 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment-Aware Model Extraction Attacks on Large Language Models
Paper and Code
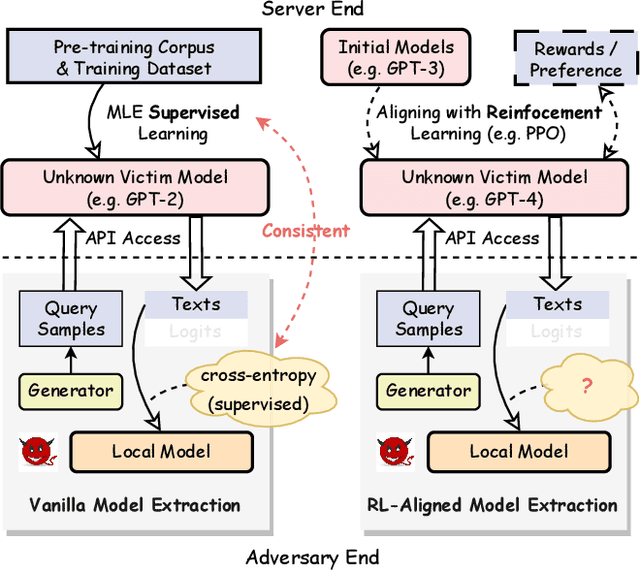
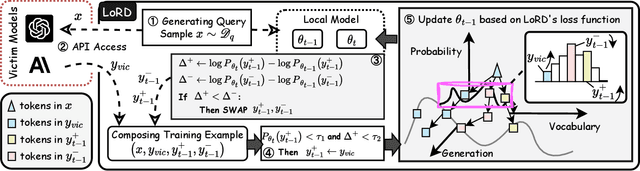
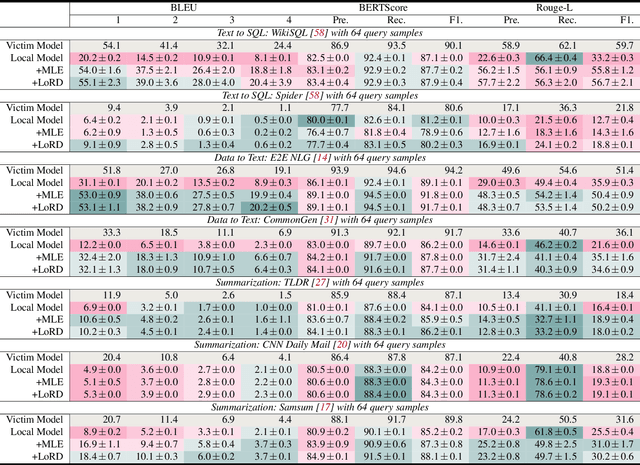
Model extraction attacks (MEAs) on large language models (LLMs) have received increasing research attention lately. Existing attack methods on LLMs inherit the extraction strategies from those designed for deep neural networks (DNNs) yet neglect the inconsistency of training tasks between MEA and LLMs' alignments. As such, they result in poor attack performances. To tackle this issue, we present Locality Reinforced Distillation (LoRD), a novel model extraction attack algorithm specifically for LLMs. In particular, we design a policy-gradient-style training task, which utilizes victim models' responses as a signal to guide the crafting of preference for the local model. Theoretical analysis has shown that i) LoRD's convergence procedure in MEAs is consistent with the alignments of LLMs, and ii) LoRD can reduce query complexity while mitigating watermark protection through exploration-based stealing. Extensive experiments on domain-specific extractions demonstrate the superiority of our method by examining the extraction of various state-of-the-art commercial LLMs.