 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenMAG: A Comprehensive Benchmark for Multimodal-Attributed Graph
Feb 05, 2026Multimodal-Attributed Graph (MAG) learning has achieved remarkable success in modeling complex real-world systems by integrating graph topology with rich attributes from multiple modalities. With the rapid proliferation of novel MAG models capable of handling intricate cross-modal semantics and structural dependencies, establishing a rigorous and unified evaluation standard has become imperative. Although existing benchmarks have facilitated initial progress, they exhibit critical limitations in domain coverage, encoder flexibility, model diversity, and task scope, presenting significant challenges to fair evaluation. To bridge this gap, we present OpenMAG, a comprehensive benchmark that integrates 19 datasets across 6 domains and incorporates 16 encoders to support both static and trainable feature encoding. OpenMAG further implements a standardized library of 24 state-of-the-art models and supports 8 downstream tasks, enabling fair comparisons within a unified framework. Through systematic assessment of necessity, data quality, effectiveness, robustness, and efficiency, we derive 14 fundamental insights into MAG learning to guide future advancements. Our code is available at https://github.com/YUKI-N810/OpenMAG.
Toward Effective Multimodal Graph Foundation Model: A Divide-and-Conquer Based Approach
Feb 04, 2026Graph Foundation Models (GFMs) have achieved remarkable success in generalizing across diverse domains. However, they mainly focus on Text-Attributed Graphs (TAGs), leaving Multimodal-Attributed Graphs (MAGs) largely untapped. Developing Multimodal Graph Foundation Models (MGFMs) allows for leveraging the rich multimodal information in MAGs, and extends applicability to broader types of downstream tasks. While recent MGFMs integrate diverse modality information, our empirical investigation reveals two fundamental limitations of existing MGFMs: (1)they fail to explicitly model modality interaction, essential for capturing intricate cross-modal semantics beyond simple aggregation, and (2)they exhibit sub-optimal modality alignment, which is critical for bridging the significant semantic disparity between distinct modal spaces. To address these challenges, we propose PLANET (graPh topoLogy-aware modAlity iNteraction and alignmEnT), a novel framework employing a Divide-and-Conquer strategy to decouple modality interaction and alignment across distinct granularities. At the embedding granularity, (1)Embedding-wise Domain Gating (EDG) performs local semantic enrichment by adaptively infusing topology-aware cross-modal context, achieving modality interaction. At the node granularity, (2)Node-wise Discretization Retrieval (NDR) ensures global modality alignment by constructing a Discretized Semantic Representation Space (DSRS) to bridge modality gaps. Extensive experiments demonstrate that PLANET significantly outperforms state-of-the-art baselines across diverse graph-centric and multimodal generative tasks.
OptiMAG: Structure-Semantic Alignment via Unbalanced Optimal Transport
Jan 30, 2026Multimodal Attributed Graphs (MAGs) have been widely adopted for modeling complex systems by integrating multi-modal information, such as text and images, on nodes. However, we identify a discrepancy between the implicit semantic structure induced by different modality embeddings and the explicit graph structure. For instance, neighbors in the explicit graph structure may be close in one modality but distant in another. Since existing methods typically perform message passing over the fixed explicit graph structure, they inadvertently aggregate dissimilar features, introducing modality-specific noise and impeding effective node representation learning. To address this, we propose OptiMAG, an Unbalanced Optimal Transport-based regularization framework. OptiMAG employs the Fused Gromov-Wasserstein distance to explicitly guide cross-modal structural consistency within local neighborhoods, effectively mitigating structural-semantic conflicts. Moreover, a KL divergence penalty enables adaptive handling of cross-modal inconsistencies. This framework can be seamlessly integrated into existing multimodal graph models, acting as an effective drop-in regularizer. Experiments demonstrate that OptiMAG consistently outperforms baselines across multiple tasks, ranging from graph-centric tasks (e.g., node classification, link prediction) to multimodal-centric generation tasks (e.g., graph2text, graph2image). The source code will be available upon acceptance.
HIAL: A New Paradigm for Hypergraph Active Learning via Influence Maximization
Jul 28, 2025In recent years, Hypergraph Neural Networks (HNNs) have demonstrated immense potential in handling complex systems with high-order interactions. However, acquiring large-scale, high-quality labeled data for these models is costly, making Active Learning (AL) a critical technique. Existing Graph Active Learning (GAL) methods, when applied to hypergraphs, often rely on techniques like "clique expansion," which destroys the high-order structural information crucial to a hypergraph's success, thereby leading to suboptimal performance. To address this challenge, we introduce HIAL (Hypergraph Active Learning), a native active learning framework designed specifically for hypergraphs. We innovatively reformulate the Hypergraph Active Learning (HAL) problem as an Influence Maximization task. The core of HIAL is a dual-perspective influence function that, based on our novel "High-Order Interaction-Aware (HOI-Aware)" propagation mechanism, synergistically evaluates a node's feature-space coverage (via Magnitude of Influence, MoI) and its topological influence (via Expected Diffusion Value, EDV). We prove that this objective function is monotone and submodular, thus enabling the use of an efficient greedy algorithm with a formal (1-1/e) approximation guarantee. Extensive experiments on seven public datasets demonstrate that HIAL significantly outperforms state-of-the-art baselines in terms of performance, efficiency, generality, and robustness, establishing an efficient and powerful new paradigm for active learning on hypergraphs.
Does Low Rank Adaptation Lead to Lower Robustness against Training-Time Attacks?
May 19, 2025Low rank adaptation (LoRA) has emerged as a prominent technique for fine-tuning large language models (LLMs) thanks to its superb efficiency gains over previous methods. While extensive studies have examined the performance and structural properties of LoRA, its behavior upon training-time attacks remain underexplored, posing significant security risks. In this paper, we theoretically investigate the security implications of LoRA's low-rank structure during fine-tuning, in the context of its robustness against data poisoning and backdoor attacks. We propose an analytical framework that models LoRA's training dynamics, employs the neural tangent kernel to simplify the analysis of the training process, and applies information theory to establish connections between LoRA's low rank structure and its vulnerability against training-time attacks. Our analysis indicates that LoRA exhibits better robustness to backdoor attacks than full fine-tuning, while becomes more vulnerable to untargeted data poisoning due to its over-simplified information geometry. Extensive experimental evaluations have corroborated our theoretical findings.
Rethinking Graph Out-Of-Distribution Generalization: A Learnable Random Walk Perspective
May 09, 2025Out-Of-Distribution (OOD) generalization has gained increasing attentions for machine learning on graphs, as graph neural networks (GNNs) often exhibit performance degradation under distribution shifts. Existing graph OOD methods tend to follow the basic ideas of invariant risk minimization and structural causal models, interpreting the invariant knowledge across datasets under various distribution shifts as graph topology or graph spectrum. However, these interpretations may be inconsistent with real-world scenarios, as neither invariant topology nor spectrum is assured. In this paper, we advocate the learnable random walk (LRW) perspective as the instantiation of invariant knowledge, and propose LRW-OOD to realize graph OOD generalization learning. Instead of employing fixed probability transition matrix (i.e., degree-normalized adjacency matrix), we parameterize the transition matrix with an LRW-sampler and a path encoder. Furthermore, we propose the kernel density estimation (KDE)-based mutual information (MI) loss to generate random walk sequences that adhere to OOD principles. Extensive experiment demonstrates that our model can effectively enhance graph OOD generalization under various types of distribution shifts and yield a significant accuracy improvement of 3.87% over state-of-the-art graph OOD generalization baselines.
Rethinking Graph Structure Learning in the Era of LLMs
Mar 27, 2025



Recently, the emergence of large language models (LLMs) has prompted researchers to explore the integration of language descriptions into graphs, aiming to enhance model encoding capabilities from a data-centric perspective. This graph representation is called text-attributed graphs (TAGs). A review of prior advancements highlights that graph structure learning (GSL) is a pivotal technique for improving data utility, making it highly relevant to efficient TAG learning. However, most GSL methods are tailored for traditional graphs without textual information, underscoring the necessity of developing a new GSL paradigm. Despite clear motivations, it remains challenging: (1) How can we define a reasonable optimization objective for GSL in the era of LLMs, considering the massive parameters in LLM? (2) How can we design an efficient model architecture that enables seamless integration of LLM for this optimization objective? For Question 1, we reformulate existing GSL optimization objectives as a tree optimization framework, shifting the focus from obtaining a well-trained edge predictor to a language-aware tree sampler. For Question 2, we propose decoupled and training-free model design principles for LLM integration, shifting the focus from computation-intensive fine-tuning to more efficient inference. Based on this, we propose Large Language and Tree Assistant (LLaTA), which leverages tree-based LLM in-context learning to enhance the understanding of topology and text, enabling reliable inference and generating improved graph structure. Extensive experiments on 10 TAG datasets demonstrate that LLaTA enjoys flexibility - incorporated with any backbone; scalability - outperforms other LLM-based GSL methods in terms of running efficiency; effectiveness - achieves SOTA performance.
Alignment-Aware Model Extraction Attacks on Large Language Models
Sep 04, 2024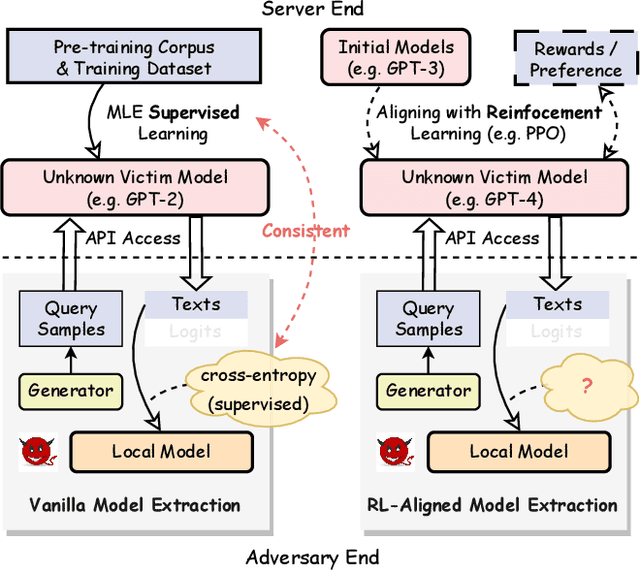
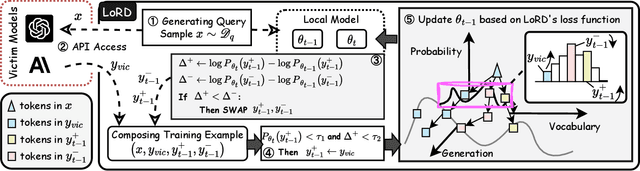
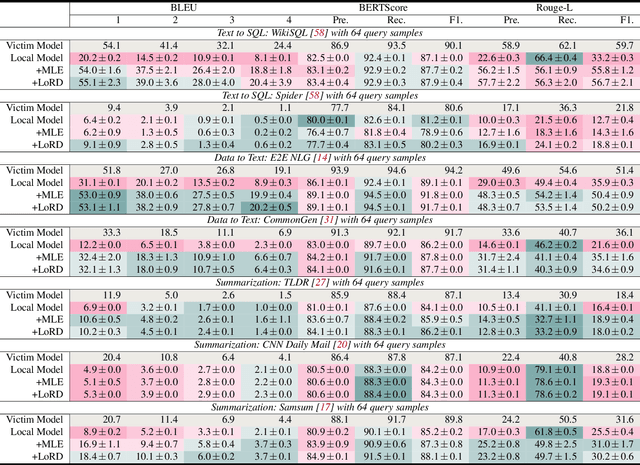
Model extraction attacks (MEAs) on large language models (LLMs) have received increasing research attention lately. Existing attack methods on LLMs inherit the extraction strategies from those designed for deep neural networks (DNNs) yet neglect the inconsistency of training tasks between MEA and LLMs' alignments. As such, they result in poor attack performances. To tackle this issue, we present Locality Reinforced Distillation (LoRD), a novel model extraction attack algorithm specifically for LLMs. In particular, we design a policy-gradient-style training task, which utilizes victim models' responses as a signal to guide the crafting of preference for the local model. Theoretical analysis has shown that i) LoRD's convergence procedure in MEAs is consistent with the alignments of LLMs, and ii) LoRD can reduce query complexity while mitigating watermark protection through exploration-based stealing. Extensive experiments on domain-specific extractions demonstrate the superiority of our method by examining the extraction of various state-of-the-art commercial LLMs.