class-wise unlearning is successful in forgetting the knowledge of a target class, through gradient ascent on the forgetting data or fine-tuning with the remaining data. However, while these methods are useful, they are insufficient as the class label and the target concept are often considered to coincide. In this work, we decouple them by considering the label domain mismatch and investigate three problems beyond the conventional all matched forgetting, e.g., target mismatch, model mismatch, and data mismatch forgetting. We systematically analyze the new challenges in restrictively forgetting the target concept and also reveal crucial forgetting dynamics in the representation level to realize these tasks. Based on that, we propose a general framework, namely, TARget-aware Forgetting (TARF). It enables the additional tasks to actively forget the target concept while maintaining the rest part, by simultaneously conducting annealed gradient ascent on the forgetting data and selected gradient descent on the hard-to-affect remaining data. Empirically, various experiments under the newly introduced settings are conducted to demonstrate the effectiveness of our TARF.
ChatGraph: Chat with Your Graphs
Jan 23, 2024



Graph analysis is fundamental in real-world applications. Traditional approaches rely on SPARQL-like languages or clicking-and-dragging interfaces to interact with graph data. However, these methods either require users to possess high programming skills or support only a limited range of graph analysis functionalities. To address the limitations, we propose a large language model (LLM)-based framework called ChatGraph. With ChatGraph, users can interact with graphs through natural language, making it easier to use and more flexible than traditional approaches. The core of ChatGraph lies in generating chains of graph analysis APIs based on the understanding of the texts and graphs inputted in the user prompts. To achieve this, ChatGraph consists of three main modules: an API retrieval module that searches for relevant APIs, a graph-aware LLM module that enables the LLM to comprehend graphs, and an API chain-oriented finetuning module that guides the LLM in generating API chains.